HashMap死锁
在讲解HashMap之前我们先来看看一段代码:
public class HashMapDeadLockTest {
public static void main(String[] args) {
MapResizer map= new MapResizer();
for (int i=0;i<30;i++){
new Thread (new MapResizer()).start();
}
}
}
class MapResizer implements Runnable {
public Map<Integer,Integer> map = new HashMap<Integer, Integer>(2);
public AtomicInteger atomicInteger = new AtomicInteger();
public void run() {
while(atomicInteger.get() < 100000){
map.put(atomicInteger.get(),atomicInteger.get());
atomicInteger.incrementAndGet();
}
}
}
运行这段代码,会发现代码一直处于运行状态,其实就是发生了死锁。(运行环境是jdk1.7)。具体怎么死锁呢,我们下面来具体看看:
HashMap在扩容的时候会发生死锁,扩容死锁的代码如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next; //线程E2在此处park
//LockSupport.park
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
假设我们的线程2运行到下面的情况的时候Park住:

然后我们的线程1开始运行:根据transfer方法中的代码,遍历扩容前的数组,当遍历到14的时候,发现e!=null,进入循环。e1指向房东,next1 指向卷福,进行rehash以后假设i=20.刚开是newTable[i]=null,于是房东的next指针=null,把房东放在newTable[20]上面,next1赋值给e1,即e1和next1指向卷福,如下图

然后开始第二轮循环,e=指向卷福不为空,继续往下执行,e1.next=null ,则next1指针指向null,rehash以后,假设i依旧=20。newTable[20]=房东,那么,这时候e1.next指针=房东。(头部插入),newTable[20]=卷福。最后把next1指针赋值给e1,则e1=next1=null.如下图:
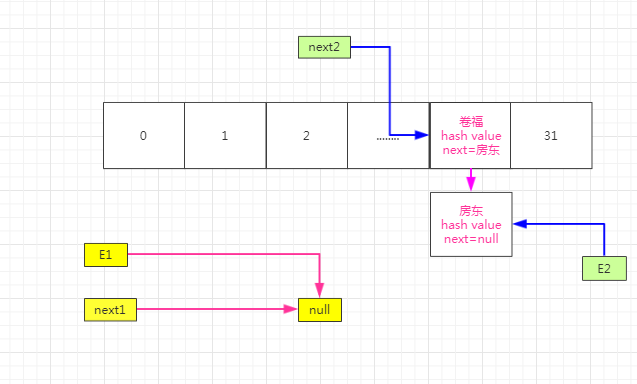
