哈夫曼编码是一种编码方式,是可变字长编码(VLC)的一种。其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
面试题常常会考的一种思想,笔试题就更不用说了,选择题直接让你构造哈夫曼树。
哈夫曼编码的图形构造是一棵树,每个节点具有权值,权值越大的节点越靠近树根,越小的节点就越远离树根,从它的定义来看,想到的就是贪心策略。
首先如何构造哈夫曼编码树:每次从树集合中找出权值最小的两棵树分别作为左、右子树,然后合并它们作为他们的父节点,其权值为两颗子树的权值和。
步骤 :
1 :确定合适的数据结构(要知道他的左右子树,双亲,权值)
2:初始化,构造n颗节点为n的字符单节点树集合T={t1,t2,t3,t4···········tn},保证按权值排序,并且每棵树只有树根
3:如果集合中只剩下一棵树,那么哈夫曼树就构造成功,直接跳转到步骤6,否则就是从集合中继续拿出权值最小的子树x作为左子树,第二小的y作为右子树,并将它们合并到一颗z树中,
z的权值为左右子树权值之和
4:从T集合中删除x,y 把新树z加入到集合T中
5:重复步骤3~4
6:约定左分支上的编码都是0,右分支上的编码都是1,从叶子节点开始逆序求出树的编码
对于编码字符出现的频率:
1)将信源符号的概率按减小的顺序排队。 2)把两个最小的概率相加,并继续这一步骤,始终将较高的概率分支放在右边,直到最后变成概率1。 3)画出由概率1处到每个信源符号的路径,顺序记下沿路径的0和1,所得就是该符号的霍夫曼码字。 4)将每对组合的左边一个指定为0,右边一个指定为1(或相反)。
例如:假定下表字符出现频率:
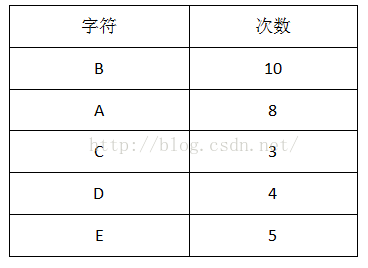
找出两个最小频率的节点分别作为子树,频率相加作为父节点
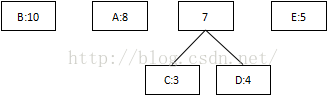
依次进行,直到只有一棵树时:
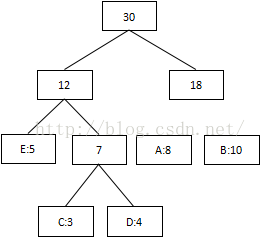
从叶子节点开始往上回溯编码,将每个节点的左孩子节点指定为0,右孩子节点指定为1:
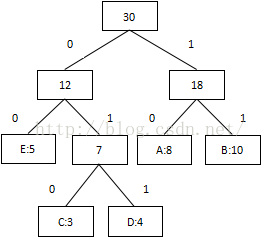
从树根往下遍历,得到相应的编码:
B:11
A:10
D:011
C:010
E:00
Huffman编码使得每一个字符的编码都与另一个字符编码的前一部分不同,不会出现像’A’:00, ’B’:001,这样的情况,解码也不会出现冲突。