1.我们在使用spark计算的时候,操作数据集的感觉很方便是因为spark帮我们封装了一个rdd(弹性分布式数据集Resilient Distributed Dataset);
那么rdd数据本身是如何存储的呢,又是如何调度读取的?
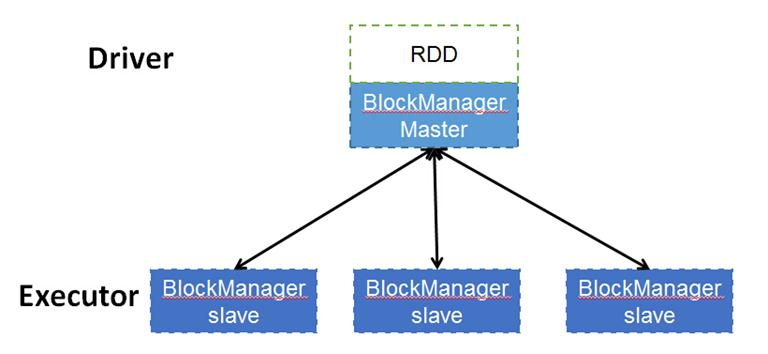
spark大部分时候都是在集群上上运行的,那么数据本身一定是也是分布式存储的,数据是由每个Excutor的去管理多个block的,而元数据本身是由driver的blockManageMaster来管理,当每个excutor创建的时候也会创建相对应的数据集管理服务blockManagerSlave,当使用某一些block时候,slave端会创建block并向master端去注册block,同理删除某些block时候,master向slave端发出申请,再有slave来删除对应的block数据。由此可见,实际上物理数据都excutor上,数据的关系管理由driver端来管理。
rdd架构图如下:
未完待续。。。。。