Python爬虫爬取全书网小说教程
第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下

点击Network之后出现如下内容:

第二步:进入如下页面分析Network中的内容(网址、编码方式一般为gbk)


第三步:程序详细分析如下所示:
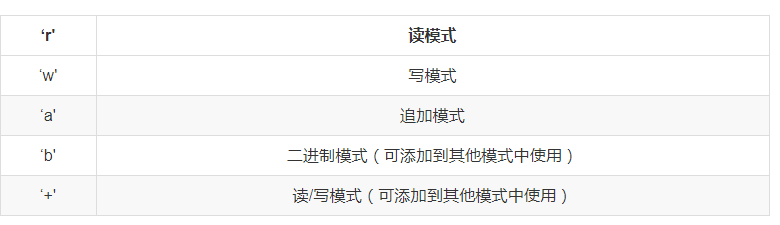
# _*_ utf-8 _*_: # author:Administrator from urllib import request #导入请求库,有的版本是import requests import re #用于正则表达式 first_url="http://www.quanshuwang.com/book/9/9055" #你所需要下载的小说的网址 html=request.urlopen(first_url).read().decode('gbk') #上图箭头所示 novel_info={} #创建一个空的字典,注意不是空的集合序列 novel_info['title']=re.findall(r' <div class="chapName">.*<strong>(.*)</strong>',html) #()中的正则表达式,提取的内容放到novel_info里面 re.findall返回的是一个列表 而之后要把它转化为字符串处理 一定要注意那些是列表那些是字符串 novel_info['author']=re.findall(r' <div class="chapName"><span class="r">作者:(.*)</span><strong>盗墓笔记</strong><div class="clear"></div></div>',html) div_info=re.findall(r'<DIV class="clearfix dirconone">(.*?)</DIV> ',html,re.S|re.I)[0] #此处在re.finall()返回一个序列,序列里只有一个元素,在后面加个[0]将他访问出来,转化为字符串,re.S|re.I不能丢否则得到空集 #获取每一个章节的地址 tag_a=re.findall(r'<a.