课程名称:深度学习与人类语言处理(Deep Learning for Human Language Processing)
(自然语言包括文本和语音两种形式,不过自然语言处理大多时候指的是文本处理,所以这门课的名字叫人类语言处理以便区分,因为这门课语音和文本的内容是1:1的)
人类语言处理的终极目标:让机器能够听懂人说的话,看懂人写的句子,并有能力说出人听得懂的话,写出人看得懂的句子。
世界上只有56%的语言有文字形式,而且有些语言的文字系统未必被人们广泛使用(不如语音直接)。所以语音也是非常重要的,而且语音这部分不仅仅只有语音识别任务。
人类语言处理的困难之处:
1秒的语音有16K个采样点,每个点包含256个可能的取值。
而且没有人能够说同一段话两次,而语音的波形相同的。
而且一句话其实是可以无限长的。

人类语言处理包含的任务:
虽然人类语言处理的任务比较难,不过在深度学习中方法却比较简单,如下图所示(图中的Model就是Deep Network),各种问题硬train一发就能搞定。
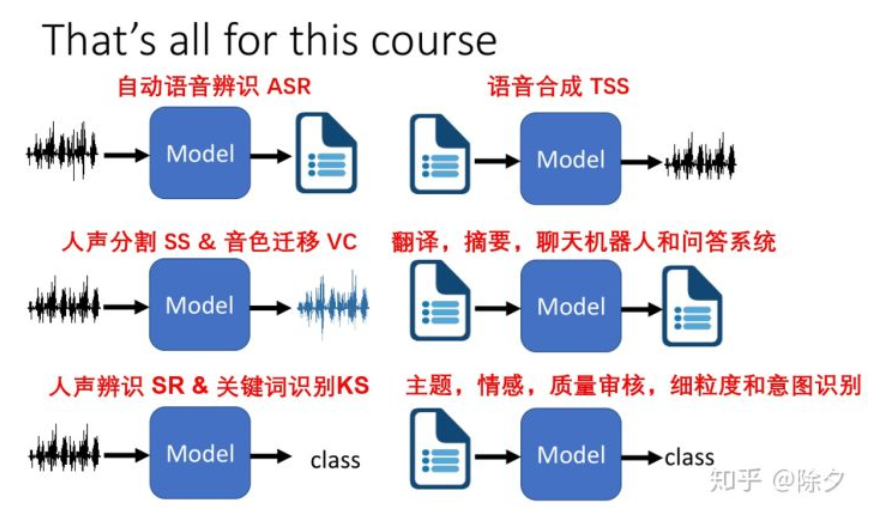
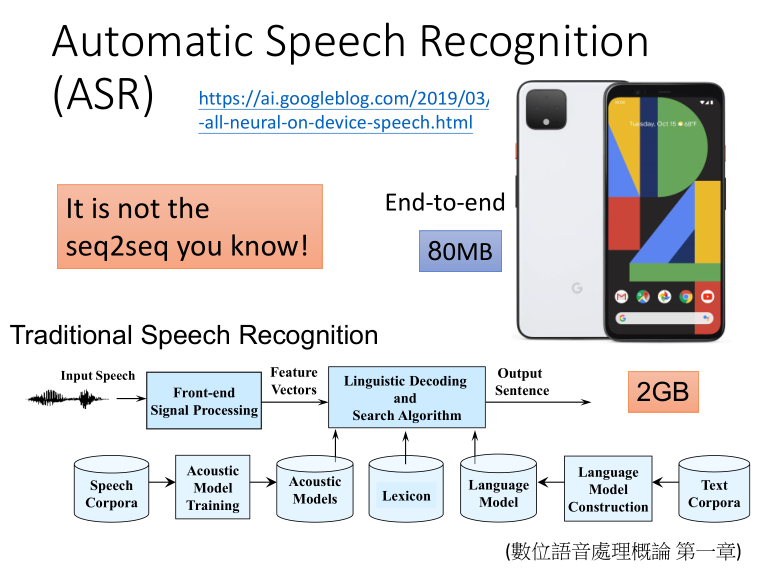
自动语音识别ASR:
传统的语音识别,包含前端信号处理、声学模型、语言模型还有词典等,要把这些部分都学通,较为复杂,而且模型通常需要2G大小,比较大。
