索引
用索引的原因是大部分时候读的要比写的多,因此对查询语句的优化会非常的重要,要加速查询,就必须用到索引
索引在MYSQL中也叫”键”,是存储引擎用于快速找到记录的一种数据结构,尤其是当表中数据量越来越大时,索引对于性能的影响愈发重要.
primary key 既有索引又有加速,而且必须要有主键
unique key 索引功能外还有约束作用
index key 主要加速查询功能
Select id,name from s1 where id =10;
索引加在哪,就用那进行查的时候才会用的上,如果用别的查就用不上索引
所用字段都加上索引,虽然查找速度都会很快,但是表内新插一条内容io就会飙到100%,写的速度会非常的慢,每写入一次,都要更新一次索引,索引都是在硬盘中,写一条语句硬盘就会发生大量的变化.
所以索引不能过多,应用程序可能会收到影响,而索引太少,对查询性能又会产生影响.
索引的本质:
就是不断的缩小范围,提升查询速度,没有索引之前可以漫无目的查,但是有了索引以后都会先按照索引进行查询.
索引的数据结构:
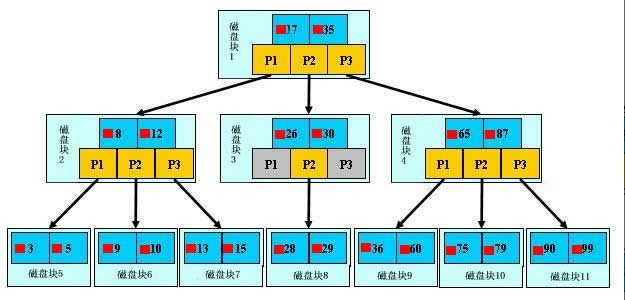
有索引的情况下,都是从树根开始,最开始是树根,然后下去是树枝,最后是叶子,每一个节点就是一个磁盘块,每一次IO就是一块磁盘块,从硬盘里读出,深蓝色的是数据项,黄色的是指针.叶子节点是真正存放表的数据,其他都是虚拟算出的数据为了对应关系.(放的位置是硬盘上)
当id查找时,会先读入id字段根节点读到内存,1个节点,然后用二分法,看是数据项的那边,然后对应指针位置,到下一个磁盘块,后面再多磁盘块也不用管.然后再对照磁盘块,根据指针对应的读入IO就能找到.
(一个磁盘块的大小是固定的,所以要占空间小的字段加索引)
聚集索引:
主键 用表的类型是innodb表就必须要主键(在存储引擎,有两个表,一个是.ibd表数据文件(有数据也有索引的文件,索引组织表,会以字段为基准自动建好树形结构),一个是.frm表结构文件)(不主动设置主键,会自动从上往下找一个不为空且唯一的字段当主键,不然就用隐藏字段当主键)
id字段为主键,用id字段查的时候会非常快,直接是跟其同一行内容信息相绑定,用聚集索引查其他内容,找的也会非常快.
辅助索引 聚集索引以外的索引都是辅助索引,叶子界面只放索引的值与这个值所在对应记录的主键值(id编号) 在本层界面直接拿到想要的值为覆盖索引,在叶子界面拿到想要的结果就是覆盖索引,效果是最好的,比方说索引为age直接找age那么这个效果就是最好的. 如果是回表操作那么效率就没有覆盖的高,索引为age找的是name,那么需要找到age后根据他对应的主键,再走一遍聚集索引,虽然比无索引的要快但是整体算慢的.
Explain 查看sql语句的运行计划,能看出运行多少条才能找到自己需要的
用select count(*) from s1; 可以屏蔽打印的时间显示条数
Select count(id) from s1 where id=100
Create index idx_id on s1(id) 创建索引 速度查看快
Drop index idx_id on s1;删除索引
应对哪些字段做索引:
1、应该对区分度高的字段做索引
2、应该对数据空间量较小字段做索引
3、索引字段不要参与运算
联合索引 将索引全部放在一起,然后按照索引速度快到慢的方式排序