一:什么是 “垃圾” ?
x = 1 #把 “1” 这个值赋给 “x”,在计算机中,先是定义了一个变量x,然后在内存里面开辟了一块内存空间,用来存放x的值,也就是1,这个时候,x和1是绑定的。
这种绑定关系,叫做 “引用计数”。这时候,“1”的引用计数就是1.
如果在这个时候,再一次给x赋值,x = 2,那么这个时候,计算机就重新开辟了一块内存空间,用来存放x的值,也就是2,存放了2之后,x和之前的1就自动解绑了。
那么1的引用计数就变成了0,也没有任何变量名能够引用1,1就成为了“垃圾”。
二:什么是垃圾回收机制?
垃圾回收机制(garbage collection,简称 “gc”)
Python的垃圾回收机制主要采用的是引用计数为主、标记清除与分代回收为辅的垃圾回收策略。
简单来说,是专门用来回收不可用变量值所占用的内存空间的一种机制。
三:为什么要用垃圾回收机制?
大多数程序在运行过程中会申请的内存空间,对于一些无用的内存空间如果不及时清理就会出现一种叫做 “内存溢出” 的情况,导致程序奔溃。
因此内存管理是一件非常重要且繁琐的事情,而垃圾回收机制能够把程序猿从繁琐的内存管理中解放出来。
四:垃圾回收机制的原理
1.循环引用
l1=[111,] #此时l1被引用一次,引用计数为1
l2=[222,] #此时l2被引用一次,引用计数为1
l1.append(l2) # l1=[值111的内存地址,l2列表的内存地址]#此时l2又被引用一次,引用计数为2
l2.append(l1) # l2=[值222的内存地址,l1列表的内存地址]#此时l1又被引用一次,引用计数为2
# print(id(l1[1])) #l1引用l2
# print(id(l2))
# print(id(l2[1])) #l2引用l1
# print(id(l1))
# print(l2)
# print(l1[1])
#此时,l1和l2互相引用
del l1 #l1引用次数-1
del l2 #l2引用次数-1
#但是此时我们却无法访问l1和l2列表内的内容,本该被当做垃圾删除,但是这两个内容又被互相间接引用,引用计数不为0,所以无法被当做垃圾清除。
这时候引用计数就不起作用,我们需要用标记清除这种机制来清除垃圾。
2.标记清除 —— 堆区 与 栈区
在定义变量时,变量名与变量值都是需要存储的,分别对应内存中的两块区域:堆区与栈区。
① 变量名与值内存地址的关联关系存放于栈区
②变量值存放于堆区,内存管理回收的则是堆区的内容
先定义2个变量:x = 100,y = 200
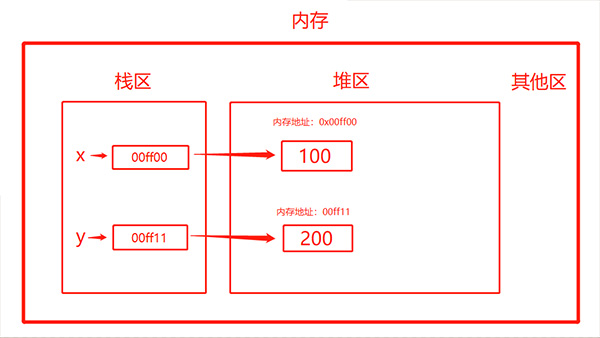
当执行了x = y 时,会发现如下变化:
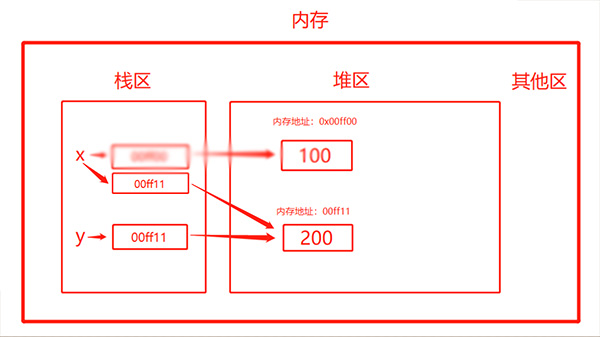
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。
标记清除就是用来清除循环引用情况下引用计数无法清除的垃圾,python解释器县扫面栈区中存活的变量,堆区里面只保留存活变量相关的数据。
并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
3.分代回收
分代,顾名思义,就是分成不同的等级
以班级为例,可以把学生分为三类:学霸、普通学生、学渣
学霸:过于优秀,一周查一次作业
普通学生:一般般,三天查一次
学渣:不用多说,每天都查
虽然分级检查了,检查的时间效率变高了,但是存在着缺陷,如果学霸不交作业,要下一周才能
查出来,那他的学霸地位就不保了,存在漏洞。