线程1执行完成,线程2被唤醒开始继续执行。根据上图可以看到现在next2指针指向的的卷福即next2=卷福,E2指针指向的是房东,e2=房东。现在继续第一轮循环,进行rehash,假设rehash以后i还是20.那么e.next=newTable[20]=卷福,然后把next2赋值给E2,就是e2=next2=卷福,如下图:
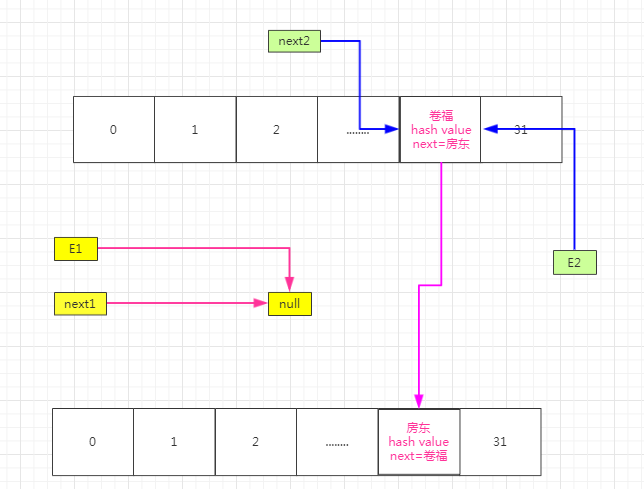
然后继续开始线程2的第二轮循环,e2=卷福,e.next=房东,那么next2指向房东,rehash以后i=20.newTable[20]=房东,那么e.next=房东。然后再把卷福移动到newTable[20],即newTable[20]=卷福。再把next2赋值给E2,就是说next2=e2=房东。如下图:
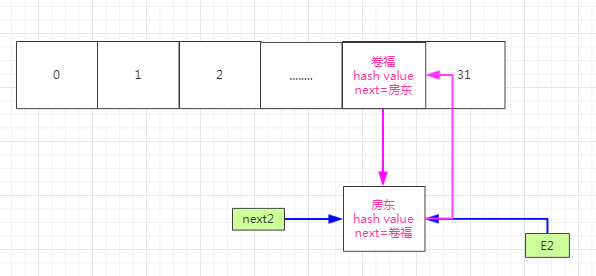
此时可以看到卷福和房东的next指针都指向彼此,然后这个扩容就进入了死循环。这就造成我们的死锁。这个死锁只是在jdk1.7会出现,jdk1.8就不会出现了,那么jdk1.8没有这个问题是如何避免的,我们来看一下。
我们先来看一下jdk1.8的resize的代码:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
根据以上代码,我们假设我们现在在15位置上有一个以下数组:
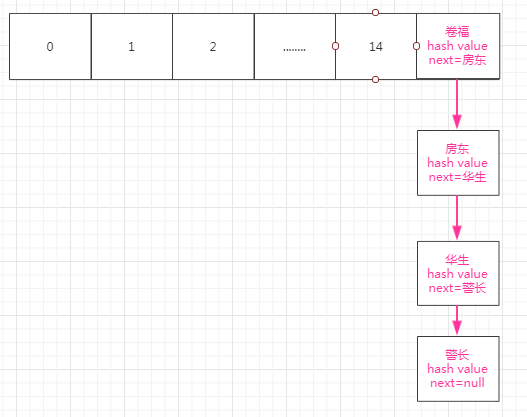
根据以上的代码,我们来进行扩容。
因为oldTab!=null,进入循环,遍历老Tab里面的元素,当j=15的时候我们的不为空。此时e指向oldTab[15],进入此条件后将oldTab[15]值为空,将e移出。如下图所示:
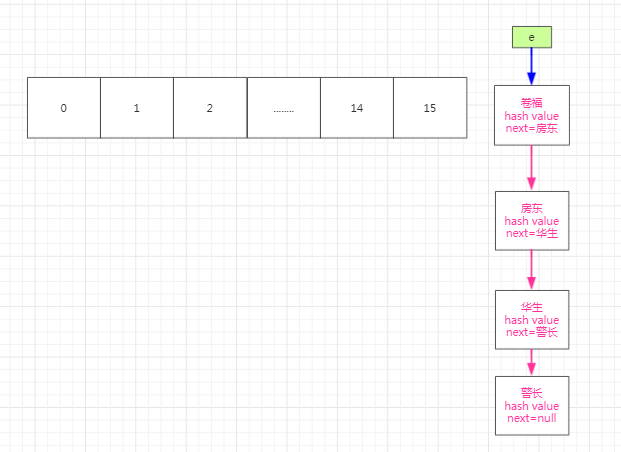
此时的e.next!=null 则初始化loHead=null,loTail=null,hiHead=null,hiTail=null,next。此时的next指向房东。假设刚开始e.hash&oldCap==0,而且这时候loTail==null,那么我们的loHead=e=卷福,loTail=e=卷福,如下图:
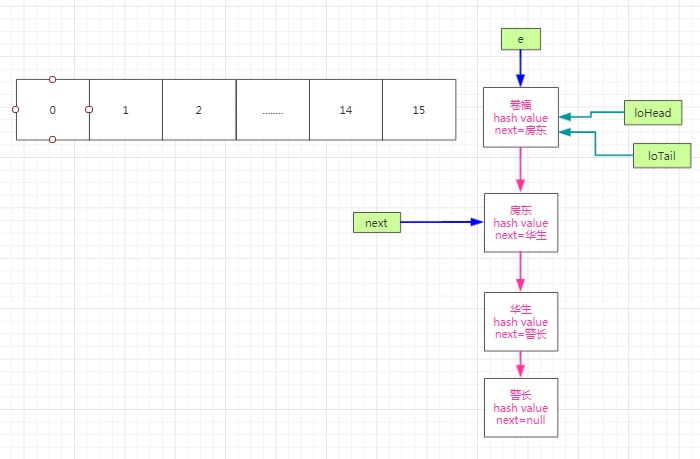
由上图可以看到next所指的对象!=null,因此while()循环继续。第二轮循环的时候将next的值赋值给e,那么e指针指向房东,next指针指向华生,假设(e.hash & oldCap) == 0那么此时我们的loTail!=null,所以我们要把loTail.next=房东,loTail指向房东,如下图:
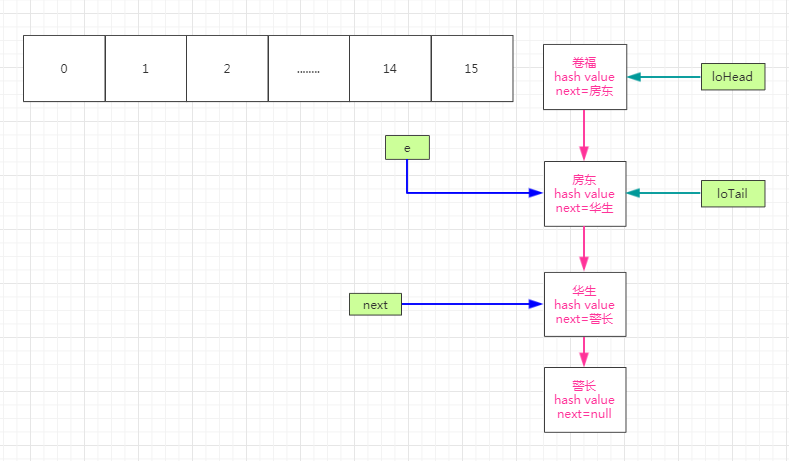
