本地事务
事务是一组原子性的SQL语句,具有ACID四个特性。
-
Atomicity:原子性,构成事务的一组SQL,要么全部执行,要么全不执行。
-
Consistency:一致性,数据库经过事务操作后从一种状态转变为另一个状态。可以说原子性是从行为上描述,而一致性是从结果上描述。
-
Isolation:隔离性,事务操作的数据对象相对于其他事务操作的数据对象相互隔离,互不影响。
-
Durability:持久性,事务提交后,其结果就是永久性的。
事务实现:
对于InnoDB存储引擎的MySQL数据库而言
隔离性:通过不同粒度的锁机制来实现事务间的隔离的。
原子性、一致性、持久性是通过redo log 重做日志和 undo log 回滚日志来保证的。
redo log:
当数据库对数据做修改的时候,需要把数据从磁盘读到buffer pool中,然后在buffer pool中进行修改。那么在修改的时候buffer pool中的数据页就与磁盘上的数据
页内容不一致,称buffer pool的数据页为dirty page脏数据。
如果这个时候发生非正常的DB服务重启,那么这些数据还在内存,并没有同步到磁盘文件中(随机IO),也就是会发生数据丢失。因此InnoDB会在当bufer pool
中的data page变更结束后,把相应修改记录到redo log中(顺序IO)。redo log是循环写的,从前往后,写完后会继续从开头开始写,覆盖之前的内容。有了redo log,
InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
undo log:
undo log 用于存放数据库修改前的值,如果修改出现异常,可以使用undo log 来实现回滚操作,保证事务的一致性。另外InnoDB MVCC事务特性也是基于undo log
实现的。
undo 日志分为 insert undo log(insert 语句产生的日志,事务提交后直接删除)和 update undo log(delete 和 update 语句产生的日志,由于该 undo log 可能提供
MVVC 机制使用,所以不能在事务提交时删除)
一句话总结就是 redo log 存储修改操作记录,undo log 存储修改前的原值。
相关理论:
CAP理论:即一致性 C, 可用性 A,分区容错性 P。这三个要素最多只能实现两点,不能三者兼顾。由于在分布式系统中,分区容错性必然存在,因此只能在一致性和可用性
