0.PTA得分截图

1.本周学习总结
1.1总结树及串内容
串的BFKMP算法
1.BF算法
基本思想:
从主串S的第一个字符开始和模式T的第一个字符进行比较,若相等,则继续比较两者的后续字符;若不相等,则从主串S的第二个字符开始和模式T的第一个字符进行比较,重复上述过程,若T中的字符全部比较完毕,则说明本趟匹配成功;若最后一轮匹配的起始位置是n-m, 则主串S中剩下的字符不足够匹配整个模式T,匹配失败。这个算法称为朴素的模式匹配算法,简称BF算法。
时间复杂度O(M*N)
代码如下:
int index(SqString s,SqStringt)
int i=0, j=0;
while (i<s.length && j<t.length)
{
if (s.data[j]==t.data[j]) //继续匹配下一个字符
{
i++; //主串和子串依次匹配下一个字符
j++;
}
else //主串、子串指针回溯重新开始下一次匹配
{
i=i-j+1; //主串从下一个位置开始匹配
j=0; //子串从头开始匹配
}
if j>=t.length)
return(i-t.length); //返回匹配的第一个字符的下标
else
return(-1); //模式匹配不成功
}
2.KMP算法
基本思想:
- 在串S和串T中分别设比较的起始下标i和j;
2.循环直到S中所剩字符长度小于T的长度或T中所有字符均比较完毕
2.1 如果S[i]=T[j], 则继续比较S和T的下- -个字符;否则
2.2将j向右滑动到next[j]位置,即j=next[j];
2.3如果j=0,则将i和j分别加1,准备下一趟比较;
2.4如果T中所有字符均比较完毕,则返回匹配的起始下标;否则返回0;
时间复杂度O(M+N)
代码如下:
int KMPIndex (SqString s,SqString t)
{
int next [MaxSize],i=0,j=0;
GetNext (t,next) ;
while (i<s.1ength && j<t. 1ength)
{
if (j==-1|| s. data[i]== =t.data[j] )
{ i++;
j++; //i, j各增1
}
else j=next[j]; //i不变, j后退
}
if (j>=t. 1ength)
return (i-t. length); //匹配模式串首字符下标
else
return(-1); //返回不匹配标志
}
next数组代码如下:
void GetNext(SqString t,int next)
{
int j, k;
j=0; k=-1;
next[0|=-l;
while (j<t.length-l)
{
if (k=-l || t.data[j]=t.data[kl)
{
j++; k++;
next[j]=k;
}
else k=next[k];
}
}
二叉树的存储结构
1.顺序结构
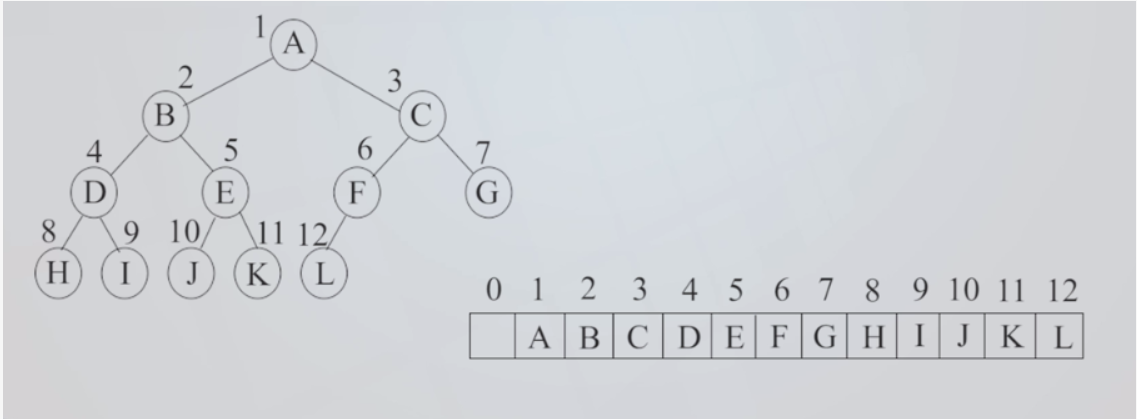
顺序存储一棵二叉树时,首先对该树中的每个结点进行编号,然后以各结点的编号为下标,把各结点的值对应存储到一个一位数组中。每个结点的编号与等深度的满二叉树中对应结点的编号相等,即树根结点的编号为1,接着按照从上到下和从左到右的次序,若一个结点的编号为i,则左、右孩子的编号分别为2i和2i+1
2.链式结构

在二叉树的链式存储中,通常采用的方法是,在每个结点中设置3个域:值域、左指针域和右指针域。其结点结构为:

typedef struct BTNode
{
ElemType data;
struct BTNode *lchild, rchild;
}BTNode,BTree;
二叉树的建法
前序递归建树
BTree CreatBTree(string s,int &i) //前序序列s,i为字符的下标
{
BTree bt;
if (i==s.size()||s[i] == '#') //超过s长度或为空结点返回NULL
{
return NULL;
}
bt = new BNode;
bt->data = s[i];
bt->lchild = CreatBTree(s,++i);
bt->rchild = CreatBTree(s,++i);
return bt;
}
层次法建树
void CreateBTree(BTree &BT,string str)
{ BTree T;int i=0;
queue<BTree> Q;
if( str[0]!='0' )
{
BT =new BTNode;
BT->data = str[0];
BT->lchild=BT->rchild=NULL;
Q.push(BT);
}
else BT=NULL;
while( !Q.empty())
{
T = Q.front();
Q.pop();
i++;
if(str[i]=='0' ) T->lchild = NULL;
else
{
T->lchild = new BTNode;
T->lchild->data = str[i];
T->lchild->lchild=T->lchild->rchild=NULL;
Q.push(T->lchild);
}
i++;
if(str[i]=='0') T->rchild = NULL;
else
{
T->rchild = new BTNode;;
T->rchild->data = str[i];
T->rchild->lchild=T->rchild->rchild=NULL;
Q.push(T->rchild);
}
}
}
前序和中序序列创建二叉树
BTree CreatBTree(char* pre, char* in, int n) //前序序列用数组pre存储,中序序列用数组in存储
{
BTree bt;
int k;
char* p;
if (n <= 0) return NULL;
bt = new BTNode;
bt->data = *pre; //根节点位置
for (p = in; p < in + n; p++)
{
if (*p == *pre) break;
}
k = p - in;
bt->lchild = CreatBTree(pre + 1, in, k);
bt->rchild = CreatBTree(pre + k + 1, p + 1, n - k - 1);
return bt;
}
后序和中序序列创建二叉树
BTRee CreateBT2(char *post,char *in,int n)
{
BTNode *s; char *p; int k;
if(n<=0) return NULL;
s=new BTNode;//创建节点
s->data=*(post+n-1);//构造根节点。
for (p=in;p<in+n;p++)//在中序中找为*ppos的位置k
if (*p==*(post+n-1))
break;
k=p-in;
s->lchild=CreateBT2(post,in,k); //构造左子树
s->rchild=CreateBT2(post+k,p+1,n-k-1);//构造右子树
return S;
}
二叉树的遍历
1.先序遍历
void PreOrder(BTree bt)
{ if (bt!=NULL)
{ printf("%c ",bt->data);
PreOrder(bt->lchild);
PreOrder(bt->rchild);
}
}
2.中序遍历
void InOrder(BTree bt)
{ if (bt!=NULL)
{ InOrder(bt->lchild);
printf("%c ",bt->data);
InOrder(bt->rchild);
}
}
3.后续遍历
void PostOrder(BTree bt)
{ if (bt!=NULL)
{ PostOrder(bt->lchild);
PostOrder(bt->rchild);
printf("%c ",bt->data);
}
}
4.层次遍历
void LevelOrder(BTree Bt)
{
queue<BTree>Q;//队列
int flag = 1;
if (Bt == NULL)
{
cout << "NULL";
return;
}
Q.push(Bt);
while (!Q.empty())
{
if (Q.front())
{
if (flag)
{
flag = 0;
}
else
{
cout << ' ';
}
cout << Q.front()->data;
Q.push(Q.front()->lchild);
Q.push(Q.front()->rchild);
}
Q.pop();
}
}
二叉树的应用
7-3 jmu-ds-二叉树叶子结点带权路径长度和 (25分)
#include<iostream>
#include<string>
using namespace std;
typedef struct node
{
char data;
struct node* lchild, * rchild;
}BTNode;
typedef struct node* BTree;
BTree CreateBTree(string str, int i);
void WPL(BTree bt, int h, int &wpl);
int len;
int main()
{
BTree bt;
string str;
cin >> str;
len = str.size();
int h = 0;//初始深度
int sum = 0;//叶子结点带权路径长度和
bt = CreateBTree(str, 1);
WPL(bt, h, sum);
cout << sum;
return 0;
}
BTree CreateBTree(string str, int i)
{
if ( i >=len||str[i] == '#')
{
return NULL;
}
BTree bt;
bt = new BTNode;
bt->data = str[i];
bt->lchild = CreateBTree(str, 2 * i);
bt->rchild = CreateBTree(str, 2 * i + 1);
return bt;
}
void WPL(BTree bt, int h, int& wpl)
{
if (bt == NULL)
return;
if (!bt->lchild&&!bt->rchild)
{
wpl +=( bt->data-'0') * h;
}
WPL(bt->rchild, h + 1, wpl);
WPL(bt->lchild, h + 1, wpl);
}
树的存储结构
1.双亲存储结构
typedef struct
{ ElemType data;
int parent; //指向双亲的位置
} PTree[MaxSize];
在这种存储结构中,求某个结点的双亲结点十分容易,但在求某个结点的孩子结点时需要遍历整个存储结构。
2.孩子链存储结构
typedef struct node
{ ElemType data;
struct node *sons[MaxSons]; //指向孩子结点
} TSonNode;
在这种存储结构中,求某个结点的孩子结点十分方便,但在求某个结点的双亲结点比较费时,而且当树的度较大时存在较多空指针域。
3.孩子兄弟链存储结构
typedef struct tnode
{ ElemType data;
struct tnode *son; //指向兄弟
struct tnode *brother; //指向孩子结点
} TSBNode;
孩子兄弟链存储结构可以方便实现树和二叉树的相互转换,缺点是查找双亲结点比较麻烦。
树的操作:创建、插入、查找、删除、求树高、树节点操作。
树的遍历:(与二叉树基本类似)
1.先序遍历
2.中序遍历
3.后序遍历
树的应用:

