集合框架可以分为两个部分:Collection和Map,详细的框架图如下:
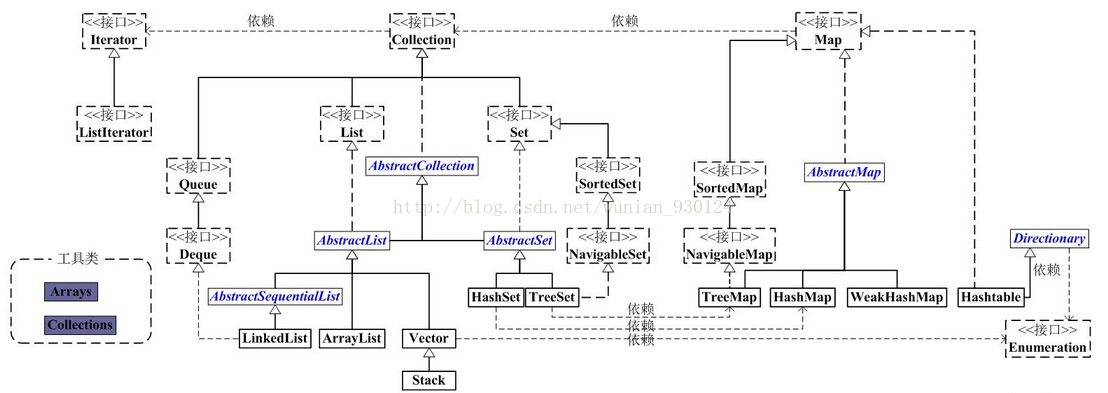
我们先来分析一下Collection集合框架,Collection包括两大体系List和Set,其中List中的元素存取有序、元素可重复、有索引,可以根据索引获取值,Set的元素存取无序、不能存储重复元素。
List下面有有三个实现类ArrayList、vector、LinkedList,ArrayList和Vector底层是数组,LinkedList底层实现是链表。
ArrayList和Vector底层是数组实现,能够根据索引直接获取值,所以查找快,但是删除和添加操作慢,因为需要向前或向后挪动多个元素。Vector是旧版本的,线程安全,所以如果是单线程进行存取,最好用ArrayList,效率快,如果是多线程我们最好用Vector来进行存储,因为Vector里面的方法是线程安全的。
LinkedList是基于链表实现的,查找必须从头开始,所以查找速度慢,但是删除和添加只需要挪动两个节点,所以删除和添加速度快。链表提供了特殊的方法,所以链表可以实现栈或者队列。
Set接口有三个实现类HashSet、LinkedHashSet、TreeSet
HashSet集合存储不重复,无序,原理是什么?因为HashSet底层实现是哈希表,哈希表通过hashCode()和equals()方法来共同保证元素不重复。首先根据存储的元素算出hashCode值,然后根据算出的hashCode值和数组的长度算出存储的下标;如果下标位置无元素,那么直接存储,如果有元素,那么就要使用存入的元素和已经存在的元素进行equals方法进行比较,如果结果为真就不存储,如果为假就进行存储,以链表方式进行存储。
注意:一般我们自定义的类都需要重新写hashCode()和equals(),必须要重写Object类的这两个方法,因为hash值是根据存储的元素获得的
如:
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
LinkedHashSet基于链表和哈希表实现的,所以具有存取有序,元素唯一的特点。
package cn.yqg.day4;
public class Person {
private int age ;
private String name;
public Person(int age,String name) {
this.age=age;
this.name=name;
}
@Override
public String toString() {
return "Person [age=" + age + ", name=" + name + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
package cn.yqg.day4;
import java.util.Iterator;
import java.util.LinkedHashSet;
public class Test {
public static void main(String[] args) {
LinkedHashSet<Person> list=new LinkedHashSet<>();
list.add(new Person(1,"12"));
list.add(new Person(1,"12"));
list.add(new Person(3,"14"));
list.add(new Person(4,"15"));
Iterator<Person> it=list.iterator();
while(it.hasNext()) {
Person p=it.next();
System.out.println(p);
}
}
}
运行结果:
Person [age=1, name=12]
Person [age=3, name=14]
Person [age=4, name=15]
TreeSet:特点存取无序,元素唯一,可以进行排序;TreeSet是基于二叉树实现。
存储过程:如果是第一个元素,直接存入,作为根节点,下一个元素进来就会进行比较,如果大于加点就放在节点右边,如果小于节点就放在节点左边,等于节点就不存储,后面的元素会依次进行比较直到有存储的位置为止。
package cn.yqg.day4;
import java.util.TreeSet;
public class Test2 {
public static void main(String[] args) {
TreeSet<String> set=new TreeSet<>();
set.add("abd");
set.add("abc");
set.add("bcd");
set.add("bce");
set.add("bce");
for(String str : set) {
System.out.println(str);
}
}
}
运行结果:
abc
abd
bcd
bce
TreeSet保证元素唯一有两种方式:
1.自定义对象实现Comparable()接口,重写CompareTo()方法,该方法返回0表示相等,大于0表示存入的元素比被比较的元素大。反之小于0。
2.在创建TreeSet的时候向构造器中传入比较器Comparator接口实现类的对象,实现Comparator接口重写compare方法。
如果向TreeSet中存储自定义类没实现Comparable接口,或者没有传入Comparator比较器时,会出现ClassCastException异常。
下面演示用两种方式存储自定义对象
package cn.yqg.day4;
import java.util.TreeSet;
public class Test4 {
public static void main(String[] args) {