妥协,MySQL其实CA组合,在主从架构下,读写分离的情况下,是牺牲一定的一致性的(主从延迟,最终一致性)。
BASE理论:基本可用 BA,软状态 S,最终一致性E 。CAP理论下的折中方案。基本可用:分布式系统出现故障是,允许损失部分可用功能,保证核心功能可用。软状态:允
许系统存在中间状态,这个状态不影响系统可用性。 最终一致性:系统的中间状态经过短暂的时间会到达一致状态。
BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。接下来我们着重对BASE中的三要素进行详细讲解。基本可用:指分布式系统在出现不可预知故障的时候,允许损失部分可用性。
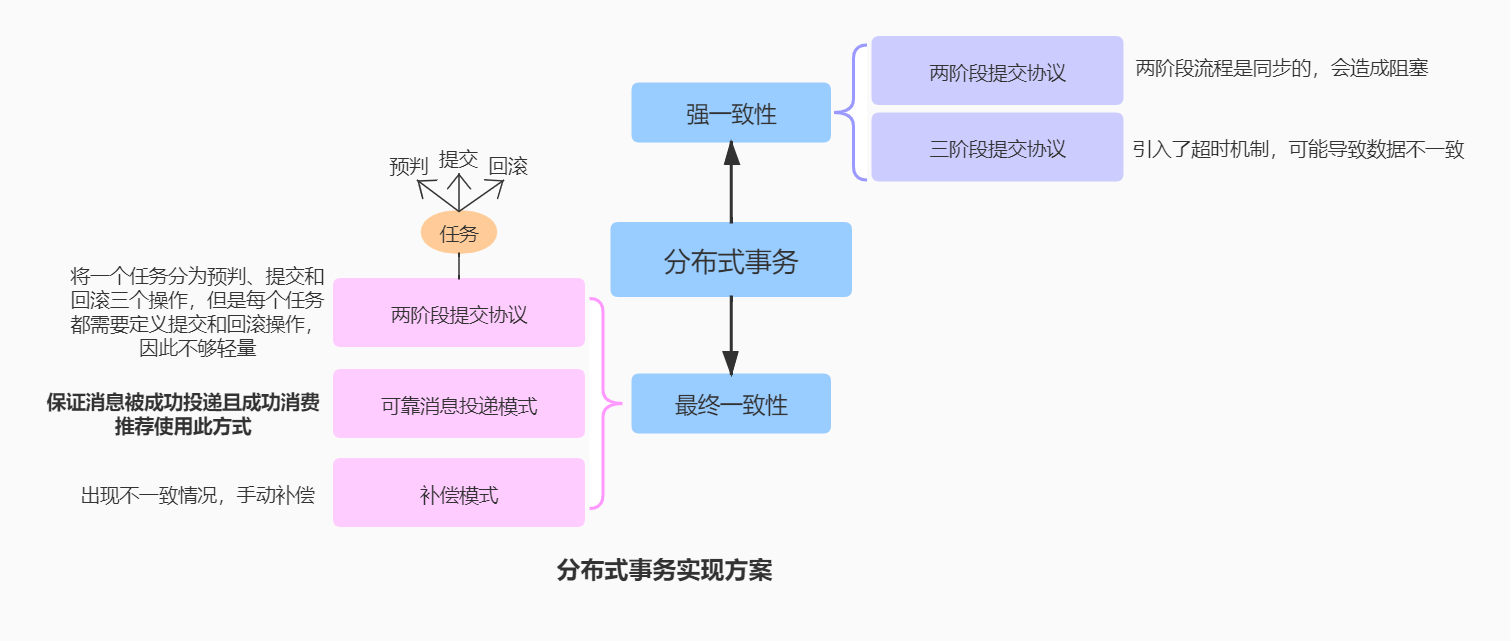
分布式事务一致性解决方案
一句话总结就是:为了保证不同数据库中数据一致性的解决方案。
可靠消息投递实现步骤
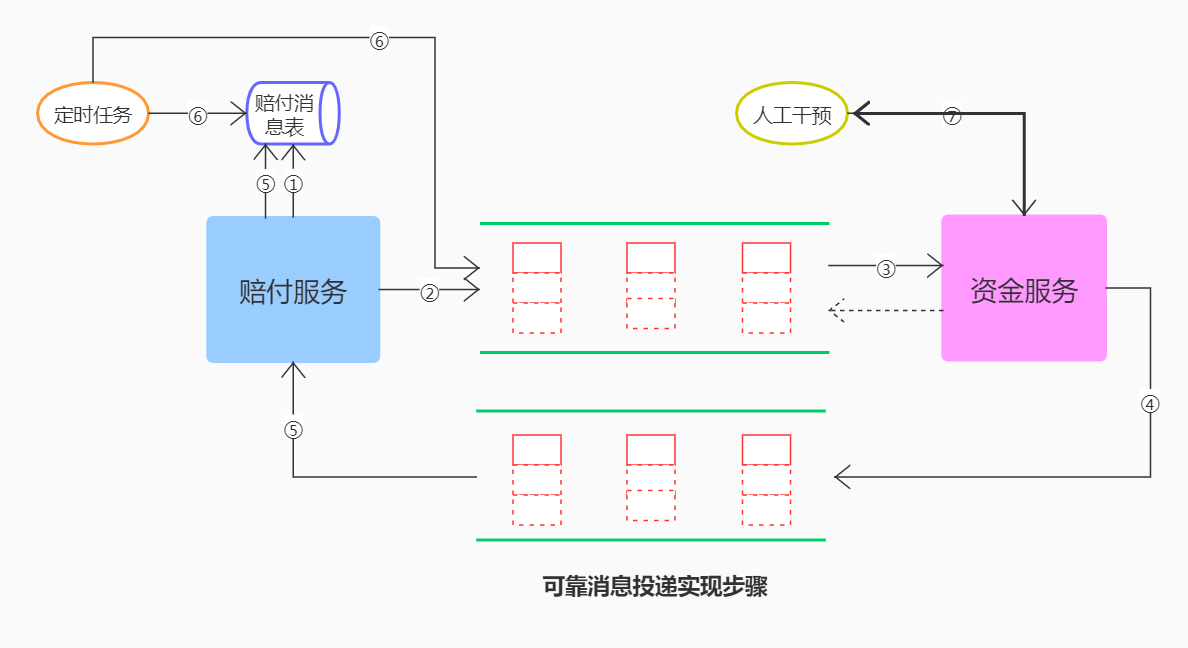
① 用户发起赔付后,赔付服务首先将赔付消息写入本地数据库,持久化这笔赔付快照
② 赔付服务发起一条赔付消息投递到消息队列
③ 消息队列异步将消息投递给资金服务,资金服务消费赔付消息
④ 资金服务执行其执行自己相关的逻辑,并自我保证其业务的成功处理,如果执行成功则发送一条执行出账成功消息投递给消息队列
⑤ 赔付服务接收到出账成功的消息后,修改数据库中消息赔付表中消息的状态为完成
⑥ 设置一个定时任务扫描数据库中消息赔付表中未完成的消息并进行重新投递
⑦ 当消息执行超过失败次数时,需要进行人工干预
注意:实际业务中需要将可靠消息投递模式从业务中解耦与抽离,作为一个可复用的分布式事务解决组件
1、本地表
如转账操作,用户向系统A发起转账请求,A现在自己的数据库中扣钱,然后调用系统B的服务通知加钱。
A系统需要两个操作,扣减自己的余额表和调用系统B的服务。但是这两个操作不是原子性的,所以不管两个操作的先后顺序怎样,都可能存在问题。
因此可以在系统A的本地增加一个消息表,A系统扣钱然后写扣钱记录消息到消息表中,使扣钱和写消息在A本地同一个事务中,这样就保证了原子性。
然后再由后台程序从消息表中读取消息发给B系统。
2、事务消息
消息队列不仅解决了服务内部由于业务流程的同步执行而造成的阻塞,并且可以实现业务解耦。
3、相关理论
(1):二阶段提交
(2):三阶段提交
(3):DTP Model
(4):TCC
Try Confirm Cancel
(5):Saga
4、开源项目
Seata