本篇文章主要讲述如何在CDH中启动Spark Thrift。
本次测试的版本:
CDH版本:5.14.2
spark:1.6.0
文中主要用root来部署,但是启动的时候用的spark用户,中间会有一些权限方面的问题。大家可以根据提示自行添加权限。我这边权限不够默认都给了777,方便测试。
文中的spark服务器与hive元数据的服务器不在同一台服务器上。所以不会涉及端口冲突的错误。(spark Thrift默认端口10000)
一:部署主要分以下几步:
1.下载原生的spark的编译好的包
http://archive.apache.org/dist/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
2.替换spark-assembly 的jar包,并上传到hdfs节点上,上传Spark Thrift的启动、停止脚本,上传spark-sql脚本
从下载的包中,找到如下几个文件:
sbin/start-thriftserver.sh sbin/stop-thriftserver.sh bin/spark-sql lib/spark-assembly-1.6.0-hadoop2.6.0.jar
并将前3个上传到对应的目录中
第四个有点特殊:spark-assembly-1.6.0-hadoop2.6.0.jar,上传至:/opt/cloudera/parcels/CDH/lib/spark/lib,删除原有的软连接,注意做好备份
#cd /opt/cloudera/parcels/CDH/lib/spark/lib #rm -rf spark-assembly-1.6.0-cdh5.13.0-hadoop2.6.0-cdh5.13.0.jar #ln -s ../../../jars/spark-assembly-1.6.0-hadoop2.6.0.jar spark-assembly-1.6.0-hadoop2.6.0.jar #ln -s ../../../jars/spark-assembly-1.6.0-hadoop2.6.0.jar spark-assembly.jar

在hive的数据节点上操作:
#sudo -u spark hadoop fs -put /opt/cloudera/parcels/CDH/jars/spark-assembly-1.6.0-hadoop2.6.0.jar /user/spark/share/lib #sudo -u spark hadoop fs -chmod 755 /user/spark/share/lib/spark-assembly-1.6.0-hadoop2.6.0.jar