而目前的End-to-End的模型,只需要80MB,可以运行在手机上。
语音合成TSS:
在课程视频里演示的语音合成案例里,下图的不同长短的“发财”它的语调居然都是不同的,而这些都是模型自己学出来的(很神奇)。
不过这种黑盒算法也会有一些问题,虽然对于长句效果很好,不过对于短词效果较差(数据问题,训练数据中短句或者单词较少),比如谷歌历史上的翻译破音问题。

语音转换:人声分割SS和音色迁移VC:
人声分割:就是把一段语音中混合的不同声音分离出来(End-to-End的模型直接就能做,傅里叶变换都不需要)。
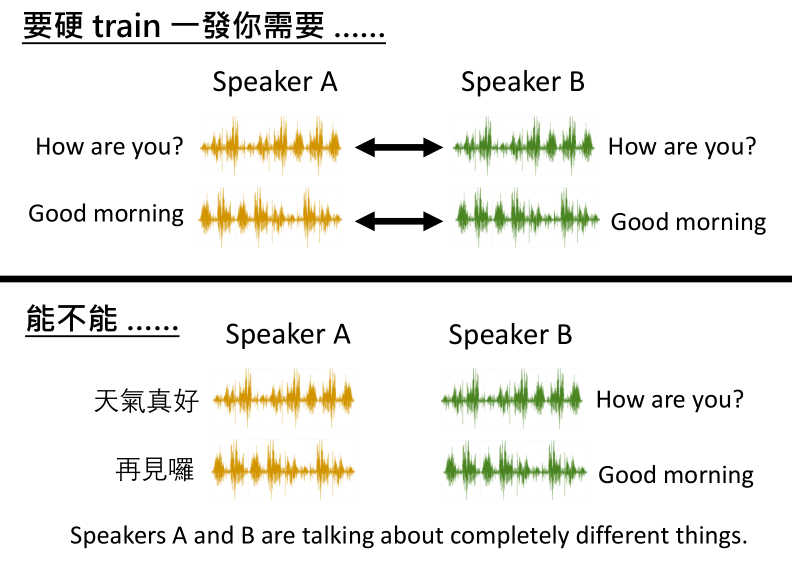
音色迁移:就是把一个人说过的话做音色迁移,输出的结果听起来像是由另外一个人说出来的。甚至还可以输出完全不同的内容。
语音分类:人声辨识SR和关键词识别KS:
人声辨识:判断语音是谁说的,
关键词辨识:判断语音中是否出现了关键词。比如唤醒词,Hi, Siri.
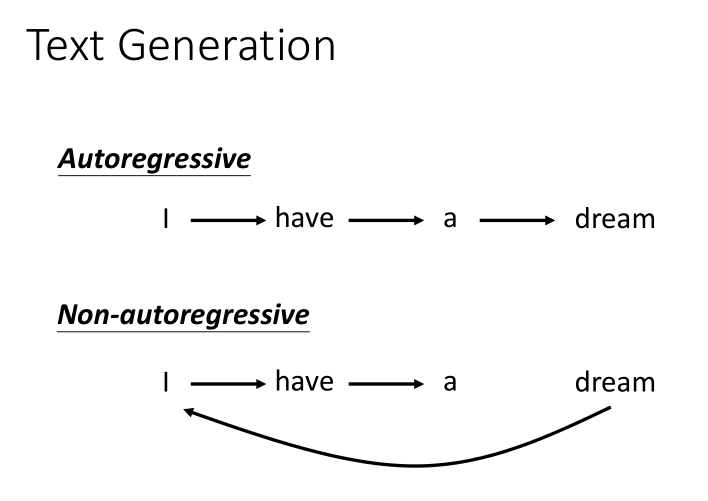
文本生成:
生成方式:自回归(逐个生成)和非自回归。
应用包括翻译、摘要、聊天机器人、自动问答等。
此外,本门课程还会讲Meta Learning,知识图谱,对抗攻击,可解释AI等内容。