TreeSet<Person> treeSet=new TreeSet<>();
treeSet.add(new Person(4,"1"));
treeSet.add(new Person(1,"张三"));
treeSet.add(new Person(1,"李四"));
treeSet.add(new Person(3,"大王"));
treeSet.add(new Person(2,"小王"));
treeSet.add(new Person(3,"大王"));
treeSet.add(new Person(4,"1"));
treeSet.add(new Person(4,"1"));
for(Person p : treeSet) {
System.out.println(p);
}
}
}
package cn.yqg.day4;
public class Person implements Comparable<Person>{
private int age ;
private String name;
public Person(int age,String name) {
this.age=age;
this.name=name;
}
@Override
public String toString() {
return "Person [age=" + age + ", name=" + name + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public int compareTo(Person o) {
int rusult=this.age-o.age;
if(rusult==0) {
return this.name.compareTo(o.name);
}
return rusult;
}
}
另一种方式:使用比较器Comparator
package cn.yqg.day4;
import java.util.Comparator;
import java.util.TreeSet;
public class Test5 {
public static void main(String[] args) {
TreeSet<Person2> treeSet2=new TreeSet<>(new Comparator<Person2>() {
@Override
public int compare(Person2 o1, Person2 o2) {
if(o1==o2) {
return 0;
}
int result=o1.getAge()-o2.getAge();
if(result==0) {
return o1.getName().compareTo(o2.getName());
}
return result;
}
});
treeSet2.add(new Person2(1,"张三"));
treeSet2.add(new Person2(5,"小龙"));
treeSet2.add(new Person2(4,"3"));
treeSet2.add(new Person2(5,"小庆"));
treeSet2.add(new Person2(4,"1"));
treeSet2.add(new Person2(1,"1"));
for(Person2 p : treeSet2) {
System.out.println(p);
}
}
}
package cn.yqg.day4;
public class Person2 {
private int age ;
private String name;
public Person2(int age,String name) {
this.age=age;
this.name=name;
}
@Override
public String toString() {
return "Person [age=" + age + ", name=" + name + "]";
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
运行结果:
Person [age=1, name=1]
Person [age=1, name=张三]
Person [age=4, name=1]
Person [age=4, name=3]
Person [age=5, name=小庆]
Person [age=5, name=小龙]
-------------------------------------------------------------------------------------------------------------------
Collection体系总结:
List:“特点”,存取有序,可存重复值,元素有索引。
ArrayList:数组结构,查询速度快,增删慢,线程不安全,效率高。
Vector:数组结构,查询快,增删慢,线程安全,效率低。
LinkedList:链表结构,增删快,查询慢,线程不安全,效率高。
Set:“特点”,存取无序,不可存重复值,无索引。
HashSet:哈希表,存储无序,元素不重复,无索引。
LinkedHashSet:链表加哈希表,存储有序,无索引,值不重复。
TreeSet:二叉树,元素不重复,存取无序,但是可以进行排序。
两种排序方式:
1.自然排序:我们的元素必须实现Comparable接口,实现CompareTo()方法。
2.比较器排序:我们自定义的类实现Comparator接口,比较器实现Compare方法。然后创建TreeSet的时候把比较器对象当做参数传递给TreeSet。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
现在我们来看看Map集合框架