3.在cdh的spark中配置相关信息

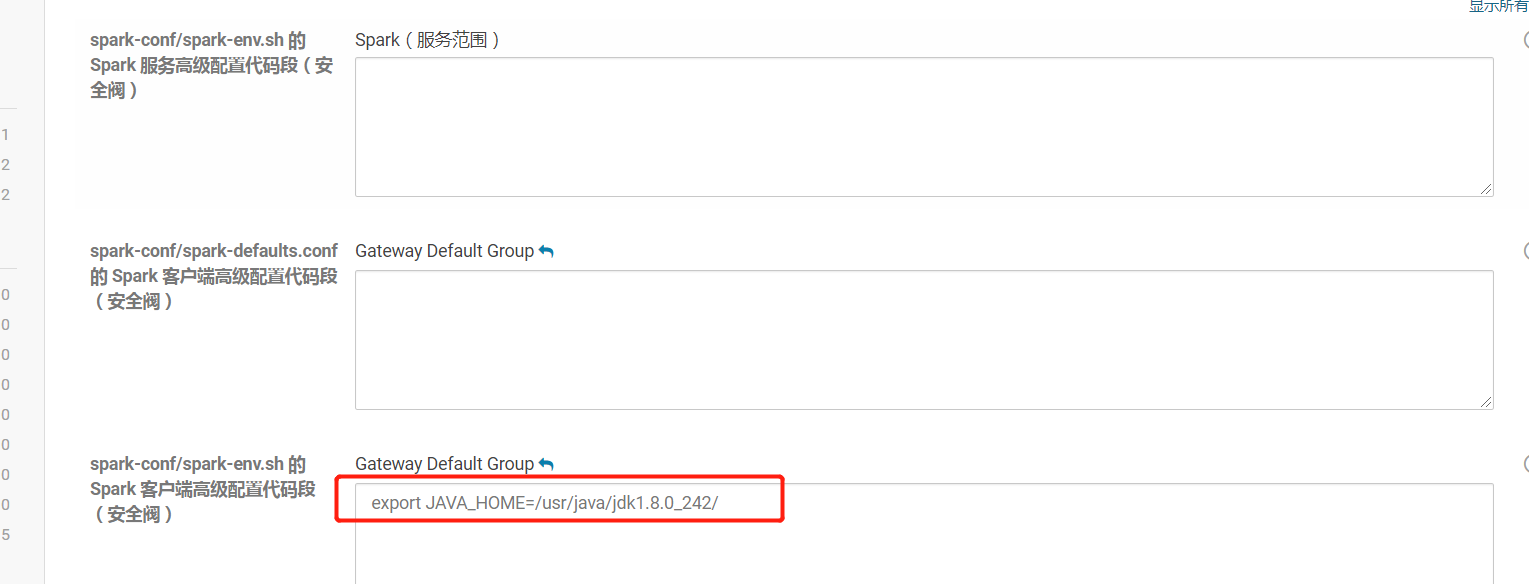
保存配置,并重启Spark
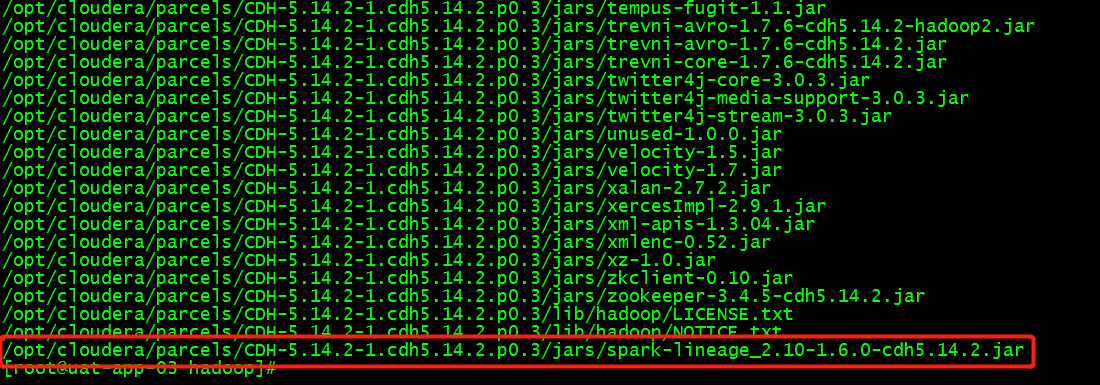
4.修改/etc/spark/conf/classpath.txt文件,在最后添加如下内容
/opt/cloudera/parcels/CDH-5.14.2-1.cdh5.14.2.p0.3/jars/spark-lineage_2.10-1.6.0-cdh5.14.2.jar
由于CDH5.11以后版本,Navigator2.10增加了Spark的血缘分析,所以这里需要添加spark-lineage_2.10-1.6.0-cdh5.13.0.jar包,否则连接Spark会报错找不到com.cloudera.spark.lineage.ClouderaNavigatorListener类
5.修改修改 load-spark-env.sh 脚本,这个脚本是启动 spark 相关服务时加载环境变量信息的
需要将注释掉exec "$SPARK_HOME/bin/$SCRIPT""$@",因为在start-thriftserver.sh脚本中会执行这个命令
