原创不易,求分享、求一键三连
之前说过IM系统的一些优化,但是在网络上传输数据对于数据的流化和反流化也是处理异常情况的重点环节,不处理好可能会出现一些消息发送成功,但是解析失败的情况,本文就带大家来一起了解消息流化中经常遇到的问题以及如何规避。
什么是流化
我们用到的“流化”这个词和我们常用的“序列化”类似,序列化指将一个对象的实例转换成二进制串或文本串的格式,以方便本地保存或者异地传输。
信息流化的目的也是为了形成二进制串的格式方便网络传输,可以说“流化”就是“序列化”,两者没有本质的区别。
在网络通信之前,先流化需要发送的消息成二进制,进行网络传输,另外节点收到二进制数据之后,进行反流化解析出消息内容来进行通讯。
黏包问题
在进行TCP socket通讯时经常会使用自定义字节流,原因是因为TCP通讯如同水流一样,没有明确的拆分规则,TCP粘包、拆包属于网络底层问题,在数据链路层、网络层、传输层都可能出现。出现粘包常见的几点:
- 要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。
- 待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包
- 发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包
- 接收数据端的应用层没有及时读取接受缓冲区中的数据,将会发生粘包。
以上的数据包发送的不确定性,为了数据能够正常解析,在业务层面需要将源源不断的数据流进行拆分或者合并通常用的方法:
- 发送数据是先定义本给数据包的长度的包头,然后发送对应内容,通常自定义字节流包格式
- 发送端将每个数据包封装为固定长度(不够的可以通过补0填充)
- 可以在数据包之间设置边界,如添加特殊符号,将不同的数据包拆分开
除了上面说到的问题,数据传输中也存在很多不同系统语言和平台的差异的问题,因为在各种基本的数据类型中,将平台上的基础类型转化为二进制流,然后将流转化成接收的机器上的数据类型,如果机器不一样就会存在字节排序的差异、数据字节大小、数据表示和数据对准的方式等问题,经常会遇到的问题:
- 流数据在64位操作系统与32位操作系统之间的兼容
- 流数据中字符串的编解码方式不同的影响
- 流数据在不同编程语言之间 java 和c 之间的兼容问题;我们分别来看这些常见的问题如何处理才能解决
Little Endian与Big Endian
Little Endian 和Big Endian是表示计算机字节顺序的两种格式,所谓的字节顺序指的是长度跨度多个字节的数据的存放形式。Little Endian是把低字节存放在内存的低位,而Big Endian将低字节存放在内存的高位。
为什么会有Little Endian 和Big Endian?要是都统一成一个就好了。
在计算机系统中,我们是以字节为单位的,每个地址单元都对应着1个字节,1个字节为8bit。但是在除了8bit的char之外,还有16bit的short型,32bit的long型等。
另外对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于1个字节,那么必然存在一个如果将多个字节排列的问题,因此就导致了Little Endian和Big Endian两种存储模式。
我们网络传输上,TCP/IP协议规定了必须使用网络字节顺序(Big Endian模式),而大多数的PC机上采用了Little Endian模式。所以我们就会注意字节序列兼容的问题 对跨机器通讯有什么影响呢,最小内存单元8位 一个字节。
例如:对4字节的整形数据1247752720 ,其16进制表示0x4a5f3210,低位是0x10, 最高位0x4a,假设存放这个整形的内存单元0x10000100, 终止地址0x10000103,那么32位的Little Endian系统中,该整形内存存储如下:
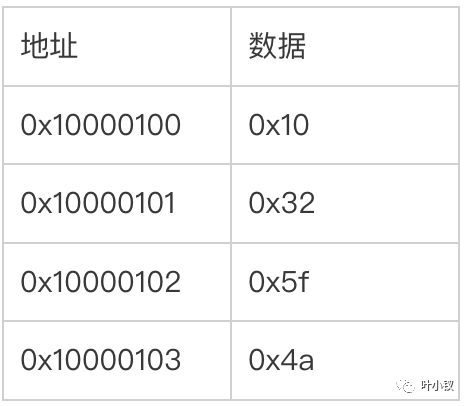
但是32位的Big Endian体系中,却存放如下:
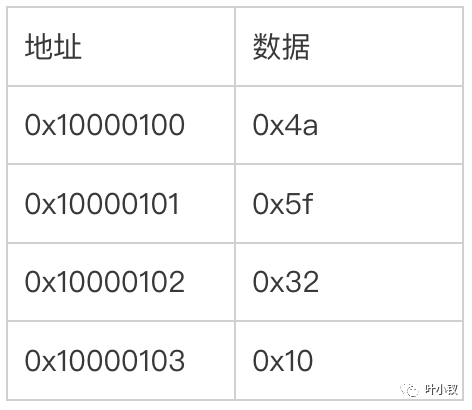
所以,流数据在不同的平台之间传输时,一定要考虑Little Endian和Big Endian的问题,不然传输的数据字节序列就会解析错误。
32位与64位机器
操作系统兼容是流数据传输中平台无关的另一个重要问题。我们知道在32位和64位机器上,同一类型的变量的字节长度可能是不一样的。比如long 型的变量,在32位机器上是4字节,但在64位机器上却是8个字节。
因此,如果一个64位机器上的long型变量流化后,传输到32位机器上时,采用long型来接收和解释,必然失败,并且可能导致整个流数据的解析失败。
对该类问题的解决方式,一般采用这样的方法:无论是32位机器还是64位机器上,我们都统一规定long型的变量只代表4字节的整形数,无论发送、传输、接收都严格按照这个标准;在语言之间也存在long型差异,c语言中long是4字节,java的long型是8字节。这也需要采用同样的方式来解决。
UTF8 与UTF16的转换
这个问题来源于不同的编程语言,其对字符串的编码的规则不同。
C/C++ 语言,一般采用UTF-8编码,比如中文采用UTF-8一般1~3个字节表示一个字符;如java语言,其内部编码一般时UTF-16;统一以2个字节表示一个字符;在Win平台下的VC++ 采用的wchar来存在一个字符,其实就是UTF-16; 上面已经说过如果出现多个字节的数据,就会有Little Endian 和Big Endian的问题。
解决这种问题最好的方式统一编码 要么统一使用UTF-8 要么统一使用UTF-16 另外还有种方式来解决编码的问题也比较常用,使用BASE64 编解码;
Base64算法可以解决中文编码?
Base64是一种二进制到文本的编码方式。它是一种将byte数组编码为字符串的方法,而且编码出的字符串只包含ASCII基础字符串。基于Base64编码的文本只包含了64个ASCII码字符:
- A-Z 26个
- a-z 26个
- 0-9 10个
- 1个
- / 1个 正好64 个字符
使用ASCII码1个码一个字节就能表示,就不存在多个字节情况,所以经过编码的中文字符串,都是一个单字节的序列,不存在多个字节表示一个码,所以传输的过程中就不需要考虑Little Endian 和Big Endian的转化问题。
总结
无论多复杂的消息类型最终要做消息流化都会落到基本的数据类型:数值型、整型、浮点型、双浮点型数据与长整形数、字符串型;做好基础类型占用字节统一和大小端处理,解析消息就会更流畅。
好了,今天的分享就到这。如果本文对你有帮助的话,欢迎点赞&评论&在看&分享,这对我非常重要,感谢。
想要更多交流可以加我微信:
