 python之道 优雅 明确 简单
python之道 优雅 明确 简单
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
编译型语言与解释型语言
编译工具 
 交互式命令行IDE
交互式命令行IDE
1. 变量名的长度不受限制,但其中的字符必须是字母、数字、或者下划线(_),而不能使用空格、连字符、标点符号、引号或其他字符
2.变量名的第一个字符不能是数字,而必须是字母或下划线
3.Python区分大小写
4.不能将Python关键字用作变量名
pycharm快捷键:
String( 字符串 ) 把一对字符放在 ' ' (单引号) / " " (双引号) / ''' '''(三引号)中

python中定义变量的时候字符串都用用引号括起来,单引号和双引号没有区别,用啥都行,如果说这个字符串里面有单引号的话,那你外面就用双引号,里面有双引号的话,外面就用单引号,如果既有单又有双,那么用三引号,三引号也可以多行注释代码,单行注释,使用#,代码如下:


Python数据类型:
数字 字符串
集合:无序,即无序索引相关信息
元组:有序,需要存索引相关信息,不可变
列表:有序,需要存索引相关信息,可变,需要处理数据的增删改
字典:无序,需要存key与value映射的相关信息,可变,需处理数据的增删改

通过下标访问列表中的元素,下标从0开始计数,也就是说,比如说一个列表,有个5元素,那么它第一个元素下标就是0,第二个就是1,以此类推,字符串也有下标,和列表一样 对列表的操作,分以下几种增、删、改、查
增:

删:

改:

查:

列表操作,一些内置的方法:

切片,切片也就是另一种方式获取列表的值,它可以获取多个元素,可以理解为,从第几个元素开始,到第几个元素结束,获取他们之间的值,格式是name:[1:10],比如说要获取name的第一个元素到第五个元素,就可以用name[0:6],切片是不包含后面那个元素的值的,记住顾头不顾尾;前面的下标如果是0的话,可以省略不写,这样写,name[:6],切片后面还有可以写一个参数,叫做步长,也就是隔多少个元素,取一次,默认可以不写,也就是隔一个取一次,切片操作也可以对字符串使用,和列表的用法一样,实例如下:
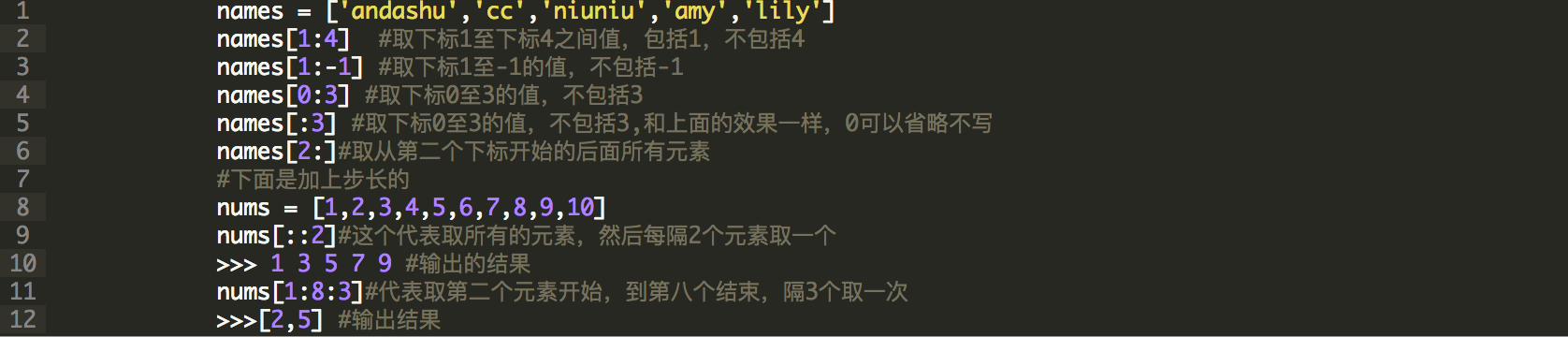
元组
元组其实和列表一样,不一样的是,元组的值不能改变,一旦创建,就不能再改变了,比如说,要存数据库的连接信息,这个连接信息在程序运行中是不能被改变的,如果变了那数据库连不上了,就程序就完犊子了,这样的就可以使用元组了,元组呢,也提示别人,看到是元组的话,就说明这个值是不能被改变的,元组的定义方式是用(),小括号;元组只有两个方法,那就是count和index