# cd /opt/cloudera/parcels/CDH/lib/spark/bin
# vi load-spark-env.sh

5.启动Spark ThriftServer脚本
#sudo -u spark ./start-thriftserver.sh #启动脚本 #netstat -ano|grep 10000 #查看是否启动,并监控10000端口

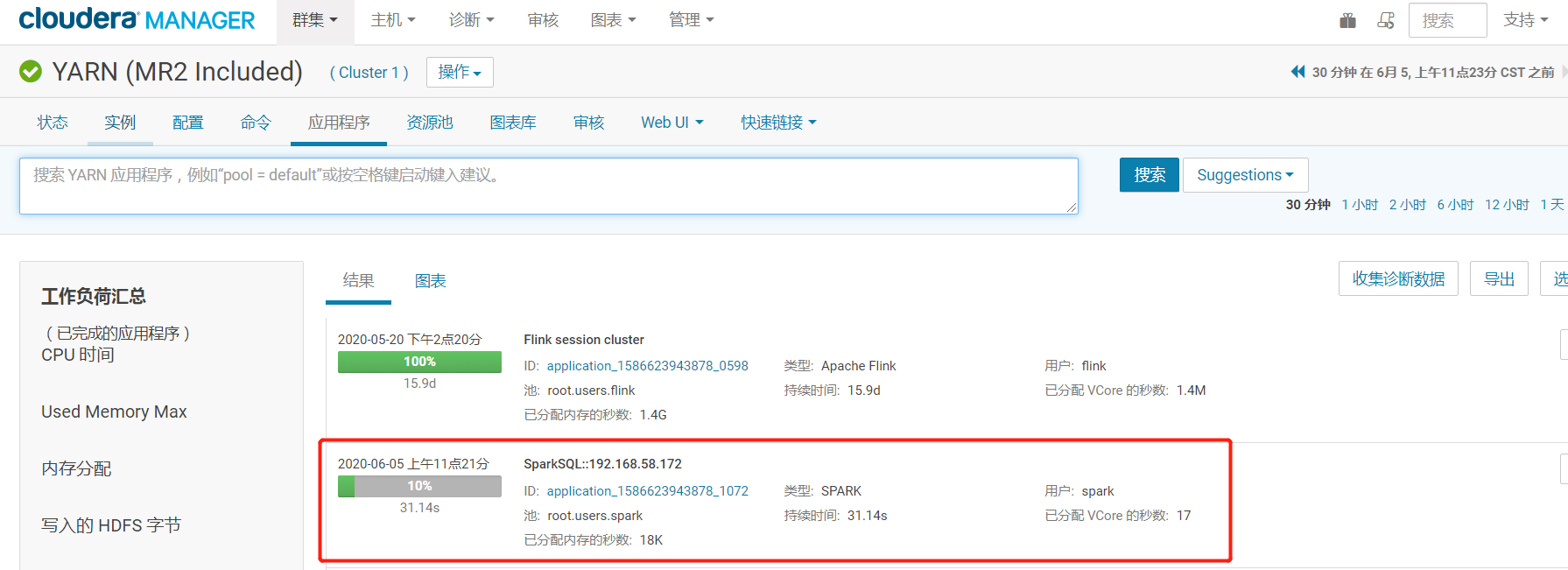
启动之后,在yarn上会有一个常驻进程,如下图:

二:运行SQL语句,并测试是否能成功运行
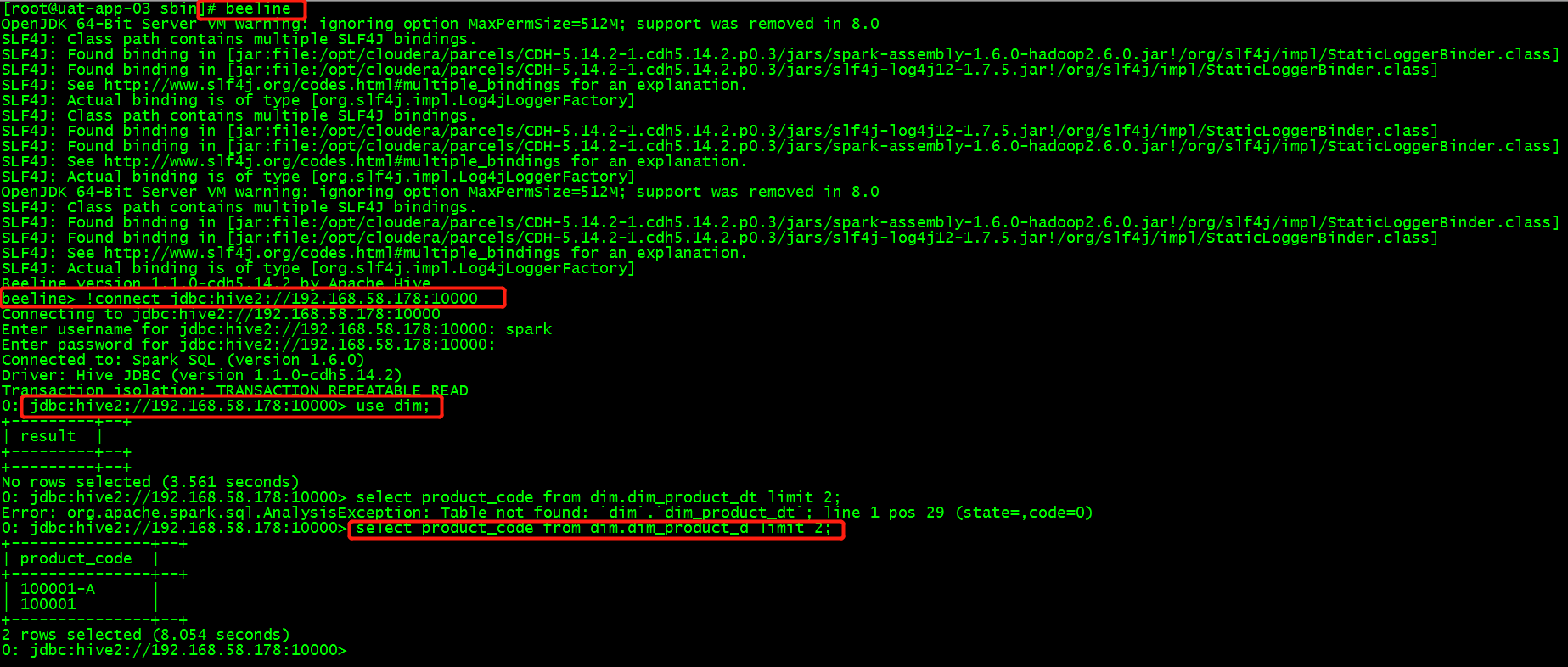
1.通过beeline链接spark 来运行sql
#beeline beeline> !connect jdbc:hive2://192.168.58.178:10000
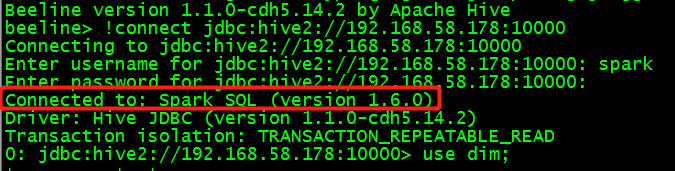
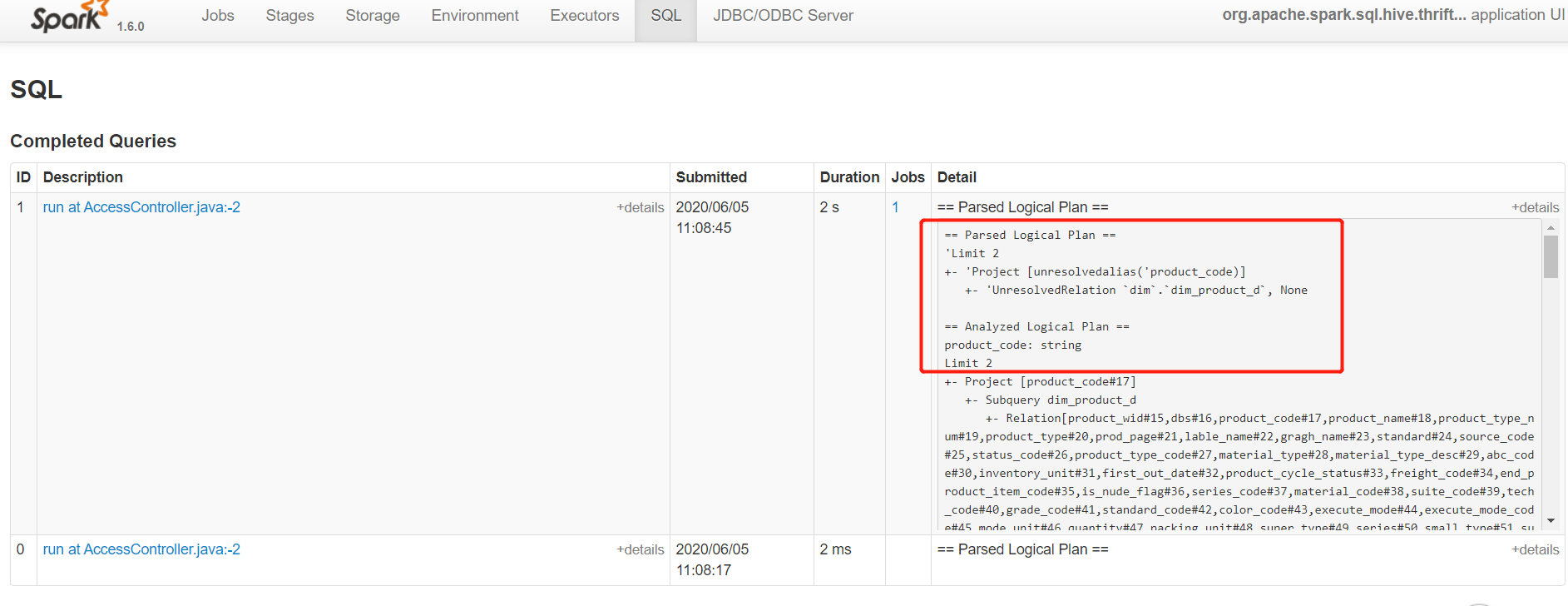
2.运行sql
