数据结构+算法
(原创:黑小子-余)
前言:小编我从小数学并不好,每次考试都是特码分数,跟小伙伴比算数也常常慢一拍,父亲常常恨子不成器。从小就不自信的我,觉得自己智商总比别人差一点,直到成年后,我发现真是如此,每个夜深人静的时候,深深地怀疑自己,哈哈!其实,小编我是一个很正能量的人,虽然踏出学堂、初入社会找工作并不顺利,而且生活中发生很多事也并不如意,找工作的那段时间,也懂得了很多,我相信这些经历都会使我更加强大,我并不怪罪这个社会,反而,我把这些都归咎在自己身上,在自己身上找原因,并做出一些应对策略和改变。
1、自律:把自律当成一种习惯,而不是对自己的一种约束。当你坚持一段时间后,不论是编程也好,还是生活也罢,总会在某些有一些小的提升,你会有成就感,它们会化成你的动力。
2、坚持:坚持是一个长久的过程,有些人想一天就想把编程学会,当然小编我也想,其实不然,往往欲速则不达,事与愿违。其实小编坚持最长久的事是喜欢一个人,哈哈。
3、心态:很多人都死在这个地方,小编我当初也在这个地方死过。在学校编程的时候,if判断老是整不会,别人教也不会,真的是愚蠢至极,都恨自己不成器了。于是,我就去和我们班主任谈谈心,我们管她叫慧姐,我跟她说:我是不是智商有问题。慧姐给我一顿批,我失落的回到教室,始终无法证明自己在智商上有问题这一结论。说到这里,我自己都笑了。
其实,我也是个小白,菜的要命的那种,但是我又不愿放弃,而且,我也喜欢写写文章,所以有了这个兴趣,又有了继续下去的动力,证明自己!本文有借鉴, dcc939705214!
第一章 (一)
一、算法是个什么鬼?
1. 重新定义问题,结构化描述
2. 根据重定义,归类问题
3. 根据问题类别,做经验匹配
4. 根据匹配结果,分支处理:若匹配,采用经验方法;若匹配不上,设计开发新方法
5. 迭代更新经验库,增强面向未来问题的能力
简单来说,算法本质是:解决某类问题的方法。如果方法已经在经验库里了,直接拿来主义,也就是“既有算法”;如果不在,那么设计开发的新方法,新方法就是“新算法”。当然还有一种情况:虽然经验库里有针对该类问题的方法了,但是设计开发了一个更有效的新方法,那么也称为“新算法”。
二、什么是“更有效的算法”?
小编以为,更有效的算法,是节省开销,不论是时间上还是经济还是效率上,减少程序应用的代价。算法其实从学科分类上讲,属于计算数学,计算数学属于应用数学。讲到数学,小编我头又开始疼了,不作太多诠释,小编认为,理科生比文科生更适合学编程。小编我把自己规划在文科生!
三、算法有什么用?
