Redis是单线程程序。单线程的Redis为何还能这么快?
1、所有的数据都在内存中,所有的运算都是内存级别的运算(因此时间复杂度为O(n)的指令要谨慎使用)
2、单线程操作,避免了频繁的上下文切换
3、多路复用(非阻塞IO多路复用),NIO来处理客户端的并发连接
非阻塞IO,Non-block IO, NIO,非阻塞模式,使一个线程从某通道发送请求数据读取数据,如果目前没有数据可读时,就什么都
不会获取,而不是保持线程阻塞,直到有数据可读之前,该线程可以继续做别的事情,非阻塞写也是如此,能写多少取决
于内核为套接字分配的写缓冲区的空闲字节数,不必等到完全写入这个线程可以去做别的事情。线程通常将非阻塞IO的空
闲时间用于在其他通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
阻塞IO,BIO,如Java IO中的各种流都是BIO,阻塞的。当一个线程调用read或者write方法时,该线程会被阻塞,知道有一些数据
被读取,或数据完全写入。该线程在此期间不能再干别的事情了。
事件轮询(多路复用)
非阻塞IO有个问题,那就是线程要读数据,结果读了一部分后返回了,那么当数据到来时,如何通知线程继续读呢?写也是一
样,如果缓冲区写满了没有写完,剩下的数据何时继续写,线程也应该得到通知。
事件轮询API就是用来解决这个问题的。最简单的事件轮询API是select函数。它是操作系统提供给用户程序的API。输入是读
写描述符列表,read_fds&write_fds,输出是与之对应的可读可写事件。同时还提供了一个timeout参数,如果没有任务事件到来,
那么就最多等待timeout的值的时间,线程处于阻塞状态。一旦期间没有任务事件到来,就可以立即返回。时间过了之后没有任务
事件到来,也会立即返回。拿到事件后,线程就可以挨个处理相应的事件。处理完了继续过来轮询。于是线程就进入了一个死循环
,这个死循环称为事件循环,一个循环为一个周期。
通过系统提供的epoll函数同时处理多个通道描述符的读写事件,因此将这类调用称为多路复用API。
(一句话总结就是利用操作系统提供的epoll函数(基于事件驱动)同时处理多个通道描述符的读写事件来实现多路复用)
指令队列:Redis会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。
响应队列:Redis会为每个客户端套接字都关联一个响应队列。Redis服务器通过响应队列来将指令的返回结果回复给客户端。如果队列
为空,那么意味着连接暂时处于空闲状态,不需要去获取写事件。
定时任务:服务器除了要响应IO事件外,还要处理其他的事情。比如定时任务就是非常重要的一件事。如果线程阻塞在select系统调用上
,定时任务无法得到准时调度。Redis的定时任务会记录在一个被称为最小堆的数据结构中。在这个堆中,最快要执行的任务排
在堆的最上方,每个循环周期里。Redis都会对最小堆里面已经到时间点的任务进行处理。处理完毕后,将最快要执行的任务还
需要的时间记录下来,这个时间就是select系统地哦暗涌的timeout参数。因为Redis知道未来timeout的值的时间内,没有其他定
时任务需要处理,所以可以安心睡眠timeout的值的时间。
Redis单线程特性的优缺点
优点:
1、代码更清晰,逻辑更简单
2、不用因为同步去考虑各种锁的问题,不存在加锁和释放锁的操作,基本不会出现死锁而导致的性能消耗
3、不存在多线程切换导致的CPU消耗
缺点:
无法发挥多核CPU的性能,不过可以通过在单机开多个Redis实例来实现
持久化
Redis的数据全部在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证Redis中的数据不会因为故障而丢失,这
种机制就是Redis的持久化机制。
Redis的持久化机制有两种:
一、快照RDB
1、一次全量备份,使用 BGSAVE命令
2、保存方式是内存数据的二进制序列化形式,在存储上非常紧凑