0: jdbc:hive2://192.168.58.178:10000> use dim; 0: jdbc:hive2://192.168.58.178:10000> select product_code from dim.dim_product_d limit 2;
3.查看yarn上的任务情况
三:用bin/spark-sql来运行SQL
# sudo -u spark ./spark-sql

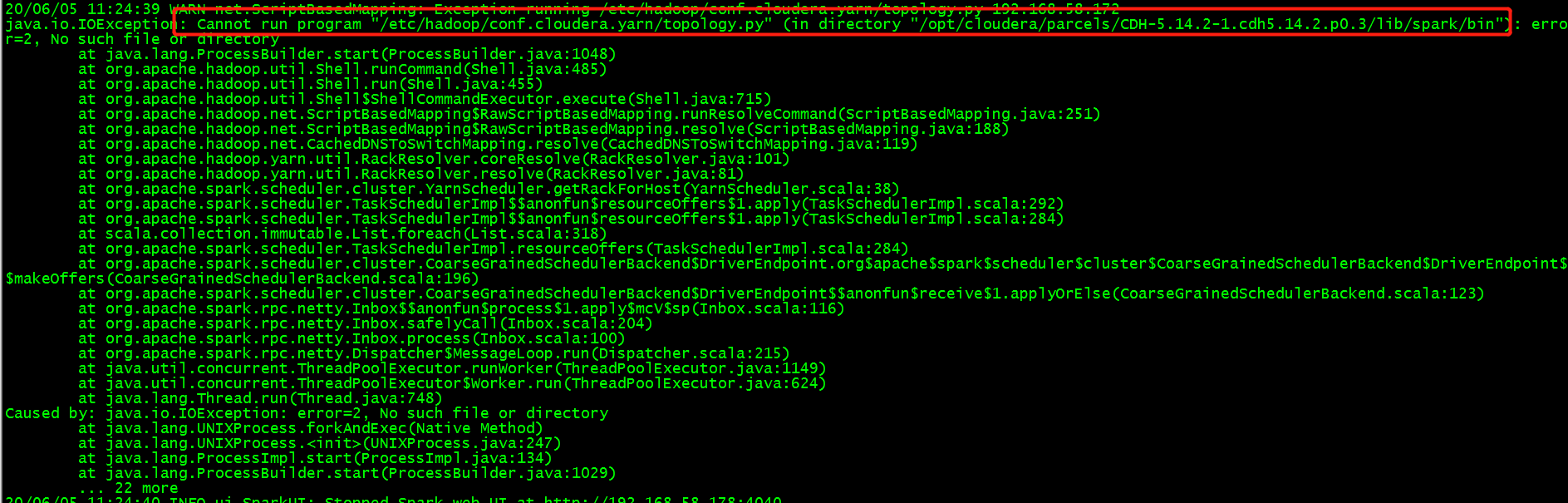
spark-sql 需要在有yarn上的机器上运行,不然会报一个错:
运行sql语句
spark-sql> select product_code from dim.dim_product_d limit 2;

总结:
- CDH默认不支持Spark Thrift,需要使用Spark原生的spark-assembly jar包替换CDH自带的jar包
- CDH5.11版本以后,Navigator2.10增加了Spark的血缘分析,所以需要将spark-lineage的jar加载的Spark的运行环境。否则连接Spark会报错找不到com.cloudera.spark.lineage.ClouderaNavigatorListener类。CDH5.10或之前版本不用加载这个jar包