深拷贝浅拷贝是个很容易迷糊的问题,本人帮你彻底搞清楚。
粗识内存
本人没学过c,内存略懂,有堆栈之分,
栈可以理解为程序自动分配的内存,堆可以理解为程序员对内存的引用,不重要,有感觉就行。
浅拷贝
浅拷贝并不是我们认知中的“复制”,浅拷贝只是对象的引用,是对一个对象的浅层拷贝,所以叫浅拷贝
或者说是顶层拷贝,只拷贝了引用,没拷贝内容
示例代码
import copy a = [1, 2, [3, 4]] b = copy.copy(a) print('b:', b) # ('b:', [1, 2, [3, 4]]) b.append(5) b[2].append(6) print('a:', a) # ('a:', [1, 2, [3, 4, 6]]) print('b:', b) # ('b:', [1, 2, [3, 4, 6], 5])
为什么这样呢?

b是a的浅拷贝,对b的操作不会影响a,但是对b内元素操作会影响a,因为ab指向的是同一个元素
b只拷贝了a的第一层,所以叫浅拷贝
print(id(a)) # 40641880 print(id(b)) # 40667616 b新建了一个对象 print(id(a[2])) # 40643080 print(id(b[2])) # 40643080 b中元素仍是a中元素
深拷贝
深拷贝才是我们认知中的“复制”,深拷贝是完全拷贝,是对一个对象的深层拷贝,所以叫深拷贝。
示例代码
import copy a = [1, 2, [3, 4]] b = copy.deepcopy(a) print('b:', b) # ('b:', [1, 2, [3, 4]]) b.append(5) b[2].append(6) print('a:', a) # ('a:', [1, 2, [3, 4]]) print('b:', b) # ('b:', [1, 2, [3, 4, 6], 5])
好理解了
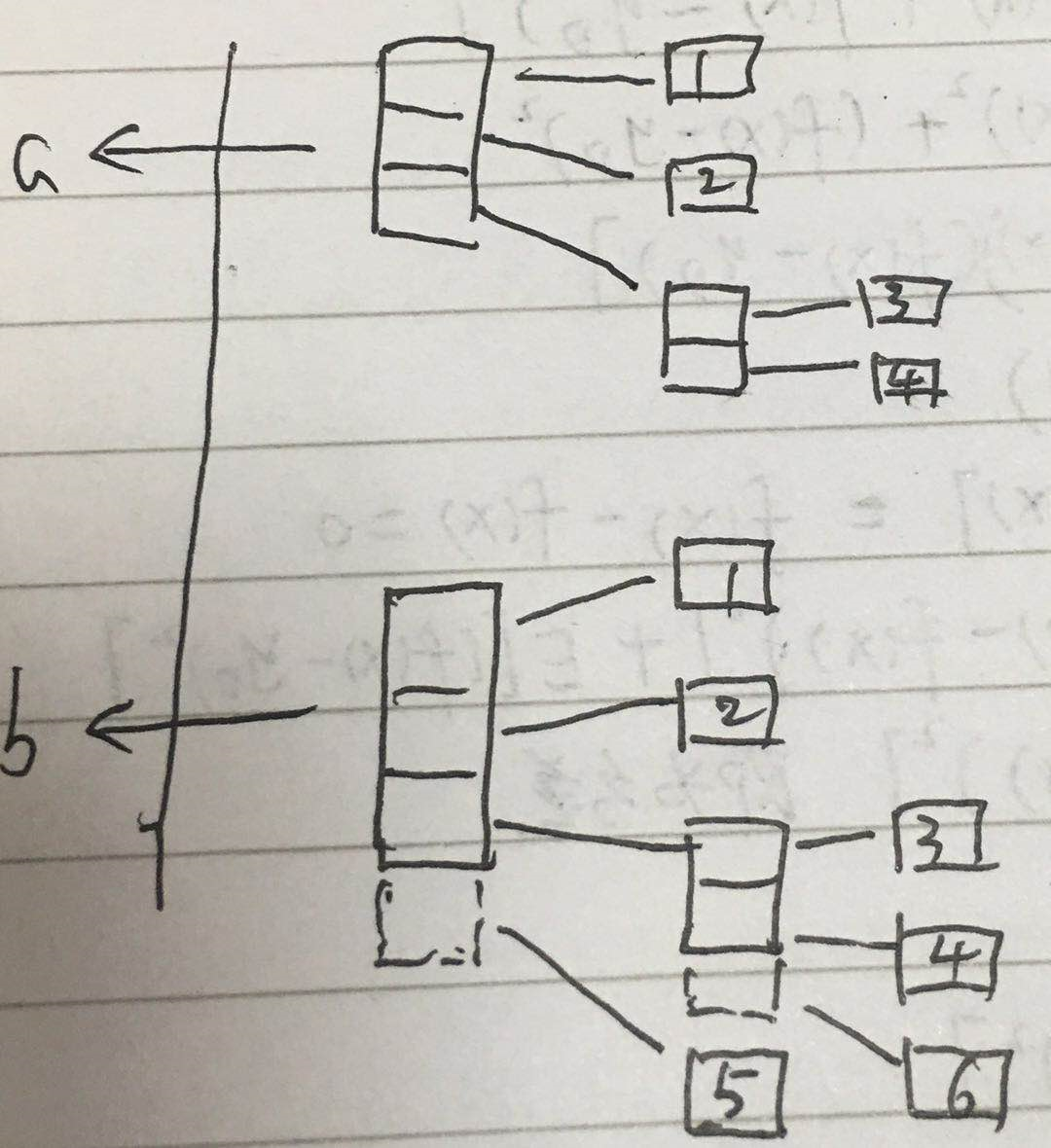
互不影响
b拷贝了a的所有层,所以叫深拷贝
print(id(a)) # 41624920 print(id(b)) # 41648496 b新建了一个对象 print(id(a[2])) # 41626120 print(id(b[2])) # 41648456 b中元素不是a中元素
可以看到深拷贝和浅拷贝都新建了一个对象。
等于
那等于是什么?深拷贝?浅拷贝?都不是,等于才是真正的复制。
示例代码
a = [1, 2, [3, 4]] b = a print('b:', b) # ('b:', [1, 2, [3, 4]]) b.append(5) b[2].append(6) print('a:', a) # ('a:', [1, 2, [3, 4, 6], 5]) print('b:', b) # ('b:', [1, 2, [3, 4, 6], 5]) print(id(a)) # 40510648 print(id(b)) # 40510648 b没有新建对象 print(id(a[2])) # 40490568 print(id(b[2])) # 40490568 b中元素仍是a中元素
互相影响,因为是同一个对象

所以 复制 != 拷贝
好了,终于明白了,真的吗?
看个实例
jack = ['jack', ['age', 20]] tom = jack[:] anny = list(jack) print id(jack), id(tom), id(anny) # 144846988 144977164 144977388
3个不同的对象
tom[0] = 'tom' anny[0] = 'anny' print jack, tom, anny # ['jack', ['age', 20]] ['tom', ['age', 20]] ['anny', ['age', 20]]
可以理解
anny[1][1] = 18 print jack, tom, anny # ['jack', ['age', 18]] ['tom', ['age', 18]] ['anny', ['age', 18]]
请问,还理解吗?
分析:上面是新建了3个对象,那么只能是深拷贝或浅拷贝中的一种,改了名字互不影响,应该是深拷贝,但是改了年龄互相影响,又不是深拷贝,那是浅拷贝?也不对啊,迷糊了
[id(x) for x in jack] # [3073896320L, 3073777580L] [id(x) for x in tom] # [144870744, 3073777580L] [id(x) for x in anny] # [144977344, 3073777580L]
可以看到名字id不同,年龄id相同
为什么会这样呢?
因为python中字符串是不可变类型,其被修改时,必须新建一个对象,这就明白了,就是浅拷贝,年龄指向了同一个id,但是因为名字修改时重新创建了对象, 所以指向了不同的id
那我们在上面浅拷贝的例子上验证下
b[2] = 3 print('a:', a) # ('a:', [1, 2, [3, 4, 6]]) print('b:', b) # ('b:', [1, 2, 3, 5])
果然改变了b[2],新建了个对象,a[2]并没有改变
如果用深拷贝就没有上面的问题
jack = ['jack', ['age', '20']] import copy tom = copy.deepcopy(jack) anny = copy.deepcopy(jack) # 根据第一个思路进行重命名,重定岁数操作: tom[0] = 'tom' anny[0] = 'anny' print jack, tom, anny # ['jack', ['age', '20']] ['tom', ['age', '20']] ['anny', ['age', '20']] anny[1][1] = 18 print jack, tom, anny # ['jack', ['age', '20']] ['tom', ['age', '20']] ['anny', ['age', 18]]
总结
切片操作和工厂方法list方法拷贝是浅拷贝,而且一般情况下都是浅拷贝
深拷贝浅拷贝需要考虑数据是否是可变类型