字典
上面说了,整形、浮点型、字符串、列表和元组,下面说个新的数据类型,字典,字典也是我们开发过程中最常用的一种数据类型;想一个问题,现在要存整个北京市的所有人的信息,每个人有姓名、年龄、性别、家庭住址、学历等等,那要是用列表存的话,那就得定义N多个数组,然后存上每个人的信息,那累死人了。。。这时候又有一种新的数据类型出现了,那就是字典,dict,全称是dictionary,它具有极快的查找速度;字典是一种key-value的数据类型,比如说要存每个人的信息,那么每个人的编号就是key,value就是每个人的信息,这样的话,一个字典就能存所有人的信息了。字典的定义使用{},大括号,每个值用“,”隔开,key和value使用“:”分隔。
举个列子,如果用列表存每个人的信息的话,需要用两个列表,一个存人名,一个存信息:

给一个名字,如果要查他的对应信息,那就要先从names里面找到它的位置,然后再从infos中找到它的信息,如果这个列表越长,那么它的查询速度越慢。
如果用字典实现的话,只需要一个名字和信息对应的一个表,这样就很快的根据名字找到它对应的信息,无论这个表有多大,查找速度都不会变慢。

为什么dict查找速度这么快?因为dict的实现原理和查字典是一样的。假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。
第二种方法是先在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢,这种就是字典的实现方式。
字典的特性:
字典是无序的,因为它没有下标,用key来当索引,所以是无序的
字典的key必须是唯一的,因为它是通过key来进行索引的,所以key不能重复,天生就去重
字典的增删改查:
增:

删:

改:

查:

字典的内置方法:

循环字典:

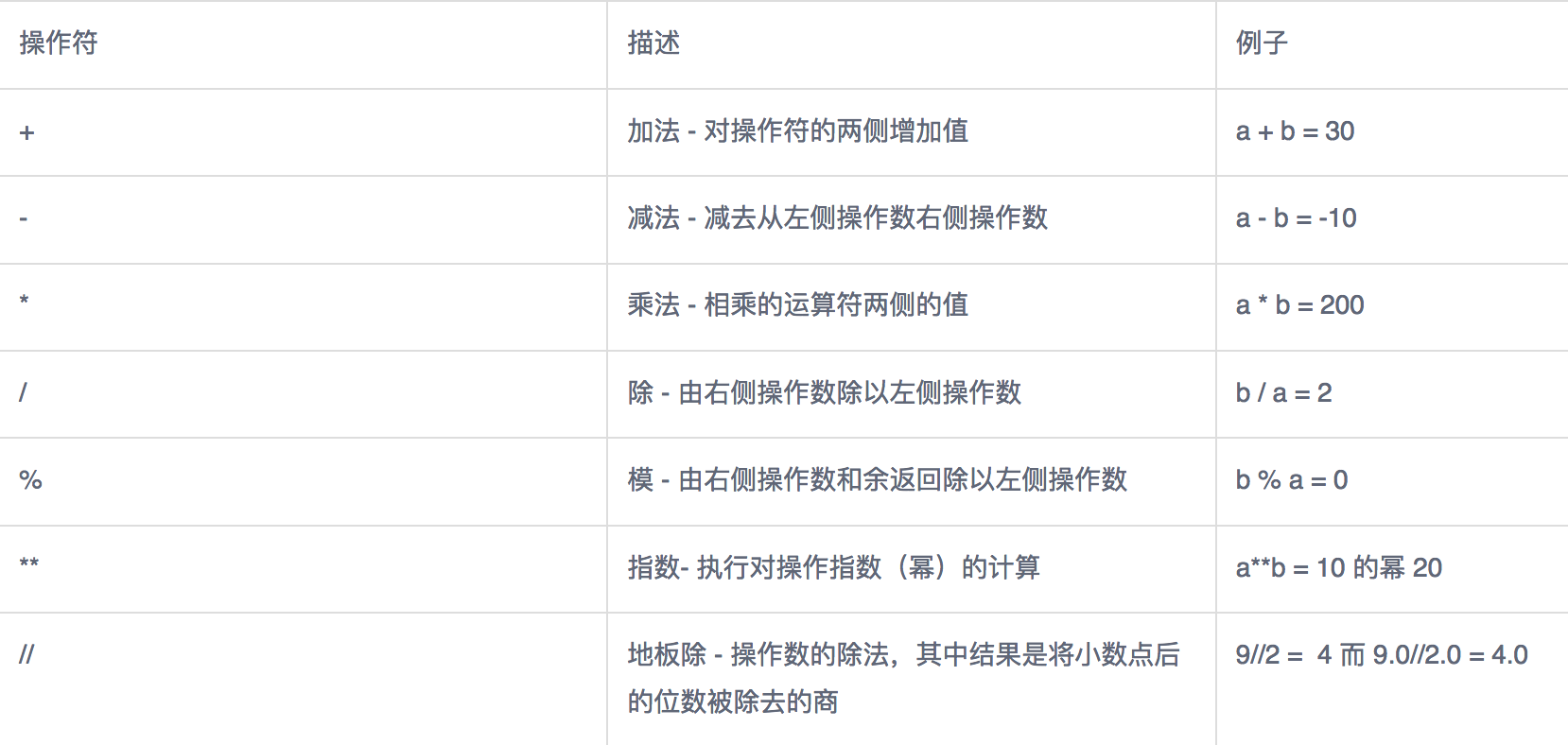
数据运算
算数运算符
比较运算符

Python赋值运算符

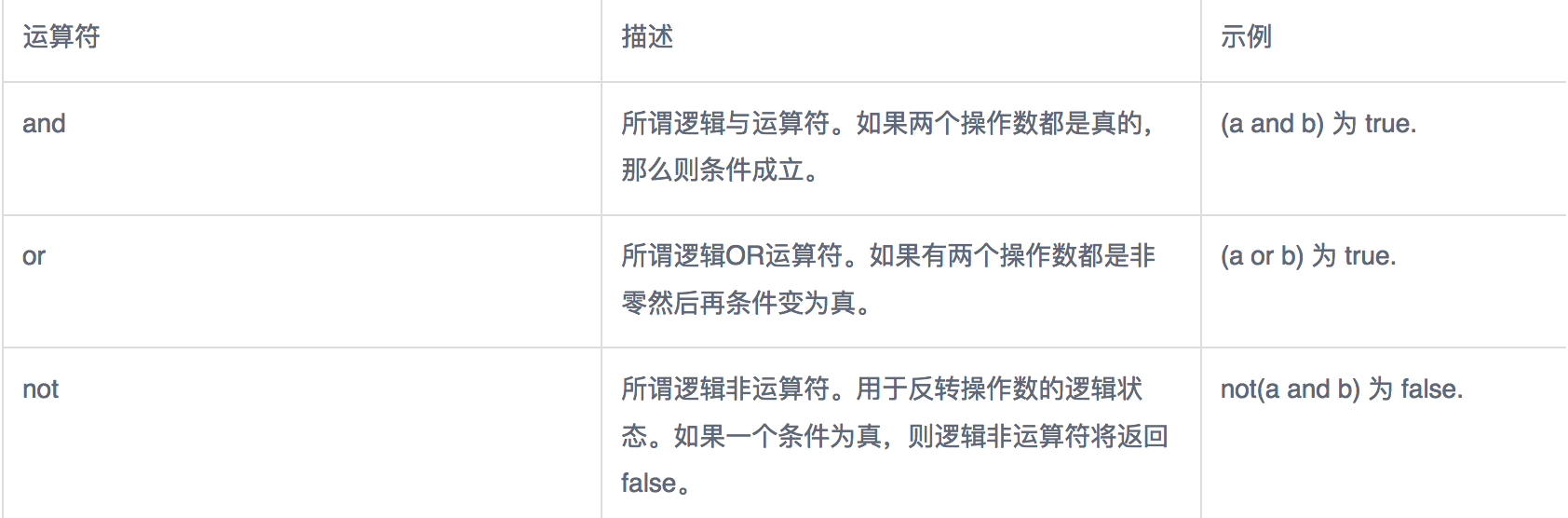
逻辑运算符
身份运算符

模块初识
模块是导入别人已经写好的python文件,里面已经有一些写好的功能,可以直接拿来使用,使用import
关键字导入需要的模块,导入模块时,默认会在当前目录下去寻找该文件,如果当前目录下没有的话,回去python的环境变量中找,如果找不到就报错,下面有一些简单的python标准模块,os和sys模块:

三元运算符
三元运算符就是在赋值变量的时候,可以直接给它加上判断,然后赋值

当然三元运算符也可以用在列表和字典中,这么写的话,就比较简单了,不过如果搞不明白三元运算符的话,还是不用为好

流程控制 if else

while 循环

break 退出本次循环 continue 退出本次循环,继续下一次循环
import datetime 通过import 导入 datetime today = datetime.datetime.today( ) today = str(today)
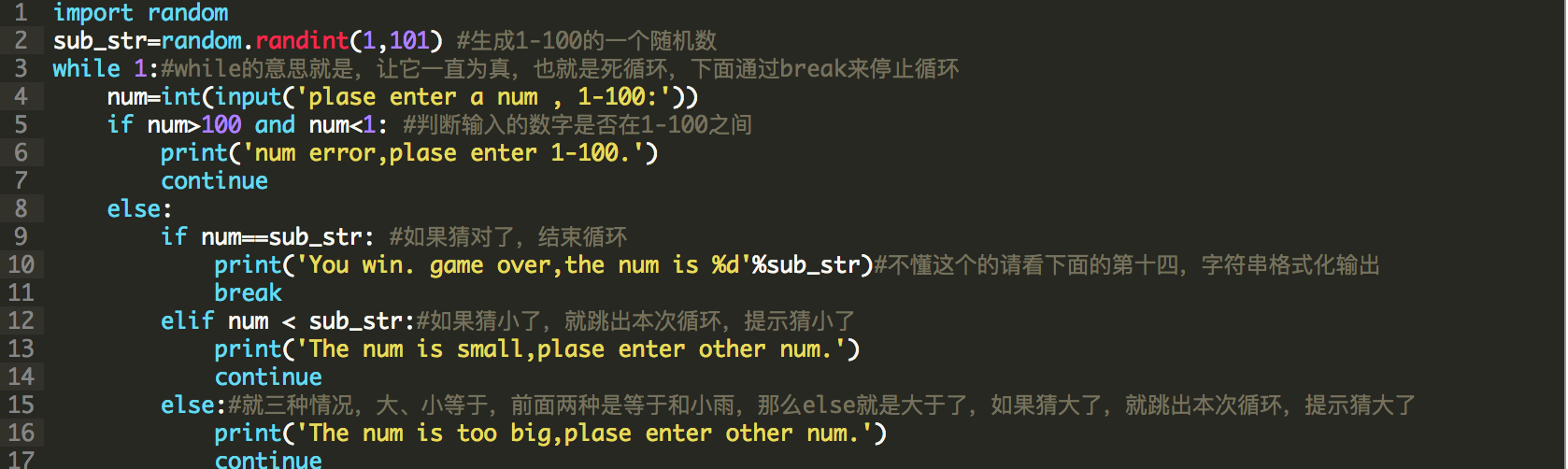
小游戏
猜数字的游戏,要求是这样,产生一个随机数字,1-100之间,接收用户输入,如果猜对了,游戏结束,猜大了,提示猜大了,小了提示猜小了。产生随机数模块使用random.randint(1,101),是一个标准包,导入使用即可,代码如下:
格式化输出
什么是格式化输出呢,就是说把你的输出都格式化成一个样子的,比如说登录的欢迎信息,都是welcome to login,Marry.
每个用户登录都是这样欢迎,但是每个用户的用户名都是一样的,你不能一个用户就写一行代码吧,这就需要用到格式化输出了,有三种方式,第一种是用“+”连接,直接把输出的字符串和变量连接起来就可以了;第二种是用占位符,占位符有常用的有三种,%s、%d和%f,%s是后面的值是一个字符串,%d是后面的值必须是一个整数,%f后面是小数;第三种是使用{}和fromat方法,这三种呢,官方推荐是使用format方法,不推荐使用第一种,第一种用加号的,会在内存里面开辟多个内存空间,而后面两种是只开辟一块内存空间,使用方式如下:
%s(str) 字符串 %d(int)整数 %f(float)小数 0.2%f 保留2位小数 round(score,2) 保留小数后几位 四舍五入