约束 维护数据的完整性 数据的完整性用于确保数据库数据遵从一定的商业和逻辑规则(比如年纪不能为-1,性别不能为非男女),在oracle中,数据完整性可以使用约束、触发器、应用程序(过程、函数)三种方法来实现,在这三种方法中,因为约束易于维护,并且具有最好的性能,所以作为维护数据完整性的首选。 约束 约束用于确保数据库数据满足特定的商业规则。在oracle中,约束包括:not null、 unique, primary key, foreign key,和check五种。 使用 not null(非空) 如果在列上定义了not null,那么当插入数据时,必须为列提供数据。 unique(唯一) 当定义了唯一约束后,该列值是不能重复的,但是可以为null。 primary key(主键) 用于唯一的标示表行的数据,当定义主键约束后,该列不但不能重复而且不能为null。 需要说明的是:一张表最多只能有一个主键,但是可以有多个unqiue约束。 foreign key(外键) 用于定义主表和从表之间的关系。外键约束要定义在从表上,主表则必须具有主键约束或是unique约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null。 check 用于强制行数据必须满足的条件,假定在sal列上定义了check约束,并要求sal列值在1000-2000之间如果不在1000-2000之间就会提示出错。 商店售货系统表设计案例 现有一个商店的数据库,记录客户及其购物情况,由下面三个表组成:商品goods(商品号goodsId,商品名 goodsName,单价 unitprice,商品类别category,供应商provider); 客户customer(客户号customerId,姓名name,住在address,电邮email,性别sex,身份证cardId); 购买purchase(客户号customerId,商品号goodsId,购买数量nums); 请用SQL语言完成下列功能: 1. 建表,在定义中要求声明: (1). 每个表的主外键; (2). 客户的姓名不能为空值; (3). 单价必须大于0,购买数量必须在1到30之间; (4). 电邮不能够重复; (5). 客户的性别必须是 男 或者 女,默认是男; SQL> create table goods(goodsId char(8) primary key, --主键 goodsName varchar2(30), unitprice number(10,2) check(unitprice>0), category varchar2(8), provider varchar2(30) ); SQL> create table customer( customerId char(8) primary key, --主键 name varchar2(50) not null, --不为空 address varchar2(50), email varchar2(50) unique, sex char(2) default '男' check(sex in ('男','女')), -- 一个char能存半个汉字,两位char能存一个汉字 cardId char(18) ); SQL> create table purchase( customerId char(8) references customer(customerId), goodsId char(8) references goods(goodsId), nums number(10) check (nums between 1 and 30) ); 表是默认建在SYSTEM表空间的 维护 商店售货系统表设计案例(2) 如果在建表时忘记建立必要的约束,则可以在建表后使用alter table命令为表增加约束。但是要注意:增加not null约束时,需要使用modify选项,而增加其它四种约束使用add选项。 1. 增加商品名也不能为空 SQL> alter table goods modify goodsName not null; 2. 增加身份证也不能重复,给cardId增加一个唯一性约束 SQL> alter table customer add constraint 约束名称 unique(cardId); 3. 增加客户的住址只能是’海淀’,’朝阳’,’东城’,’西城’,’通州’,’崇文’,’昌平’; SQL> alter table customer add constraint 约束名称 check (address in (’海淀’,’朝阳’,’东城’,’西城’,’通州’,’崇文’,’昌平’)); 删除约束 当不再需要某个约束时,可以删除。 alter table 表名 drop constraint 约束名称; 特别说明一下: 在删除主键约束的时候,可能有错误,比如: alter table 表名 drop primary key; 这是因为如果在两张表存在主从关系,那么在删除主表的主键约束时,必须带上cascade选项 如像: alter table 表名 drop primary key cascade; 显示约束信息 1.显示约束信息 通过查询数据字典视图user_constraints,可以显示当前用户所有的约束的信息。 