紧接着将next赋值给e,那么e指向华生,且!=null,那么我们继续while循环。next 指针指向警长,此时假设(e.hash & oldCap) != 0那么此时我们就走hiTail,此时hiTail为空,将e赋值给hiHead,那么hiHead=华生,hiTail=华生,如下图:
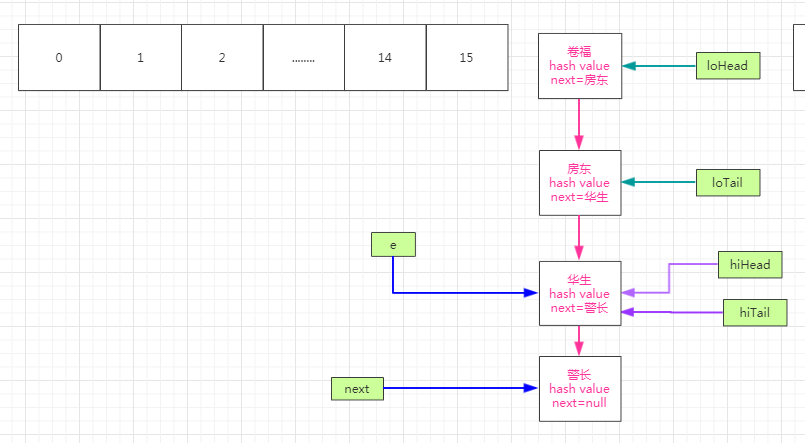
然后继续循环,e指向警长,不为空,next指针指向null,此时的hiTail !=null,那么hiTail.next=警长,loTail=警长,然后将next赋值给e,此时e=next=null,结束while循环,如下图:
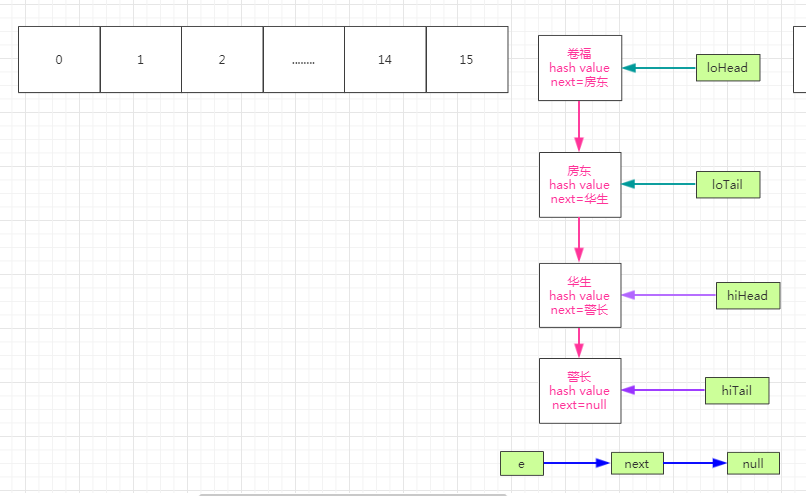
结束while循环以后继续往下走loTail!=null ,将loTail.next设置为null,然后将loHead放置到新table的15位置,即newTab[15],将hiTail.next设置为空,将hiHead放置到newTab[31]的位置,如下图:

由以上可以看出jdk1.8采用的高低位搭配扩容,不会行程死环情况,这样就不像jdk1.7两个指针来回指导致死循环。jdk1.8的hashMap除了数组+链表还有红黑树结构。
HashMap线程不安全
jdk1.7和jdk1.8在高并发的情况下都会出现数据丢失和get到null的情况 。数据丢失就是说多个线程同时put,导致一些值被覆盖,这样就造成了数据丢失。get到null值也是一样的,当多线程put.,get的时候,一个线程还没有put进去就被get了,这个时候就会get到null值。下面的代码来演示一下数据丢失的情况。也就是说HashMap在jdk1.7,jdk1.8都是线程不安全的。
/**
* <p>Title: HashMapDataMisingTest.java</p >
* <p>Description: </p >
* <p>@datetime 2019年8月18日 上午2:19:31</p >
* <p>$Revision$</p >
* <p>$Date$</p >
* <p>$Id$</p >
*/
package com.test;
import java.util.HashMap;
import java.util.Map;
/**
* @author hong_liping
*
*/
public class HashMapDataMisingTest {
public static final Map<String ,String> map=new HashMap<String , String>();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<1000;i++){
map.put(String.valueOf(i), String.valueOf(i));