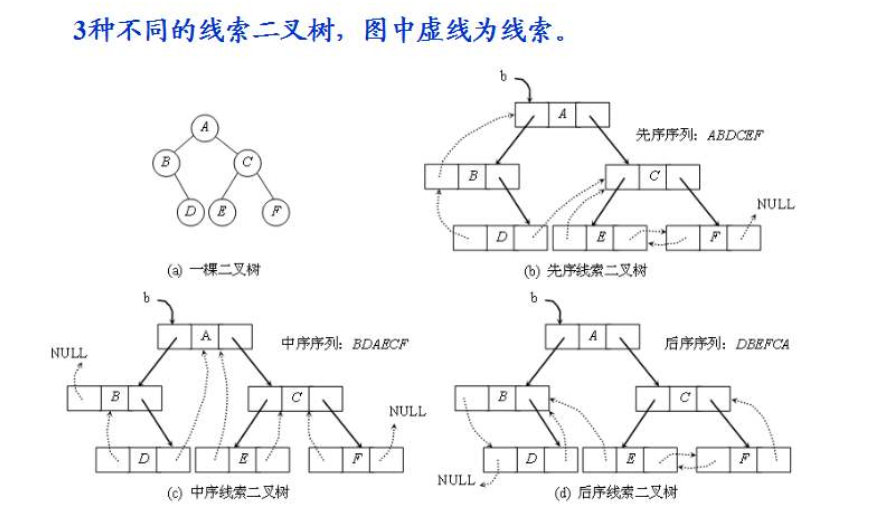
线索二叉树
对于n个结点的二叉树,在二叉链存储结构中有n+1个空链域,利用这些空链域存放在某种遍历次序下该结点的前驱结点和后继结点的指针,这些指针称为线索,加上线索的二叉树称为线索二叉树。
二叉树的线索存储结构定义如下:
typedef char TElemType;
typedef enum { Link, Thread } PointerTag; //Link==0,表示指向左右孩子指针
//Thread==1,表示指向前驱或后继的线索
//二叉树线索结点存储结构
typedef struct BiThrNode {
TElemType data; //结点数据
struct BiThrNode *lchild, *rchild; //左右孩子指针
PointerTag LTag;
PointerTag RTag; //左右标志
}BiThrNode, *BiThrTree;
二叉树线索化
若结点的左子树为空,则该结点的左孩子指针指向其前驱结点。
若结点的右子树为空,则该结点的右孩子指针指向其后继结点。
按照遍历顺序可分为先序线索树、中序线索树、后序线索树。
哈夫曼树
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。

