自动编码器
encoder和decoder没办法单独训练,但接在一起就可以做无监督学习。
中间压缩了维度的隐藏层叫做bottleneck layer(像颈部一样比较细),两边的权重通常互为转置(可以减少参数量,但不是必须这样的)。
中间的维度肯定是要小于input的,是需要做一下压缩的,不然网络直接把input复制过来,输出output,就得到正确结果了,这样的网络是没有用的。

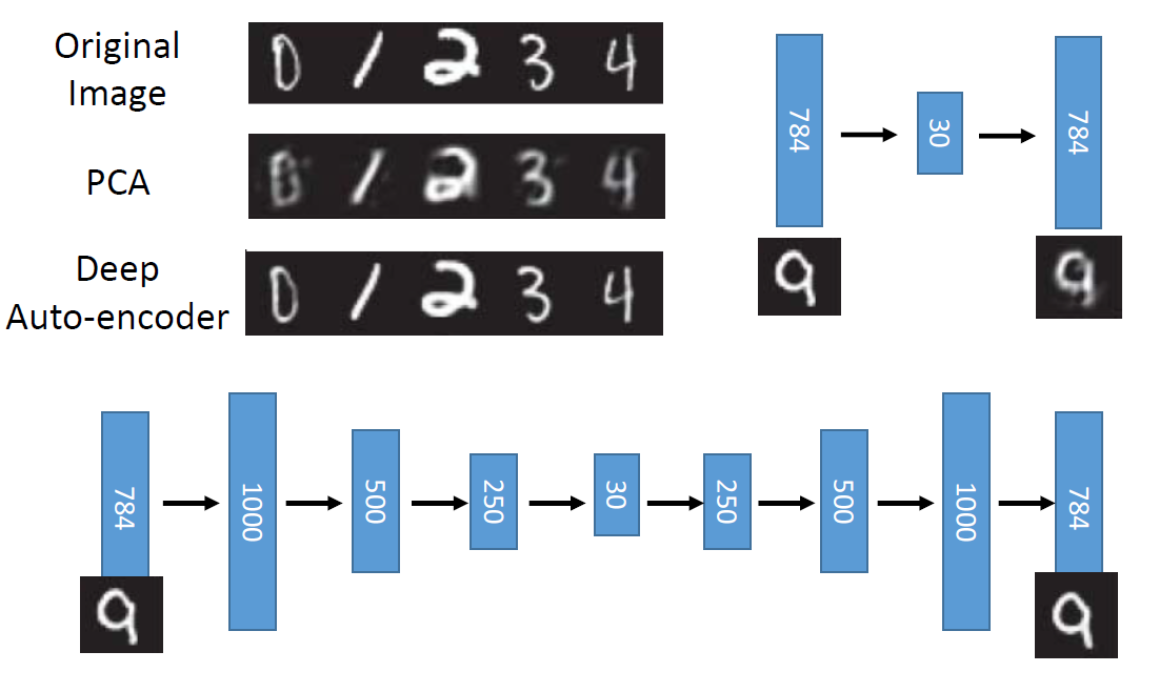
也可以用深度神经网络。

用自编码器的效果好于PCA。


对于文本检索来说,就是求query和document向量之间的内积,得到最相近的结果。而表示文章的方法就是用词袋模型,不过词袋模型不会考虑语义信息。
用自编码器的话,同类的文章会成为一簇,查询的时候可以得到同类的结果,即使这个文章和查询没有词汇关联。但用LSA的话就得不到这样的结果。

对于图像搜索,同样,计算像素之间的相似度的话,得到的结果会很糟糕。而用自编码器的话,结果还不错。

如果下一层的维度更大的话,那么需要做一下regularization,其中某几维是可以有值的,其他维要必须为0。
如果说有很多的unlabeled data,少量的labeled data,可以把网络参数用无监督的方法训练好,然后用labeled data微调。
去噪自编码器会给input添加一些噪声,最后的结果和添加噪声前的做比对。这样除了能学到特征,还能把噪声去掉。
contractive auto-encoder的思路类似,是让input的变化对code的影响最小。

用CNN自编码器的话,就是在decoder这边做deconvolution和unpooling的操作。

反池化:在做池化操作的时候记住取最大值的位置,然后反池化的时候其他位置补0。或者做复制。

反卷积:反卷积和卷积是一样的操作。在旁边补一些0,就可以实现。

假如有一张图,中间2维的隐藏层sample出来是这样的,然后等间隔地去sample vector出来,通过decoder看看会产生什么。
那么怎么知道哪个位置生成出来的是图呢?
有一个很简单的做法,就是在你的code上面加regularization(L2 regularization),让code比较接近0。
你在sample的时候就是在0附近,这样你就可以有可能sample出的vector都能对应到数字。

横轴(从左到右)代表的是有没有一个圈圈(本来是一个很圆的圈圈,慢慢的变为1),纵轴代表是:本来是直的,然后慢慢就倒斜。