select constraint_name, constraint_type, status, validated from user_constraints where table_name = '表名'; 2.显示约束列 通过查询数据字典视图user_cons_columns,可以显示约束所对应的表列信息。 select column_name, position from user_cons_columns where constraint_name = '约束名'; 3.当然也有更容易的方法,直接用pl/sql developer查看即可。简单演示一下下... 表级定义 列级定义 列级定义 列级定义是在定义列的同时定义约束。 如果在department表定义主键约束(constraint pk_department primary key 为主键约束primary key取了一个名字pk_department,如果直接写dept_id number(12) primary key则会随机取一个名字) create table department4(
dept_id number(12) constraint pk_department primary key, name varchar2(12), loc varchar2(12)
); 表级定义 表级定义是指在定义了所有列后,再定义约束。这里需要注意: not null约束只能在列级上定义。 以在建立employee2表时定义主键约束和外键约束为例(pk_employee为约束名): create table employee2(
emp_id number(4), name varchar2(15), dept_id number(2),
constraint pk_employee primary key (emp_id), constraint fk_department foreign key (dept_id) references department4(dept_id)
);
Oracle索引、权限
索引需要另外存放,用于查找书籍。
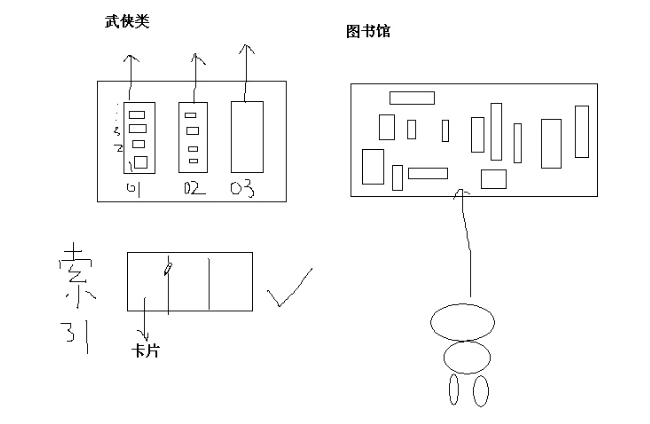
索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低i/o次数,从而提高数据访问性能。索引有很多种我们主要介绍常用的几种: 为什么添加了索引后,会加快查询速度呢? 创建索引 单列索引是基于单个列所建立的索引,比如: create index 索引名 on 表名(列名); 复合索引 复合索引是基于两列或是多列的索引。在同一张表上可以有多个索引,但是要求列的组合必须不同,比如: create index emp_idx1 on emp (ename, job); //相当于建立了书的小卡片,先按照ename去查再按照job去查 create index emp_idx1 on emp (job, ename); //先按照job去查再按照ename去查 使用原则 使用原则 1. 在大表上建立索引才有意义 2. 在where子句或是连接条件上经常引用的列上建立索引 3. 索引的层次不要超过4层 这里能不能给学生演示这个效果呢? 如何构建一个大表呢? 索引的缺点 索引缺点分析 索引有一些先天不足: 1. 建立索引,系统要占用大约为表1.2倍的硬盘和内存空间来保存索引。 2. 更新数据的时候,系统必须要有额外的时间来同时对索引进行更新,以维持数据和索引的一致性。 实践表明,不恰当的索引不但于事无补,反而会降低系统性能。因为大量的索引在进行插入、修改和删除操作时比没有索引花费更多的系统时间。 比如在如下字段建立索引应该是不恰当的: 1. 很少或从不引用的字段; 2. 逻辑型的字段,如男或女(是或否)等(因为男女就2种,即使经常用到也不加索引,比如书籍就文学类和理工类,那么就不必要做一个卡片区分文学还是理工)。 综上所述,提高查询效率是以消耗一定的系统资源为代价的,索引不能盲目的建立,这是考验一个DBA是否优秀的很重要的指标。
其它索引 按照数据存储方式,可以分为B*树、反向索引、位图索引; 按照索引列的个数分类,可以分为单列索引、复合索引; 按照索引列值的唯一性,可以分为唯一索引和非唯一索引。 此外还有函数索引,全局索引,分区索引... 对于索引我还要说: 在不同的情况,我们会在不同的列上建立索引,甚至建立不同种类的索引,请记住,技术是死的,人是活的。比如: B*树索引建立在重复值很少的列上,而位图索引则建立在重复值很多、不同值相对固定的列上。 显示索引信息 显示表的所有索引 在同一张表上可以有多个索引,通过查询数据字典视图dba_indexs和user_indexs,可以显示索引信息。其中dba_indexs用于显示数据库所有的索引信息,而user_indexs用于显示当前用户的索引信息: select index_name, index_type from user_indexes where table_name = '表名'; 显示索引列 通过查询数据字典视图user_ind_columns,可以显示索引对应的列的信息 select table_name, column_name from user_ind_columns where index_name = 'IND_ENAME'; 你也可以通过pl/sql developer工具查看索引信息