19.1-gawk程序基础特性
linux世界中最广泛使用的两个命令行编辑器:
- sed
- gawk
1. gawk概念
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
- 定义变量来保存数据
- 使用算术和字符串操作符来处理数据
- 使用结构化编程概念来为数据处理增加处理逻辑
- 通过提取数据文件中的数据元素,将其重新排列或格式化,生成格式化报告
gawk的报告生成能力通常用来从大文本文件中提取数据元素,并将它们格式化成可读 的报告,完美的例子是格式化日志文件。
在所有的发行版中都没有默认安装gawk程序。

2. gawk格式化
1 awk '{pattern + action}' {filenames}
- -F fs 指定行中划分数据字段的字段分隔符
- -f progfile 从指定的文件中读取程序
- -v var=value 定义gawk程序中的一个变量及其默认值
- -mf N 指定要处理的数据文件中的最大字符段数
- -mr N 指定数据文件中的最大数据行数
- -w keyword 指定gawk的兼容模式或告警等级
gawk强大之处在于可以写脚本来读取文本行的数据,然后处理并显示数据。

2.1 从命令行读取程序脚本
必须将脚本命令放到两个花括号{ } 中。

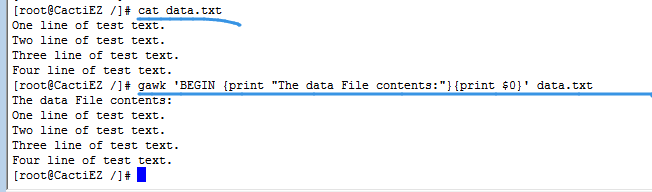
以上运行gawk’{print"hello word"}‘不会有任何反应,print命令会将文本打印到STDOUT,但没有在命令行上指定文件名,所以gawk只会从STDIN接收数据。
若输入一个文本并按下回车键,不管你在数据流中输入什么,都会得到同样的输出hello word 。
ctrl+D组合键会在bash中产生一个EOF字符,便是数据流已经结束。
2.2 使用数据字段变量
gawk会自动给一行中的每个数据元素分配一个变量,默认情况下,会将如下变量分配给它在文本行中发现的数据字段:
- $0代表整个文本;
- $1代表文本行中的第一个数据字段;
- $2代表文本行中第二个字段;
- $n代表文本行中第N个字段
-
每个数据字段是通过字段分隔符划分的,默认字段分割符是任意的空白字符(如空格或制表符)。

2.3 在程序脚本中使用多个命令
如果要在命令行的脚本中使用多条命令,只要在命令之间放个分号;即可。

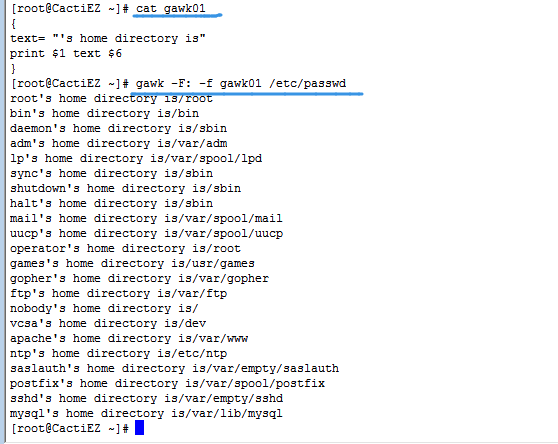
2.4 从文本中读取程序
- 允许将程序储存在文件中,然后在命令行中引用。
- 可以在文件中指定多条命令,只要一条命令放一行就可以,不需要使用分号。


2.5 从处理数据前/处理数据后运行脚本
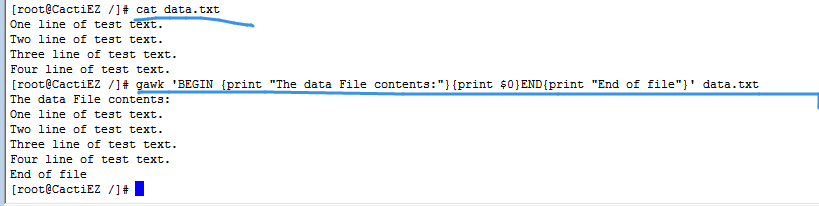
默认情况,gawk会从输入中读取一行文本,然后针对该行的数据执行程序脚本,但有时可能需要在处理数据前或数据后运行脚本:
- BEGIN关键字,强制gawk在读取数据前执行BEGIN关键字后指定的程序脚本
- END关键字,gawk在读完数据之后执行END关键字后的程序