存储结构
typedef struct {
char data;//结点值
int weight;//结点权重
int parent, left, right;//父结点、左孩子、右孩子在数组中的位置下标
}HTNode, *HuffmanTree;
创建哈夫曼树
构造哈夫曼树的算法的实现原理如下:对于n个叶子节点,我们根据上面的定理构造出大小为2*n-1的数组来存放整个哈夫曼树。这个数组的前n个位置存放的为已知的叶子节点,后(n-1)个位置存放的为动态生成的树内节点。在算法的大循环过程中,要做的事情就是根据位置i前面的已知节点(或者是叶节点或者是生成的树内节点),找出parent为-1(即节点尚且是一个子树的根结点)的节点中权值最小的两个节点,然后根据这两个节点构造出位置为i的新的父节点(也就是一棵新树的根结点)。程序如下:
void creatHuffmanTree(HTNode ht[],int n){
int i,j;
int lchild,rchild;
double minL,minR;
for(i=0;i<2*n-1;i++){
ht[i].parent = ht[i].lchild = ht[i].rchild = -1;
}
for(i=n;i<2*n-1;i++){
minL = minR = MAXNUMBER;
lchild = rchild = -1;
for(j=0;j<i;j++){
if(ht[j].parent == -1){
if(ht[j].weight < minL){
minR = minL;
minL = ht[j].weight;
rchild = lchild;
lchild = j;
}else if(ht[j].weight < minR){
minR = ht[j].weight;
rchild = j;
}
}
}
ht[lchild].parent = ht[rchild].parent = i;
ht[i].weight = minL + minR;
ht[i].lchild = lchild;
ht[i].rchild = rchild;
}
}
并查集
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。
初始化
for(int i=1;i<=n;i++) pre[i]=i;
查询
int Find(int x){
if(x==pre[x]) return x;
return pre[x]=Find(pre[x]);
}
合并
void merge(int x,int y){
int fx=Find(x),fy=Find(y);
if(fx!=fy) pre[fx]=fy;
}
2.阅读代码
2.1题目及解题代码


2.1.1该题的设计思路
1.根据平衡二叉树定义,判断根节点是否满足二叉树定义,若不满足返回false;
2.若满足,递归判断根节点左右子树是否满足定义(即对左右子树做1.)
3.若1.和2.不返回,则返回true
时间复杂度O(nlogn);空间复杂度O(n)
2.1.2该题的伪代码
bool isBalanced(TreeNode* root) //判断是否平衡函数
{
if(空树) return true;
定义左右子树的深度为并初始化;
if(左右子树深度差大于1)
return false;
else
左右子树递归;
}
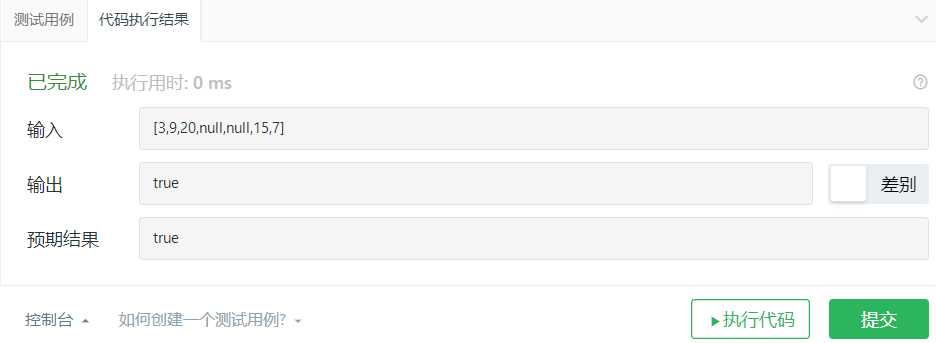
2.1.3运行结果
2.1.4分析该题目解题优势及难点
优势:由顶至底向下判断,容易想到的思路,且代码简练。
难点:没有称得上很难的步骤,但对每个子树的递归处理要细心。
2.2题目及解题代码


2.2.1该题的设计思路
不妨以树t1为基础,将t2合并到t1上。
如果两棵树的根结点都不为空,则累加两个根结点的值;
然后合并t1的左子树和t2的左子树;
然后合并t1的右子树和t2的右子树;
最后返回t1作为合并后的子树根结点。
递归边界为:如果t1为空,则返回t2作为子树;如果t2为空,则返回t1作为子树。
空间复杂度O(n),时间复杂度O(n);
2.2.2该题的伪代码
public TreeNode mergeTrees(TreeNode t1, TreeNode t2) {
if(t1为空)return t2;
if(t2为空)return t1;
t1和t2的根节点相加;
t1的左子树和t2的左子树合并;
t1的右子树和t2的右子树合并;
}
2.2.3运行结果

2.2.4分析该题目解题优势及难点
优势:直接在t1树上进行合并,而不是重建一个树,节省了空间。
难点:递归边界的判断:如果t1为空,则返回t2作为子树;如果t2为空,则返回t1作为子树。