论文链接: https://arxiv.org/pdf/1703.04247.pdf
FM原理参考:
Factorization Machines with libFM 论文阅读 https://www.cnblogs.com/yaoyaohust/p/10225055.html
GBDT,FM,FFM推导 https://www.cnblogs.com/yaoyaohust/p/7865379.html
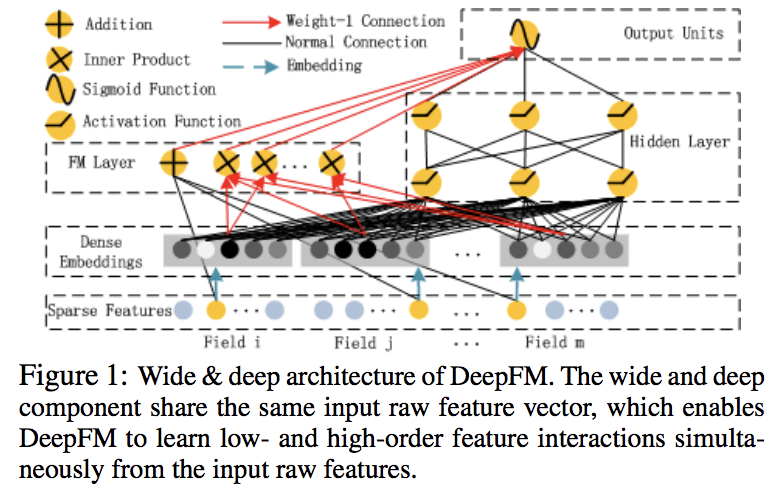
类别型特征one-hot编码,连续型特征直接表示或者离散化后one-hot编码。
核心思想就是拿FM模型输出的交叉项权重当做embedding使用,FM和Deep分量共用这个embedding。
因此不用预训练(因为整体训练),不用特征工程(因为FM),同时有低阶和高阶交互项(因为FM和NN)。
评估:AUC,LogLoss(cross entropy)
训练快速
激活函数:relu、tanh比sigmoid更常用;而且relu比tanh好(因为减少稀疏性)
Dropout: 0.6-0.9
Neurons per layer: 200-400
最优Hidden layer: 3
network shape: constant(等宽,“中规中矩”)