转自:http://my.oschina.net/hncscwc/blog/186350?p=1
1. 镜像队列的设置
镜像队列的配置通过添加policy完成,policy添加的命令为:
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition: 镜像定义,包括三个部分 ha-mode,ha-params,ha-sync-mode
ha-mode: 指明镜像队列的模式,有效值为 all/exactly/nodes
all表示在集群所有的节点上进行镜像
exactly表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params: ha-mode模式需要用到的参数
ha-sync-mode: 镜像队列中消息的同步方式,有效值为automatic,manually
Priority: 可选参数, policy的优先级
例如,对队列名称以hello开头的所有队列进行镜像,并在集群的两个节点上完成镜像,policy的设置命令为:
rabbitmqctl set_policy hello-ha "^hello" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
2. 镜像队列的大概实现
(1) 整体介绍
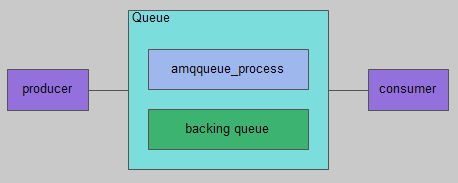
通常队列由两部分组成:一部分是amqqueue_process,负责协议相关的消息处理,即接收生产者发布的消息、向消费者投递消息、处理消息confirm、acknowledge等等;另一部分是backing_queue,它提供了相关的接口供amqqueue_process调用,完成消息的存储以及可能的持久化工作等。
镜像队列同样由这两部分组成,amqqueue_process仍旧进行协议相关的消息处理,backing_queue则是由master节点和slave节点组成的一个特殊的backing_queue。master节点和slave节点都由一组进程组成,一个负责消息广播的gm,一个负责对gm收到的广播消息进行回调处理。在master节点上回调处理是coordinator,在slave节点上则是mirror_queue_slave。mirror_queue_slave中包含了普通的backing_queue进行消息的存储,master节点中backing_queue包含在mirror_queue_master中由amqqueue_process进行调用。
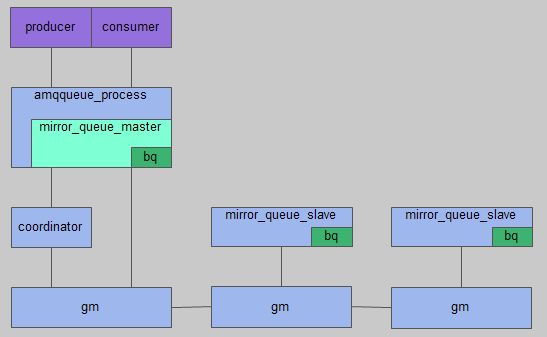
注意:消息的发布与消费都是通过master节点完成。master节点对消息进行处理的同时将消息的处理动作通过gm广播给所有的slave节点,slave节点的gm收到消息后,通过回调交由mirror_queue_slave进行实际的处理。
(2) gm(Guaranteed Multicast)
传统的主从复制方式:由master节点负责向所有slave节点发送需要复制的消息,在复制过程中,如果有slave节点出现异常,master节点需要作出相应的处理;如果是master节点本身出现问题,那么slave节点间可能会进行通信决定本次复制是否继续。当然为了处理各种异常情况,整个过程中的日志记录是免不了的。
然而rabbitmq中并没有采用这种方式,而是将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上;当有节点失效时,相邻的节点会接管保证本次广播的消息会复制到所有节点。
在master节点和slave节点上的这些gm形成一个group,group的信息会记录在mnesia中。不同的镜像队列形成不同的group。
消息从master节点对应的gm发出后,顺着链表依次传送到所有节点,由于所有节点组成一个循环链表,master节点对应的gm最终会收到自己发送的消息,这个时候master节点就知道消息已经复制到所有slave节点了。
(3) 重要的表结构
rabbit_queue表记录队列的相关信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
-record(amqqueue,{name, %%队列的名称durable, %%标识队列是否持久化auto_delete, %%标识队列是否自动删除exclusive_owner, %%标识是否独占模式arguments, %%队列创建时的参数pid, %%amqqueue_process进程PIDslave_pids, %%mirror_queue_slave进程PID集合sync_slave_pids, %%已同步的slave进程PID集合policy, %%与队列有关的policy %%通过set_policy设置,没有则为undefinedgm_pids, %%{gm,mirror_queue_coordinator},{gm,mirror_queue_slave}进程PID集合decorator %%}). |
注意:slave_pids的存储是按照slave加入的时间来排序的,以便master节点失效时,提升"资格最老"的slave节点为新的master。
gm_group表记录gm形成的group的相关信息:
|
1
2
3
4
5
6
|
-record(gm_group,{name, %%group的名称,与queue的名称一致version, %%group的版本号, 新增节点/节点失效时会递增members, %%group的成员列表, 按照节点组成的链表顺序进行排序}). |
3. 镜像队列的一些细节
(1) 新增节点
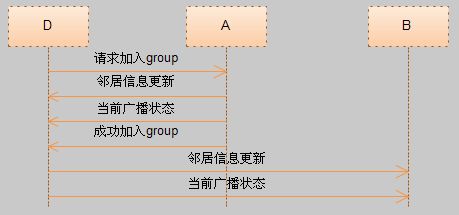
slave节点先从gm_group中获取对应group的所有成员信息,然后随机选择一个节点并向这个节点发送请求,这个节点收到请求后,更新gm_group对应的信息,同时通知左右节点更新邻居信息(调整对左右节点的监控)及当前正在广播的消息,然后回复通知请求节点成功加入group。请求加入group的节点收到回复后再更新rabbit_queue中的相关信息,并根据需要进行消息的同步。
(2) 消息的广播
消息从master节点发出,顺着节点链表发送。在这期间,所有的slave节点都会对消息进行缓存,当master节点收到自己发送的消息后,会再次广播ack消息,同样ack消息会顺着节点链表经过所有的slave节点,其作用是通知slave节点可以清除缓存的消息,当ack消息回到master节点时对应广播消息的生命周期结束。
下图为一个简单的示意图,A节点为master节点,广播一条内容为"test"的消息。"1"表示消息为广播的第一条消息;"id=A"表示消息的发送者为节点A。右边是slave节点记录的状态信息。

为什么所有的节点都需要缓存一份发布的消息呢?
master发布的消息是依次经过所有slave节点,在这期间的任何时刻,有可能有节点失效,那么相邻的节点可能需要重新发送给新的节点。例如,A->B->C->D->A形成的循环链表,A为master节点,广播消息发送给节点B,B再发送给C,如果节点C收到B发送的消息还未发送给D时异常结束了,那么节点B感知后节点C失效后需要重新将消息发送给D。同样,如果B节点将消息发送给C后,B,C节点中新增了E节点,那么B节点需要再将消息发送给新增的E节点。
gm的状态记录:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
-record(state,{self, %%gm本身的IDleft, %%该节点左边的节点right, %%该节点右边的节点group_name, %%group名称 与队列名一致module, %%回调模块 rabbit_mirror_queue_slave或者 %%rabbit_mirror_queue_coordinatorview, %%group成员列表视图信息 %%记录了成员的ID及每个成员的左右邻居节点pub_count, %%当前已发布的消息计数members_state, %%group成员状态列表 记录了广播状态:[#member{}]callback_args, %%回调函数的参数信息 %%rabbit_mirror_queue_slave/rabbit_mirror_queue_coordinator进程PIDconfirms, %%confirm列表broadcast_buffer, %%缓存待广播的消息broadcast_timer, %%广播消息定时器txn_executor }).-record(member,{pending_ack, %%待确认的消息,也就是已发布的消息缓存的地方last_pub, %%最后一次发布的消息计数last_ack %%最后一次确认的消息计数}). |
(3) 节点的失效
当slave节点失效时,仅仅是相邻节点感知,然后重新调整邻居节点信息、更新rabbit_queue、gm_group的记录等。如果是master节点失效,"资格最老"的slave节点被提升为master节点,slave节点会创建出新的coordinator,并告知gm修改回调处理为coordinator,原来的mirror_queue_slave充当amqqueue_process处理生产者发布的消息,向消费者投递消息等。

上面提到如果是slave节点失效,只有相邻的节点能感知到,那么master节点失效是不是也是只有相邻的节点能感知到?假如是这样的话,如果相邻的节点不是"资格最老"的节点,怎么通知"资格最老"的节点提升为新的master节点呢?
实际上,所有的slave节点在加入group时,mirror_queue_slave进程会对master节点的amqqueue_process进程(也可能是mirror_queue_slave进程)进行监控,如果master节点失效的话,mirror_queue_slave会感知,然后再通过gm进行广播,这样所有的节点最终都会知道master节点失效。当然,只有"资格最老"的节点会提升自己为新的master。
另外,在slave提升为master时,mirror_queue_slave内部来了一次"偷梁换柱",即原本需要回调mirror_queue_slave的handle_call/handle_info/handle_cast等接口进行处理的消息,全部改为调用amqqueue_process的handle_call/handle_info/handle_cast等接口,从而可以解释上面说的,mirror_queue_slave进程充当了amqqueue_process完成协议相关的消息的处理。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
rabbit_mirror_queue_slave.erlhandle_call({gm_deaths,LiveGMPids},From, State = #state{q = Q = #amqqueue{name=QName,pid=MPid}})-> Self = self(), case rabbit_mirror_queue_misc:remove_from_queue(QName, Self, LiveGMPids) of {ok,Pid,DeadPids} -> case Pid of MPid -> %% master hasn't changed gen_server2:reply(From, ok), noreply(State); Self -> %% we've become master QueueState = promote_me(From,State), {become, %% 改由rabbit_amqqueue_process模块处理消息 rabbit_amqqueue_process, QueueState, hibernate}; ...gen_server2.erlhandle_common_reply(Reply,Msg,GS2State = #gs2_state{name=Name, debug=Debug})-> case Reply of ... {become, Mod, NState, Time1} -> Debug1=common_become(Name,Mod,NState,Debug), loop(find_prioritisers( GS2State#gs2_state{mod=Mod, state=NState, time=Time1, debug=Debug1})); ...handle_msg({'gen_call',From,Msg}, GS2State=#gs2_state{mod=Mod, state=State, name=Name, debug=Debug}) -> case catch Mod:handle_call(Msg, From, State) of ...handle_msg(Msg,GS2State=#gs2_state{mod=Mod,state=State})-> Reply = (catch dispatch(Msg,Mod,State)), handle_common_reply(Reply, Msg, GS2State).dispatch({'$gen_cast',Msg},Mod,State)-> Mod:handle_cast(Msg, State);dispatch(Info, Mod, State)-> Mod:handle_info(Info,State). |
(4) 消息的同步
配置镜像队列的时候有个ha-sync-mode属性,这个有什么用呢?
新节点加入到group后,最多能从左边节点获取到当前正在广播的消息内容,加入group之前已经广播的消息则无法获取到。如果此时master节点不幸失效,而新节点有恰好成为了新的master,那么加入group之前已经广播的消息则会全部丢失。
注意:这里的消息具体是指新节点加入前已经发布并复制到所有slave节点的消息,并且这些消息还未被消费者消费或者未被消费者确认。如果新节点加入前,所有广播的消息被消费者消费并确认了,master节点删除消息的同时会通知slave节点完成相应动作。这种情况等同于新节点加入前没有发布任何消息。
避免这种问题的解决办法就是对新的slave节点进行消息同步。当ha-sync-mode配置为自动同步(automatic)时,新节点加入group时会自动进行消息的同步;如果配置为manually则需要手动操作完成同步。