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i=1000;i<2000;i++){
map.put(String.valueOf(i), String.valueOf(i));
}
}
}).start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("mapSize:"+map.size());
for (int i=0;i<2000;i++){
System.out.println("value:"+map.get(String.valueOf(i)));
}
}
}
//测试结果:
mapSize:1995
根据上面的结果我们可以看出,我们的size不对,本来是应该为2000,但是现在只是1995,有几笔不见了。为什么会出现上面的情况呢,就是上述的线程不安全导致的。
HashMap的基本信息详解可以去看一下这篇博客,比较好。https://www.jianshu.com/p/ee0de4c99f87。
ConcurrentHashMap线程安全
根据上述的讲解我们知道在多线程高并发的情况下hashMap是不安全,在这种情况下想要使用线程安全的怎么办呢,这时候我们就可以使用ConcurrentHashMap。先来看一下jdk7的ConcurrentHashMap的数据结构,如下:
jdk7 ConcurrentHashMap数据结构
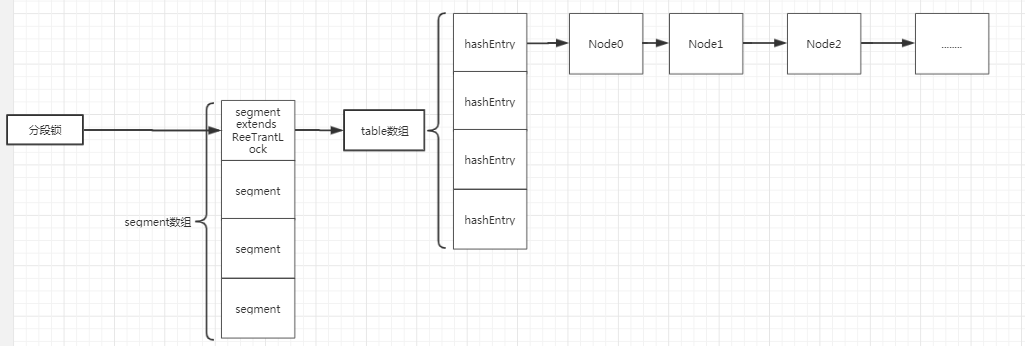
就是说每个segment段通过继承ReetrantLock来进行加锁,就是每个段都有个分段锁,每个段下面有个table数组,这个table数组就是数组+链表的格式.
jdk8 ConcurrentHashMap数据结构
jdk8的时候对这个ConcurrentHashMap的数据结构进行了优化,没有分段,直接就是Node数组+链表+红黑树的结构,如下图所示:
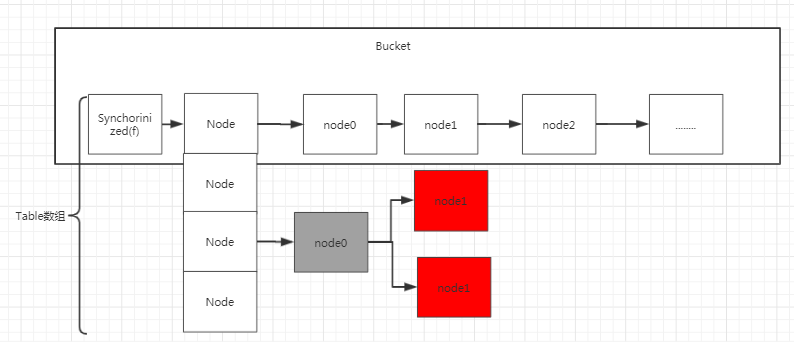
在JDK8中我们可以看到当多个线程并发往同一个空的头节点插值的时候,可能出现值的覆盖,jdk8中为了避免这个问题使用的CAS操作,这样就避免了值丢失的问题。同时还有一个参数需要去关注,SIZECTL,初始值为SIZECTL=-1,当SIZECTL=-1的时候表示正在扩容,还没有扩容完成,当SIZECTL>0表示扩容已经完成。
为什么说是线程安全的呢,我们来看一下:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
从上面的代码也可以看出ConcurrentHashMap在进行put操作的时候使用了Synchronized关键字,这样也保证了线程安全。
以上有疑问欢迎各位小伙伴们来一起讨论。