世间万物,皆为对象,java是面向对象编程,凡是生活中出现的事物,利用编程都可以模拟场景。固然,生活中处处存在算法,不论是点外卖,逛超市,做生意,都需要与算法打交道。真正的是,从上面对解决现实问题的过程方法论的描述中,其实已经可以看出算法的价值就在于:经验的重用。IT行话就是“不要重复制造轮子”。
四、算法的应用场景和示例
应对电灯不工作的算法——代码方式
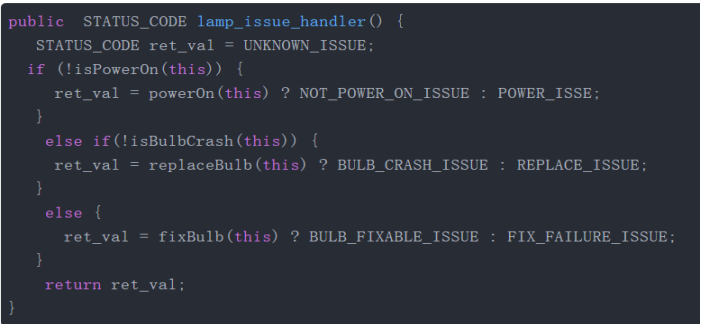
应对电灯不工作的算法——流程图方式
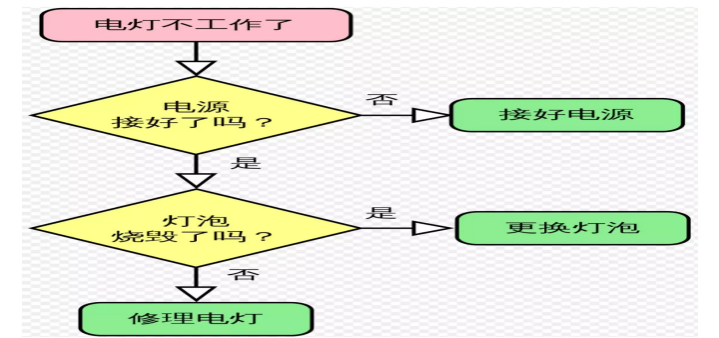
应对电灯不工作的算法——自然语言方式
1、首先检查电源是否接好了:没有接好,接上。
2、如果接上了仍然不工作,看看灯泡是否烧坏了:如果是,换个新灯泡
3、如果灯泡没有烧坏,修理灯泡
五、数据结构又是什么鬼?
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。(这个狭义就有些广了)在许多类型的程序的设计中,数据结构的选择是一个基本的设计考虑因素。许多大型系统的构造经验表明,系统实现的困难程度和系统构造的质量都严重的依赖于是否选择了最优的数据结构。许多时候,确定了数据结构后,算法就容易得到了。有些时候事情也会反过来,我们根据特定算法来选择数据结构与之适应。不论哪种情况,选择合适的数据结构都是非常重要的。
选择了数据结构,算法也随之确定,是数据而不是算法是系统构造的关键因素。这种洞见导致了许多种软件设计方法和程序设计语言的出现,面向对象的程序设计语言就是其中之一。
上面谈叙那么多,就是表达一个观点:算法是要配合数据结构的,抛开数据结构谈算法就是无源之水、无根之树。
著名的图灵奖得主:尼古拉斯·沃斯 提出那个著名的等式:程序 = 算法 +数据结构。
常用结构
数组:在程序设计中,为了处理方便, 把具有相同类型的若干变量按有序的形式组织起来。这些按序排列的同类数据元素的集合称为数组。在C语言中, 数组属于构造数据类型。一个数组可以分解为多个数组元素,这些数组元素可以是基本数据类型或是构造类型。因此按数组元素的类型不同,数组又可分为数值数组、字符数组、指针数组、结构数组等各种类别。
栈:是只能在某一端插入和删除的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
队列:一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列是按照“先进先出”或“后进后出”的原则组织数据的。队列中没有元素时,称为空队列。
链表:是一种物理存储单元上非连续、非顺序的存储结构,它既可以表示线性结构,也可以用于表示非线性结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
树:是包含n(n>0)个结点的有穷集合K,且在K中定义了一个关系N,N满足 以下条件:
(1)有且仅有一个结点 K0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root)。 (2)除K0外,K中的每个结点,对于关系N来说有且仅有一个前驱。
(3)K中各结点,对关系N来说可以有m个后继(m>=0)。
图:图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
堆:在计算机科学中,堆是一种特殊的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
散列表:若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个思想建立的表为散列表。
总结:看到这里,我相信,你多少对算法和数据结构有一点点了解,其实算法很广义,需要你这种有梦想的人去探索。我最初写博客,也只是想对自己的理解做一个记录,如果本文有不合格的地方,可以指正,三人行,必有我师!
qq:2931445528
-----------------------------------------------------------END----------------------------------------------------------------