卡方检验-考察分类变量相关性-“交叉表”或“设定表”中进行;
t检验-考察连续变量与分类变量相关性-“设定表”中进行;
线性logsitic回归-研究分类因变量与一组自变量(可连续可分类)的关系;
树结构模型-研究自变量间是否存在交互作用
广义线性模型-在更广范畴建立模型。
1、案例背景
收集脑外伤急救病例样本,分析哪些因素导致急救后的脑损伤发生。因变量:是否出现迟发性脑损伤,为两分类变量;自变量:有连续性变量、分类变量。
卡方检验:研究分类变量之间的关系;
由于因变量是两分类变量,所以不能用普通的线性回归或方差分析,所以建立logistic回归模型;
考虑到自变量间的交互作用,采用分类树模型。
2、数据理解
变量关联的图表描述:
连续变量分布情况
分析-描述统计-描述,再画堆积直方图和分组箱图进行数据展示。如下:
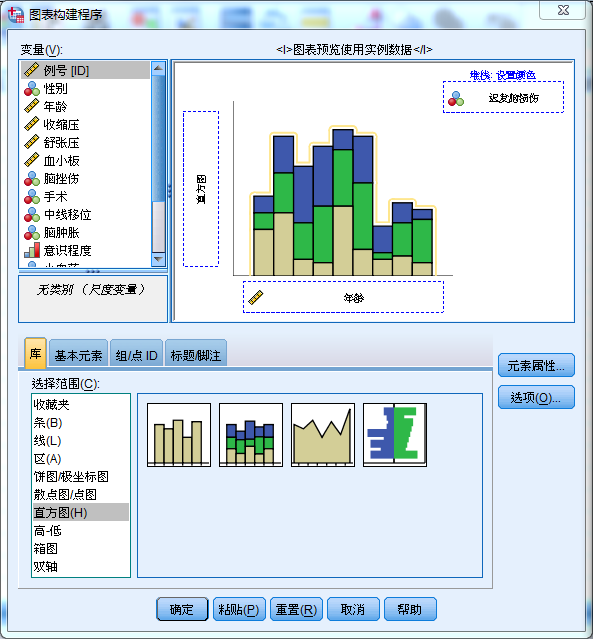

分类变量间联系的表格描述
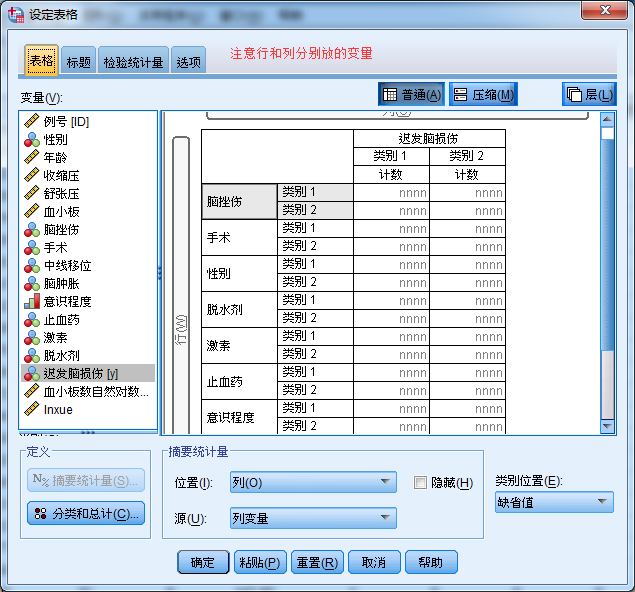
分析-表-设定表
变量关联的单变量检验:
考察分类自变量的作用
研究分类因变量和分类自变量的关系,使用卡方检验,原假设:因变量与自变量相互独立。使用卡方检验有两种方法:一种是“交叉表”,分别看全部两个分类变量的关系;一种是制表过程中的“设定表”,将分类因变量与各个分类自变量的关系在一张表中全部显示出来。第一种方法有些繁琐,常用第二种方法。
注:从经验上讲,一般单变量分析时P值小于0.2的变量可以考虑在随后的多变量建模中继续加以考察,P值高于0.2的除非在专业上有很明确的意义,否则不做考察。
方法一:
方法二:
考察连续自变量的作用