Map是一个双列集合,保存的是键值对,键要求保持唯一性,值可以重复。键值一一对应。Map存储是将键值传入Entry,然后存储Entry对象。
Map接口实现类有三个,分别为HashMap、TreeMap、LinkedHashMap。
HashMap:是基于hash表实现的,所以存储自定义对象作为键时,必须重写hashCode和equals方法。存取无序
package cn.yqg.day4;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map.Entry;
import java.util.Set;
public class Test6 {
public static void main(String[] args) {
HashMap<Person,String> map=new HashMap<Person,String>();
map.put(new Person(1,"pp"),"java");
map.put(new Person(2,"kk"),"c");
map.put(new Person(1,"pp"),"c++");
map.put(new Person(3,"ll"),"java");
Set<Entry<Person,String>> entrySet=map.entrySet();
Iterator<Entry<Person,String>> it=entrySet.iterator();
while(it.hasNext()) {
Entry<Person,String> entry=it.next();
System.out.println(entry.getKey()+"-----"+entry.getValue());
}
}
}
结果:
Person [age=1, name=pp]-----c++
Person [age=3, name=ll]-----java
Person [age=2, name=kk]-----c
我们发现如果键重复,后面的值会覆盖前面的值。存取无序。
LinkedHashMap:用法基本和HashMap一致,基于链表和哈希表来实现的,所以有存取有序,键不重复的特点。
package cn.yqg.day4;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map.Entry;
public class Test7 {
public static void main(String[] args) {
LinkedHashMap<Person,String> map=new LinkedHashMap<Person,String>();
map.put(new Person(1,"pp"),"java");
map.put(new Person(2,"kk"),"c");
map.put(new Person(1,"pp"),"c++");
map.put(new Person(1,"pp"),"R");
for(Entry<Person,String> entry : map.entrySet()) {
System.out.println(entry.getKey()+"-----"+entry.getValue());
}
}
}
实现结果:
Person [age=1, name=pp]-----R
Person [age=2, name=kk]-----c
我们注意到键如果相同,值会被后面的覆盖掉。而且存取有序。
TreeMap集合存储自定义对象,自定义对象始终作为TreeMap的key值,由于TreeMap底层实现是二叉树,所有存进去的数据都要进行排序,排序有两种方法,一种自定义类实现Comparable接口,实现CompareTo方法,另一种实现Comparator接口,实现自定义比较器Compare方法。
package cn.yqg.day4;
import java.util.Comparator;
import java.util.TreeMap;
import java.util.Map.Entry;
public class Test8 {
public static void main(String[] args) {
TreeMap<Person,String> map=new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
if(o1==o2) {
return 0;
}
int result=o1.getAge()-o2.getAge();
if(result==0) {
result=o1.getName().compareTo(o2.getName());
}
return result;
}
});
map.put(new Person(1,"pp"),"java");
map.put(new Person(2,"kk"),"c");
map.put(new Person(6,"pp"),"c++");
map.put(new Person(0,"pp"),"R");
map.put(new Person(-7,"pp"),"jsp");
map.put(new Person(0,"pp"),"js");
for(Entry<Person,String> entry : map.entrySet()) {
System.out.println(entry.getKey()+"-----"+entry.getValue());
}
}
}
运行结果:
Person [age=-7, name=pp]-----jsp Person [age=0, name=pp]-----js Person [age=1, name=pp]-----java Person [age=2, name=kk]-----c Person [age=6, name=pp]-----c++