*?</a>',div_info) #循环每个章节依次获得内容 for i in range(0,60): chapter_title = re.findall(r'title="(.*?)"', tag_a[i])[0] chapter_url=re.findall(r'href="(.*?)"',tag_a[i])[0] chapter_content=request.urlopen( chapter_url).read().decode('gbk') #与上面的思路一样 chapter_text = re.findall(r'<div class="mainContenr" (.*)style6', chapter_content, re.I | re.S)[0] # print(chapter_content) chapter_clear = chapter_text.replace(r" ", "") #都是清洗数据的步骤,可以依据具体环境而定 chapter_clear1 = chapter_clear.replace(r"<br />", "") chapter_clear2 = chapter_clear1.replace(r'id="content"><script type="text/javascript">style5();</script>', "") chapter_clear3 = chapter_clear2.replace(r'<script type="text/javascript">', "") file = open(r'E:老九门全书网.txt', 'a') file.write(chapter_title+' '+chapter_clear3+' ') #文件的读写操作 print(chapter_title) file.close()
其他:
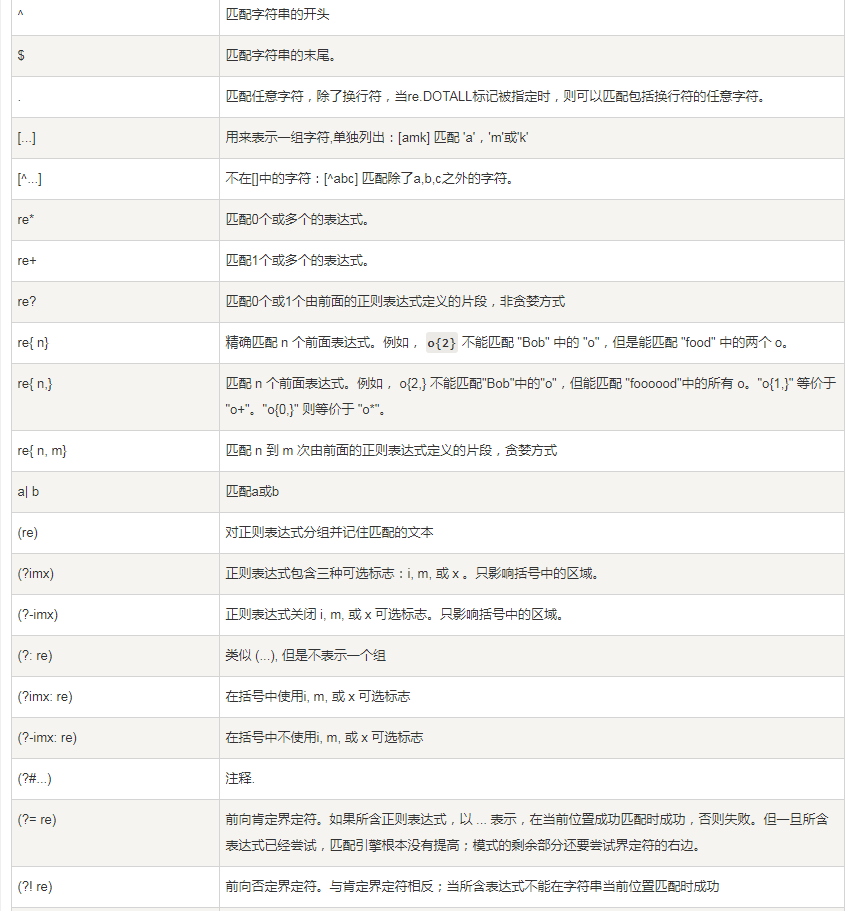
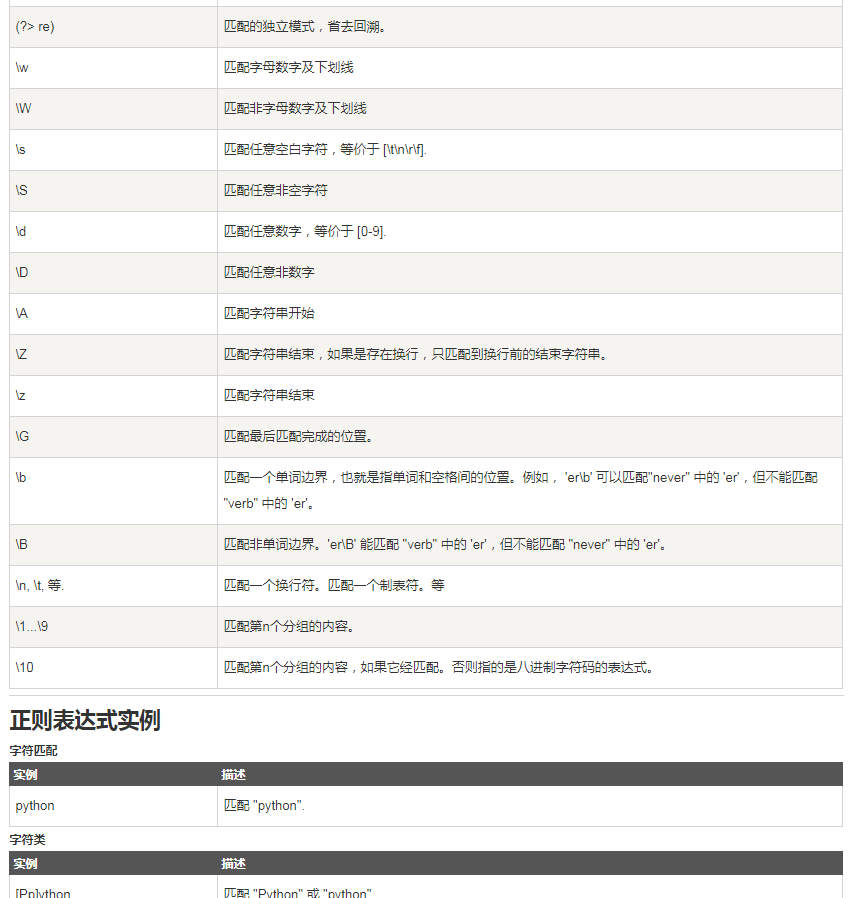
正则表达式附录:


Python文件读写: