一、项目背景
缓存:我们在开发中,常会遇到一个问题,就是要不要将数据放在服务器的系统缓存中。如果在服务器中存放了很多缓存数据,虽然能加快读取数据的速度,但是这将耗费昂贵的并且是有限的服务器内存资源,从而有可能我们不得不升级服务器的配置,但是公司也不一定会同意或者愿意花费这个代价。如果减少服务器的缓存数据,那么在程序需要用到这些数据时,我们将要连接数据库去查询这些热点数据,加大了IO操作,这又会浪费数据库的资源,降低了用户体验度。然而用户体验度往往是检验我们程序好坏的直接标准。
响应时间:有时候用户在进行某些操作时,服务器需要长时间的计算,用户直接的感觉就是卡顿,甚至是卡死。可能是代码写的不好,也可能是业务确实复杂需要很大的计算量。花钱升级服务器确实是能缓解一下这个问题,可是我们回想一下12306火车票订票系统,他们的服务器已经够强大了,可是在前几年照样还是容易卡死,所以说升级服务器配置这个方案不是首选。
协同作业:多线程一起工作,这些线程可能不在一个程序内,甚至不在一个服务器上,而这些线程需要共享一些数据。是将这些缓存数据放在数据库,还是将这些数据用http方式传输到另外一台服务器,还是将其他系统的某些功能继承到当前系统中,这些都是问题。
高峰期:我们服务器在高分期时可能要处理大量的请求或者要计算大量的任务。这时服务器表现就不够好,可是在大部分时间里面,服务器都是比较空闲的,我们真的需要为了这个短短的高分期阶段去升级服务器配置或者多加服务器?
以上几个问题都可以用Redis来解决。Redis数据库在软件系统中扮演着重要的角色,特别是在分布式缓存中,Redis的名头可是响当当的,并且他优越的性能也让人刮目相看。
开发中经常用到Redis,如果对每个系统都开发对Redis的封装,既耗时耗力,又容易出错。于是想开发一个通用的Redis操作工具包。该软件包包含了各个系统的对Redis的常用操作。在企业中,有很多的业务系统需要开发,例如在开发.Net项目时,我们只需要引用相关dll文件就可以省去开发人员的很多工作量,也减少了后期运维成本。
本篇主要介绍Redis在企业架构中具体能起到什么作用,能解决哪些问题,以及我们该如何设计一个通用的Redis类库 。
二、Redis封装设计
关于Redis数据库的访问方法代码网上有很多,一搜一大把。这里就不再贴代码,只讲设计,以下是我所做的通用Redis操作类库设计图:
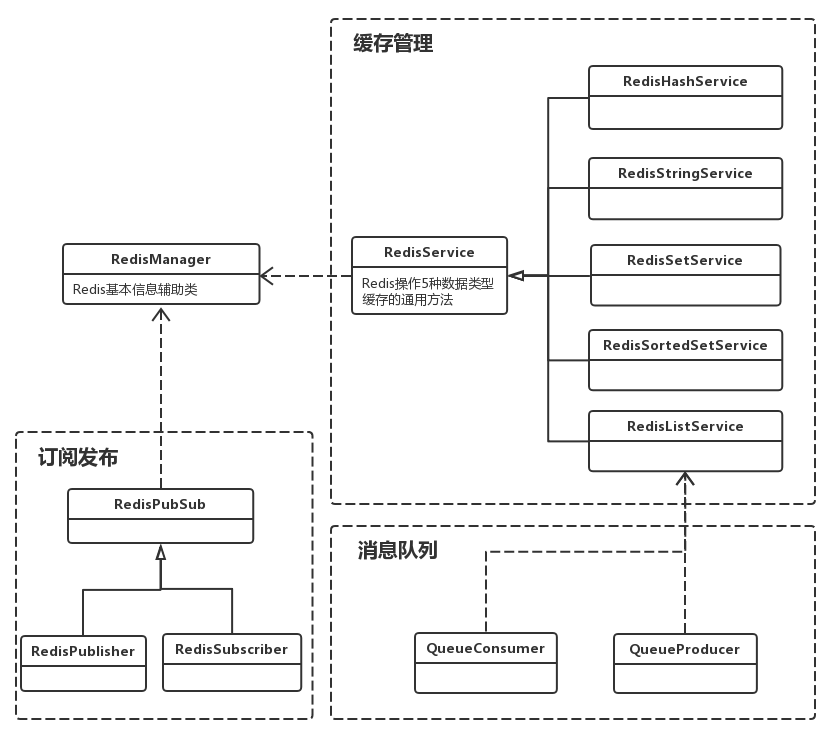
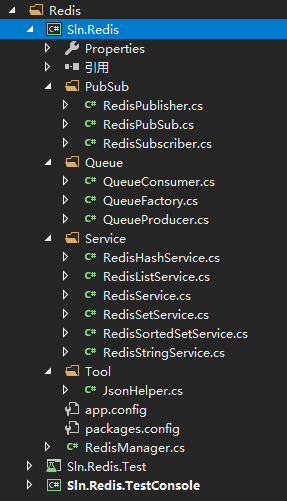
以及代码结构图:
三、分布式缓存
我们是不是在开发中遇到过这样的一种情况,就是我们要经常查询字典表,有些公司叫做代码表,也就是说热点数据。可是系统中,不仅仅代码表是热点数据,还有很多数据是热点数据,可是这些数据不能全部放在缓存中,要不然内存会爆掉。所以只有牺牲性能来妥协服务器的有限的内存资源。
Redis作为一个高性能的NoSql存储数据库,完美的解决了这一问题,并且可以跨进程进行数据共享。一个很简单的例子--单点登录(SSO),一个地方登陆,多个系统共享登陆信息。单点登录可以解决各个系统的登录问题,不管系统是Java、.Net(web,wpf,winform),移动端(IOS、安卓),都可以使用同一个标准的单点登录,统一企业开发规范,这里就不多说了。以后有机会和大家分享单点登录的设计及代码。
关于Redis的代码简单,网上有很多。下面只提供了Redis缓存设计图,希望对各位有用。

四、发布订阅及消息队列
Redis也提供了消息队列的功能。其中的发布订阅,以及用List实现的消息队列都是可以用的,如果不想用ActiveMQ、kafka、RabbitMQ等技术,可以考虑Redis。
消息队列可以将任务分发到多台服务器上执行,也可以将任务暂时放在队列里面,等服务器不是那么忙的时候再处理这些任务,这样就可以减轻高峰期时对服务器的压力。
五、Redis五种数据结构
1、String 字符串
字符串类型是redis最基础的数据结构。key-value 键值对:value可以是序列化后的数据。字符串类型可以是简单的字符串、json字符串、xml字符串等。
2、Hash 哈希
Hash:类似dictionary,通过索引快速定位到指定元素的,耗时均等,跟string的区别在于不用反序列化,直接修改某个字段。
在存储数据上,String的存储方式一般有两种:
a) 001:序列化整个实体 ;
b) 001_name:zhangsan 、 001_pwd:123456 等多个key-value;
而Hash的存储方式为一个hashid-{key:value;key:value;key:value;},这样的存储方式可以一次性查找实体,也可以单个,还可以单个修改。
3、List 列表
Redis List的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。Redis内部针对List进行了很多的实现,包括发送缓冲队列等也都是用的这个数据结构,一般是左进右出或者右进左出。因此我们可以借用List做出异步消息队列。
4、Set 集合
集合类型也是用来保存多个字符串的元素,但和列表不同的是集合中不允许有重复的元素,并且集合中的元素是无序的,不能通过索引下标获取元素,redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,并合理的使用好集合类型,能在实际开发中解决很多实际问题。
标签(tag)就是集合类型比较典型的使用场景。例如一个用户对娱乐、体育比较感兴趣,另一个可能对新闻感兴 趣,这些兴趣就是标签,有了这些数据就可以得到同一标签的人,以及用户的共同爱好的标签,这些数据对于用户体验以及曾强用户粘度比较重要(用户和标签的关系维护应该放在一个事物内执行,防止部分命令失败造成数据不一致)。
我们可以思考一下共同好友在关系型数据库该如何设计,我是想了很久,但是没有满意的解决方案。然而用Redis Set,却可以很方便并且快速的完成,这就大大的降低的开发的难度,也提高了用户体验度。
5、SortedSet 有序集合
有序集合和集合有着很大的联系,他保留了集合不能有重复成员的特性,并且在有序集合中的元素是可以排序的。但是它和列表的排序依据不同,列表使用索引下标作排序,有序集合使用元素的分值排序。(有序集合中的元素不可以重复,但是玄素的分值可以重复,就像是一个班里的同学学号不能重复,但考试成绩可以相同)。
列表、集合、有序集合三者的异同点
| 数据结构 | 是否重复 | 是否有序 | 序列实现方式 | 应用场景 |
| List | Y | Y | 索引下标 | 消息队列 |
| Set | N | N | 无 | 标签、共同好友 |
| SortedSet | N | Y | 分值 | 排行榜 |
排行榜是有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。