研究分类因变量和连续自变量的关系,建立logistic回归模型。但建模前进行预分析考察因变量和自变量之间的关系是否具有统计意义,有一种方法是连续因变量与分类自变量互换,进行t检验。同样在指标过程中完成,具体操作如下:

3、构建二分类logistic回归模型
当因变量是分类变量时,使用多元线性回归模型拟合得到的实际上是因变量某个类别的发生概率。由于模型等式左侧的概率取值范围是(0,1),但右侧是(负无穷,正无穷),等式左右不匹配。而且概率与自变量的关系常常不是线性的。这对这两个问题,需要进行logit变换。
logit(P)=ln(p/(1-p))。对logit(P)建立线性回归模型,这就是logistic回归模型。
logistic回归模型是研究分类因变量的标准建模方法。
logistic回归模型的适用条件
因变量为二分类的分类变量或某事件的发生率,因变量要服从二项分布;
自变量与logit(P)之间为线性关系;
残差合计为0,且服从二项分布;
各观测对象相互独立。
由于logistic模型的残差为二项分布而不是正态分布,所以使用的是极大似然估计来解决方程的估计和检验问题。
logistic模型为发生概率预测模型。
初步尝试建模
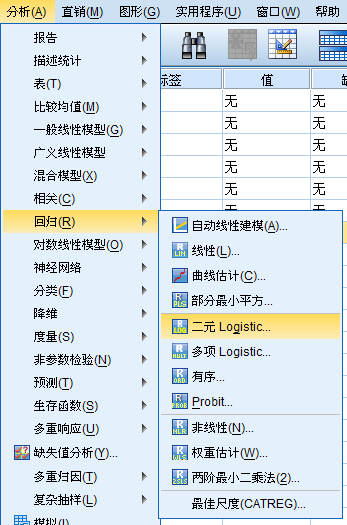
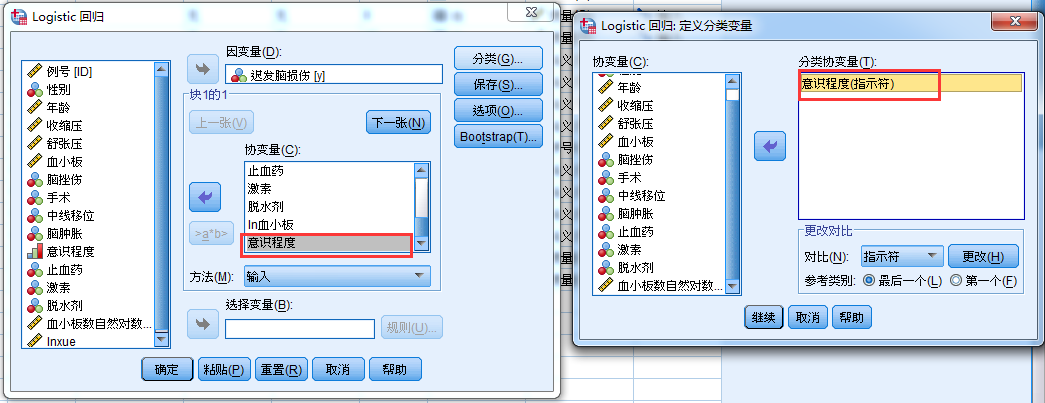
对于结果的具体解释间P172。有些难度,好好理解。
构建最终模型
通过对构建的初步模型中变量的显著性检验,最终引入3个变量(舒张压、激素、ln血小板)建立最终的logistic回归模型。
4、利用树模型发现交互项
在上节最终构建的模型存在两个问题,logitP与自变量的关系一定是线性的吗?有没有是曲线的可能?各自变量间存在交互作用吗?