3、使用操作系统的多进程COW(copy on write)机制来实现持久化,持久化时调用glibc的函数fork(分岔)产生一个子进程,持久
化完全交给子进程来处理,父进程继续处理客户端请求
4、COW机制的数据页面的分离。父进程在对页面的数据进行修改时,会将被共享的页面复制一份分离出来,然后对复制出来的页面
进行修改。这时子进程的页面是没有变化的,还是进程产生那一瞬间的数据,所以这种持久化叫做快照的原因。
5、使用fork子进程,无法实时,宕机会造成数据丢失
二、AOF日志
1、连续的增量备份,使用appendonly yes开启
2、存储的是Redis服务器的顺序指令序列,只记录对内存进行修改的指令序列
3、记录的是内存数据修改的指令记录文本,在长期的运行过程中会变得非常庞大,数据库重启时需要加载AOF日志进行指令重放
,比较耗时,所以需要定期进行AOF重写,给AOF日志瘦身
4、Redis收到客户端修改指令后,进行参数校验、逻辑处理,如果没问题,就立即将该指令写到缓冲区中,然后每秒钟调用一次
fsync将指令存储到AOF日志中
5、使用bgrewriteaof指令对AOF日志进行瘦身,即开辟一个子进程对内存进行遍历,转换成一系列Redis的操作指令,序列化到一
个新的AOF日志文件中,再将操作期间新增的AOF日志追加到这个新的AOF日志文件中,替代旧的AOF日志文件,完成瘦身。
Redis4.0混合持久化
实际应用中重启Redis时,很少使用RDB来恢复内存状态,因为会丢失大量数据。所以我们通常使用AOF日志重放,但是重放AOF日志
相对于RDB要慢得多。
混合持久化:将RDB文件的内容和增量的AOF日志文件存在一起。这里的AOF日志不是全量的日志而是自持久化开始到持久化结束的这
段时间发生的增量AOF日志,通常这部分AOF日志很小。因此重启的时候先加在RDB内容,然后再重放增量AOF日志,替
代之前的AOF的全量文件重放,重启效率得到大幅度提升。
事务
Redis的事务模型并不严格(不具备原子性,事务的命令如果有执行失败,并不会回滚)
基本的事务操作都有begin、commit和rollback。begin指示事务的开始,commit指示事务的提交,rollback指示事务的回滚。
Redis事务的指令也差不多,分别是multi、exec、discard。multi指示事务的开始,exec指示事务的执行,discard指示事务的丢弃。
Redis的指令在exec之前不执行,而是缓存在服务器的事务队列中,服务器一旦收到exec指令,才开始执行整个事务。因为Redis是单
线程,所以在执行队列中的命令时不会被其他指令打搅。
但是Redis的事务不具备原子性,而仅仅满足了事务的隔离性中的串行化,当前事务执行不会被其他事务干扰。
优化:Redis事务在每发送一个指令到事务缓存队列都要经过一次网络读写,当一个事务内部的指令较多时,需要的网络IO也会线性增长,
所以通常Redis的客户端在执行事务时都会结合pipeline一起使用。
Watch(CAS机制):
多个客户端并发修改Redis中的一条记录。需要先读,再写。为了保证线程安全,一种方式是通过Redis分布式锁的方式,但是Redis
分布式锁是悲观锁。Redis提供了watch机制,是一种乐观锁在multi之前监视某个关键变量,若在watch之后被修改了(包含当前事务
所在的客户端),如果关键字被修改了,则exec指令就会返回NULL回复告知客户端事务执行失败,这个时候客户端一般会选择重试。
Redis管道技术Pipeline
Redis管道技术是由客户端提供的,而不是服务端
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
1、客户端每发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应
2、服务端处理命令,并将结果返回给客户端
如果连续执行多条指令,那么会花费多个网络数据包来回的时间
Redis管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有的服务端响应。
管道技术显著的提高了Redis的性能,尤其是在大量写操作的情况下。
