第三篇:多维模型缓慢变化维技术
维度表的分类
-
类型0:原样保留
- 对于类型0来说,维度值不会发生变化。该类型适用于 日期维度的大多数属性。
-
类型1:重写
- 对于类型1来说,需要全量更新整个维度表,因此此种类型破坏了历史情况。无法对于历史情况进行跟踪。如City信息
例如:某个城市进行了更新,类型0会把最新的数据更新到DW库里去。这里在追中用户的City变化时,用的是CustomerID。

-
类型2:增加新行(一个典型代表的其实就是拉链表)
- 对于类型2来说,需要增加3个审计字段,已保持在跟事实表join的时候能取到最新的值。每次更新维度表中的值都要相应的变更3个审计字段。同时此种类型的维表主键需要更具通用性。因为表中会存在多行描述一个成员的情况。
- 增加行标识来标记这行记录是否有效,如:T/N
- 增加行开始时间/时间戳
- 增加行结束时间/时间戳
- 对于类型2来说,需要增加3个审计字段,已保持在跟事实表join的时候能取到最新的值。每次更新维度表中的值都要相应的变更3个审计字段。同时此种类型的维表主键需要更具通用性。因为表中会存在多行描述一个成员的情况。
例如:当City表中新增一行,这是customerid 会由原来的唯一键,变成有重复的记录。因为保留是历史记录的缘故。这是就需要在数据仓库层面给City表新增一个键。这个键在数据仓库的术语中叫做代理件。这时City表的主键就由customerid变为dwid了。

为什么使用代理件,有什么好处?
- 假设我们的业务数据库来自于不同的系统,对这些数据进行整合的时候有可能出现相同的 Business Key,这时通过 代理件(Surrogate Key)就可以解决这个问题。
- 一般来自业务数据库中的 Business Key 可能字段较长,比如 GUID,长字符串标识等,使用Surrogate Key 可以直接设置成整形的。事实表本身体积就很大,关联 Surrogate Key 与关联 Business Key 相比,Surrogate Key 效率更高,并且节省事实表体积。
- 最重要的一点就是上面举到的这个例子,使用 Surrogate Key 可以更好的解决这种缓慢渐变维度,维护历史信息记录。
按上面的表结构,光这样设置了新的 Surrogate Key - DWID 是不够的。所以现在还要新增3列,第一列是改行记录的生效时间,第二列是改行的失效时间,最后一列标识改行为当前可用。

-
类型3:增加新属性
- 简单来说就是添加新列来存放变化的值。此种方式一般不常用
-
类型4:增加微型维度
- 对于类型4,通常用于几百万行的维度表。简单理解,类似于雪花模型维度的设计理念。
-
类型5:增加微型维度及类型1支架
-
类型6:增加类型1属性到类型2维度
- 在保持类型2维度的基础上,改写所有与特定持久键关联的行
-
类型7:双类型1和类型2维度
拉链表的实现过程
假设有2张表,一张A表,是截止到昨天的全量数据。一张B表,是当天最新的数据。
2张表关联,能把数据分成3部分,插入一张临时表,记为表D
第一部分是A表中没有变化的部分,记为 O。
第二部分是交叉的部门,需要进行数据更新的。记为 U
第三部分是B表中剩下的数据,也就是新增的数据,记为 I。
如下图:
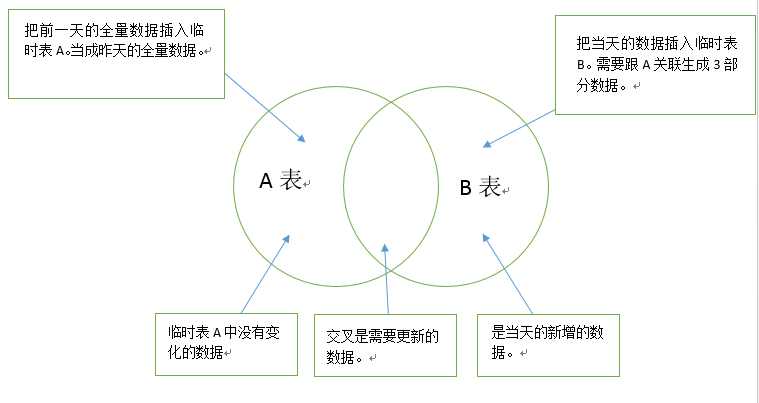
其中对D表中的I跟U进行处理,当被标识为 U的数据开始时间记为当前时间否则就记为‘1900-01-01’,结束时间记为‘9999-12-31’。并统一给标识位为'T'。记为表E
最后把数据整理完插入结果表F
第一部分:把E表新增及更新的数据,直接插入结果表F。
第二部分:把A表中原先有效的数据,变更为无效,并更新结束时间为当前时间。并给标识位为'F'。
第三部分:把A表跟E表关联,剔除E表中的数据,并且取出A表中标识位为'F'的数据,插入结果表F。
这样就完成整个拉链过程。如有疑问可在下方评论区进行交流。