解决办法:树结构模型提供了解决自变量交互作用、曲线关联问题,成为补充经典建模方法缺陷的一种有效工具。
树模型的基本思想:将总研究人群通过某些特征(自变量取值)分成数个相对同质的亚人群,群内因变量的取值高度一致,相应的变异/杂质尽量落在不同亚人群中。
根据因变量的类型(分类或连续),树结构模型分为分类树和回归树。
进行树模型分析
在本案例中,选择CRT算法,同时输出对候选自变量的重要性分析。具体操作如下:
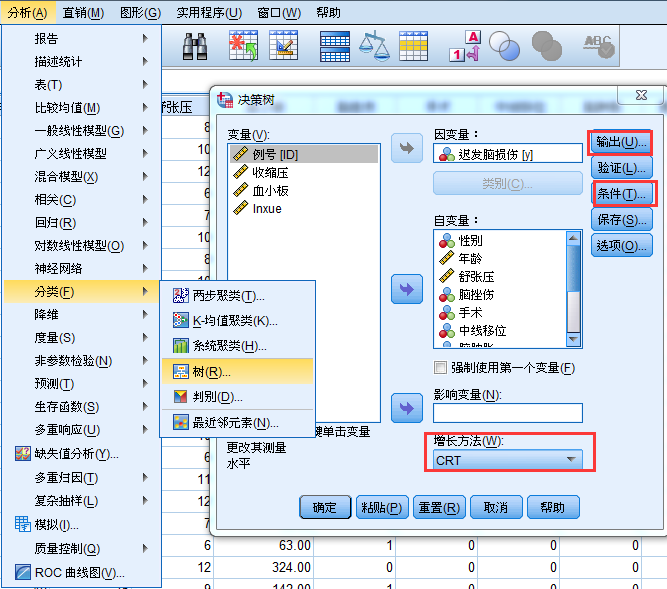
分析结果显示,舒张压与血小板自然对数存在交互作用,且进行了候选自变量的重要性排序分析。
5、使用广义线性过程进行分析
舒张压与血小板自然对数的交互项=手工建立一个新变量为上述两变量的乘积,加入模型进行分析。
logistic回归模型属于广义线性模型范畴,所以利用广义线性模型过程来完成。
广义线性模型扩展了一般线性模型,差别在:
广义线性模型的因变量分布从正态分布扩展到二项分布、泊松分布等指数分布簇;通过连接函数,把因变量期望值与自变量的线性部分取值连接起来。
构建仅包含主效应的模型(即不包括交互项):
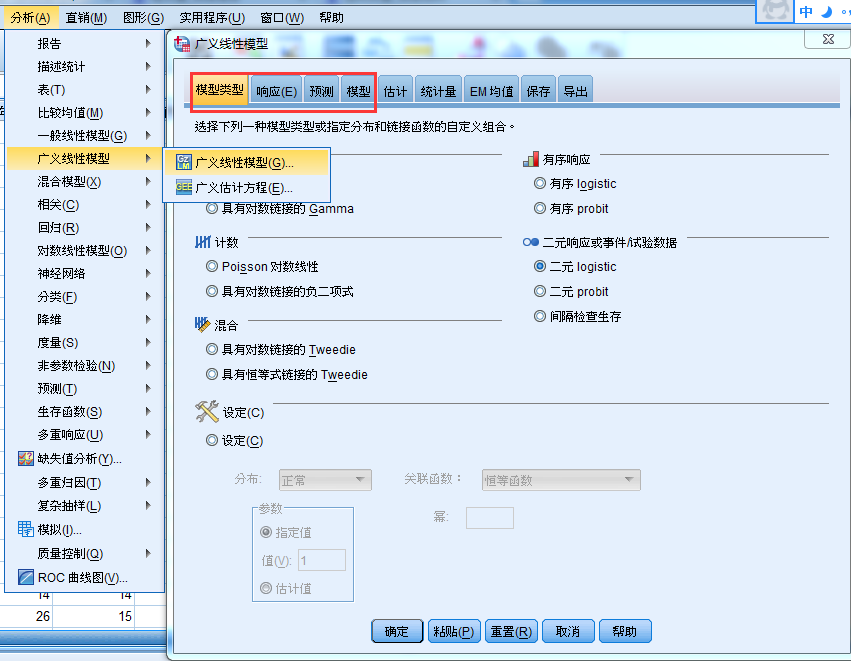
在模型中加入交互项:
通过“计算变量”得到舒张压与血小板自然对数的乘积,在按上述步骤加入交互项信息。