RESP
REdis Serialization Protocol:Redis序列化协议。Redis服务端与客户端通过RESP协议进行通信,节点交互不使用这个协议。
有如下特性:是二进制安全的、在TCP层、基于请求-响应的模式
RESP有五种最小的单元类型,单元结束时统一加上回车换行符【 】
1、单行字符串:以+符号开头,如:字符串hello world-->+hello world
2、多行字符串:以$符号开头,后跟字符串长度,如:多行字符串hello world-->$11 hello world
3、整数值:以:符号开头,后跟整数的字符串形式,如:整数12-->:12
4、错误信息:以-符号开头,如:-WRONGTYPE
5、数组:以*号开头,后跟数组的长度,如:数组[1,2,3]-->*3 :1 :2 :3
客户端向服务端发送的指令只有一种格式,多行字符串数组。
比如一个简单的 set 指令set author codehole会被序列化成下面的字符串。*3 $3 set $6 author $8 codehole
服务端对客户端的响应支持多种数据结构,即以上5种的基本类型的组合。
发布订阅 PubSub
前面所讲的Redis的消息队列,一个消息只能被一个消费者消费,不支持消息的多播机制。
消息多播允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由相应的消费组进行消费,是分布式
系统常用的一种解耦方式,用于将多个消费组的逻辑进行拆分。支持了消息多播,每个消费组对应的不同子系统可以有不同的逻辑处理。
在生产环境中,一般将生产者和消费者分离
消费者可通过listen来阻塞监听消息来进行处理。
模式订阅:消费者可以同时订阅多个主题的消息,但是如果生产者新增了一个主题,消费者也必须增加一个订阅指令才能收到新增的
主题的消息。为了简化这种订阅的繁琐,Redis提供了模式订阅功能Pattern Subscribe,这样就可以一次订阅多个主题,即使生产者新增
加了同模式的主题,消费者也可以立即收到消息。
如:psubscribe code.*
那么所有以"code. " 开头的主题的消息都能订阅到。
消息结构:
1、data:消息的内容,一般一个字符串
2、channel:当前订阅的主题的名称
3、type:消息的类I型那个,如果是普通的消息,那么类型就是message;如果是控制消息,比如订阅指令的反馈,它的类型就是
subscibe;如果是模式订阅的反馈,它的类I型那个就是psubscribe;此外还有取消订阅指令的反馈unsubscribe和punsubscribe。
4、pattern:表示当前消息是使用哪种模式订阅到的。如果是通过subscribe指令订阅到的,这个字段就是None
缺点:
1、消费者挂掉重连后,在断连期间生产者发送的消息,就丢失了
2、如果Redis停机重启,PubSub的消息不会持久化,所有的消息都会丢失
小对象压缩存储ziplist
Redis的所有数据都放在内存中,所以在使用过程中要注意节约内存,否则就可能出现Redis内存不足导致崩溃。如果Redis内部管理
的集合list数据结构的数据很小,则它会使用紧凑存储形式压缩存储。
Redis的ziplist是一个紧凑的字节数组结构,每个元素之间都是紧挨着的
内存回收机制
Redis并不总是将空闲内存立即归还给操作系统。
如果当前Redis内存有10GB,当你删除了1GB的key后,再去观察内存,你会发现内存变化不会太大。这是以为内操作系统是以页为
单位回收内存的,这个页上只要还有一个key在使用,那么这个页就不能被回收。Redis虽然删除了1GB的key,但是这些key分散到了很
多的页中,每个页都还有其他的key存在,这就导致了内存不会被立即回收。
不过,如果你执行flushdb,然后再观察内存,会发现内存确实被回收了。原因是所有的key都被删掉了,大部分之前使用的页都完全
空了,就会立即被操作系统回收。
Redis虽然无法保证立即回收已经删除的key的内存,但是它会重新使用那些尚未回收的空闲内存。
内存分配算法:
内存分配是一个非常复杂的课题,需要适当的算法划分内存页,需要考虑内存碎片,需要平衡性能和效率,Redis将内存分配的细节交给
了第三方内存分配库去实现。默认的内存分配库是jemalloc
集群
主从同步:当主节点master挂掉的时候,从节点slave接管服务,使服务可以继续。否则主节点需要经过数据恢复和重启,使服务中断
很长时间。
分布式系统存储的理论基石——CAP原理:
C:Consistent,一致性
A:Availability,可用性
P:Partition tolerance,分区容忍性
分布式系统的节点往往都是分布在不同的机器上进行网络隔开的,这意味着必然有网络断开的风险,这个网络断开的场景的专业词汇叫做
网络分区。
在网络分区发生时,两个分布式节点之间无法进行通信,我们对一个节点的修改操作无法同步到另一个节点,所以数据的一致性将无法满
足,因为两个分布式节点的数据不再保持一致,除非牺牲可用性,也就是暂停分布式节点服务,在网络分区发生时,不再提供修改数据的
功能,直到网络状况完全恢复正常再继续对外提供服务。即当网络分区发生时,一致性和可用性不可兼得(Redis满足AP)。
最终一致
Redis的主从数据是异步同步的,所以分布式的Redis系统并不满足一致性要求。当客户端在Redis的主节点修改了数据后,立即返回
,即使在主从网络断开的情况下,主节点依旧可以正常对外提供修改服务,所以Redis满足可用性。
Redis保证最终一致性,从节点会努力追赶主节点,最终从结点的状态会和主节点的状态保持一致。如果网络断开了,主从节点的数据会
出现大量不一致,但一旦网络恢复,从节点会采用多种策略努力追赶,继续尽力保持和主节点一致。
增量同步:
Redis同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地的内存buffer中,然后异步将buffer中的指令
同步到从节点,从节点一边执行同步的指令流来达到和主节点一样的状态,一边向主节点反馈自己同步到哪里了(偏移量)。
因为内存的buffer是有限的,所以Redis主节点不能将所有的指令都记录在内存buffer中,Redis的复制内存buffer是一个定长的环形数
组,如果数组内容满了,就会从头开始覆盖前面的内容,如果因为网络状况不好,从节点在短时间内无法和主节点进行同步,那么当
网络恢复时,Redis的主节点中那些没有同步的指令在buffer中有可能被后续的指令覆盖掉了,从节点将无法直接通过指令流来进行同
步,这时就需要用到更加复杂的同步机制——快照同步。
快照同步:
快照同步是一个十分消耗资源的操作,它首先需要在主节点上进行一次bgsave,将当前内存的数据全部快照到磁盘文件中,然后再将
快照文件的内容全部传送到从节点。从节点将快照文件接收完毕后,立即执行一次全量加载。加载之前要先将当前内存的数据清空,加载
完毕后继续通知主节点继续进行增量同步。
在快照同步的过程中,主节点的buffer还在不停的往前移动,如果快照同步的时间过长或者复制buffer太小,都会导致同步期间的增量指令
在复制buffer中被覆盖,这样就会导致快照同步完成后无法进行增量复制,然后再次发起快照同步,如此极有可能会陷入快照同步的死循环。
所以buffer大小参数一定要设置合适,避免快照复制的死循环。
集群
主从同步:Redis的主从数据是异步同步的,所以分布式的Redis系统并不满足一致性要求。当客户端在Redis的主节点修改了数据以后,立即返回,即使在主从网络
断开的情况下,主节点依旧可以正常对外提供修改服务,所以Redis满足可用性。但是Redis满足最终一致性,从节点会努力追赶主节点,最终从节点的状态会和主节点的
状态保持一致。如果网络断开了,主从节点的数据会出现大量的不一致,但一旦网络恢复,从节点会努力追赶主节点,继续尽力与主节点一致。
同步方式:
1、增量同步:
Redis同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地的buffer中,然后异步将buffer中的指令同步到从节点,从节点一边执行同步
的指令流来达到和主节点一样的状态,一边向主节点反馈自己同步到哪里了(偏移量)。
因为内存的buffer是有限的,所以Redis主节点不能将所有的指令都记录在内存buffer中,Redis的复制内存buffer是一个定长的环形数组,如果数据内容满了,就会
从头开始覆盖前面的内容。
如果因为网络状况不好,从节点在短时间内无法和主节点进行同步,那么当网络恢复时,Redis的主节点中那些没有同步的指令在buffer中可能已经被后续的指令覆
盖了,从节点将无法直接通过指令流来进行同步,这个时候就需要用到更加复杂的同步机制-快照同步。
2、快照同步:
快照同步是一个非常耗资源的操作,它首先需要在主节点上进行一次bgsave,将当前内存的数据全部快照到磁盘文件中,然后再将快照文件的内容全部传送到从节
点。从节点将快照文件接受完毕后,立即执行一次全量加载,加载之前先要将当前内存的数据清空,加载完毕后通知主节点继续进行增量同步。
在整个快照同步进行的过程中,主节点的复制buffer还在不停地往前移动,如果快照同步的时间过长或者复制buffer太小,都会导致同步期间的增量指令在复制buffer
中被覆盖,这样的话会导致快照完成后无法进行增量复制,然后会再次发起快照同步,如此下去极有可能陷入快照同步的死循环。
增加从节点:当从节点刚刚加入集群中时,它必须先进行一次快照同步,同步完成后再继续进行增量同步。
无盘复制:主节点在进行快照同步时,会进行很耗时的文件IO操作,在非SSD的磁盘存储时,快照同步会对系统的负载产生较大的影响。特别是当系统正在进行
AOF的fsync操作时(将AOF日志强制从内核缓存刷到磁盘),如果发生快照同步,fsync将会被推迟执行,这就会严重影响主节点的服务效率。从Redis2.8.18开始,
Redis支持无盘复制。所谓的无盘复制是指主服务器通过套接字将快照内容发送到从节点,生成快照是一个遍历的过程,主节点一边遍历内存,一边将序列化的内容发
送到从节点,从节点还是跟之前一样,先将接收到的内容存储到磁盘文件中,再进行一次性加载。
一、哨兵Sentinel
如果主节点突发宕机那么如何自动主从切换?Redis Sentinel哨兵就是一种抵抗结点故障的高可用方案。
可以将Redis Sentinel集群看成是一个zookeeper集群,它是集群高可用的核心。一般由3-5个节点组成,这样即使个别节点挂了,集群还
可以正常运转。
Sentinel负责持续监控主从节点的健康,当主节点挂掉时,自动选择一个最优的从节点切换成主节点。
客户端来连接集群时会首先连接Sentinel,通过Sentinel来查询主节点的地址,然后再连接主节点进行数据交互。主节点发生故障时,客户
端会重新向Sentinel获取新的主节点的地址,如此应用程序将无需重启即可自动完成节点切换。
如果主节点挂掉了,原先的主从复制也断开了,客户端和损坏的主节点也断开了。一个从节点被提升为新的主节点,其他从节点开始和新
的主节点建立复制关系。客户端通过新的主节点继续进行交互。Sentinel会持续监控已经挂掉了的前主节点,待它恢复后,变成从节点和
新的主节点建立复制关系。
消息丢失:
Redis主从采用异步复制,意味着当主节点挂掉时,从节点可能还未收到全部的同步消息,这部分未同步的消息就丢失了。如果主从延
迟特别大,那么丢失的数据就可能会特别多。Sentinel无法保证消息完全不丢失,但是也尽量保证消息少丢失。有下面两个选项避免主从延
迟过大:
min-slaves-to-write 1 表示主节点必须至少有一个从节点在进行正常复制,否则就对外停止写服务,丧失可用性
min-slaves-max-lag 10 单位秒,表示如果在10s内没有收到从节点的反馈,就意味着从节点同步不正常。
Sentinel的默认端口是26379,不同于Redis的默认端口6379,通过Sentinel对象的discover_xxx方法可以发现主从地址,主地址只有一个,
从地址可以有多个。通过master_for 或者 slave_for方法可以从连接池中获取主节点或者从节点的连接实例。因为从地址有多个,所以Redis
客户端对从地址采用RoundRobin轮询方案。
二、集群Codis
在大数据高并发情况下,单个Redis实例往往会显得捉襟见肘。
首先体现在内存上,单个Redis的内存不宜过大,内存太大会导致rdb文件过大,进一步导致主从同步时全量同步时间过长,在实例重启恢复
时也会消耗很长的数据加载时间。
其次体现在CPU的利用率上,单个Redis实例只能利用单个核心,这单个核心要完成海量数据的存取和管理工作,压力非常大。
所以Redis集群应运而生。它可以将众多小内存的Redis实例整合起来,将分布在多台机器上的众多CPU核心的计算能力聚集在一起,完成海
量数据存储和高并发读写操作。
Codis是一个代理中间件,和Redis一样也使用Redis协议对外提供服务,当客户端向Codis发送指令时,Codis负责将指令转发到后面的Redis
实例来执行,并将返回结果再转回给客户端。
Codis上挂载的所有Redis实例构成一个Redis集群,当集群空间不足时,可以通过动态增加Redis实例来实现扩容需求。
因为Codis是无状态的,它只是一个转发代理中间件,这意味着我们可以启动多个Codis实例,供客户端使用,每个Codis节点都是对等的。因
为单个Codis代理能支撑的QPS比较有限,通过启动多个Codis代理可以显著增加整体的QPS需求,还能起到容灾功能,挂掉一个Codis代理实
例没有关系,还有很多的Codis代理实例可以提供服务。
Codis分片原理:
Codis负责将特定的key转发到特定的Redis实例,这种对应关系Codis是如何管理的呢?Codis默认将所有的key划分为1024个槽位(slot),
如果集群节点比较多,也可以手动设置大一些,如2048;
它首先对客户端传来的key进行crc32运算计算hash值,再将hash后的整数值对1024这个整数进行取模得到一个余数,这个余数就是对应
的key的槽位。而每个槽位都会唯一映射到后面的多个Redis实例中的一个。Codis会在内存中维护槽位和Redis实例的映射关系,这样有了
key对应的槽位,将这个key转发到那个Redis实例就很明确了。
不同的Codis实例之间槽位关系如何同步:
如果Codis的槽位映射关系只存储在内存里,那么不同的Codis实例之间的映射关系就无法得到同步。所以Codis还需要一个分布式配置存储
数据库专门用来持久化槽位关系,Codis支持zookeeper和etcd。
Codis将槽位关系存储在zookeeper中,并且提供了一个Dashboard可以用来观察和修改槽位关系,当槽位关系变化时,Codis Proxy会监听
到变化并重新同步槽位关系,从而实现多个Codis Proxy之间共享槽位关系配置。
三、集群Cluster
Redis Cluster 是Redis的作者自己提供的Redis集群化方案。与Codis不同,Redis Cluster是去中心化的,该集群由三个Redis节点组成,每个
节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样,节点组成一个对等的集群,它们之间通过一种特殊的二进制协议交
互集群信息。
Redis Cluster将所有数据划分为16384个槽位,它比Codis的1024个槽位划分的更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个
节点中,不像Codis,不需要另外的分布式存储空间来存储节点信息。
当Redis Cluster的客户端来连接集群时,也会得到一份集群的槽位配置信息。这样当客户端要查找某个key时,可以直接定位到目标节点。这一点
于Codis也不同,Coids需要通过Proxy来定位目标节点,Redis Cluster则是直接定位。
客户端为了直接定位某个具体的key所在的节点,需要缓存槽位的相关信息,这样才可以准确快速地定位到相应的节点。同时因为可能会存在客户端
与服务端存储槽位的信息不一致的情况,还需要纠正机制来实现槽位信息的校验调整。另外,Redis Cluster的每个节点会将集群的配置信息持久化到
配置文件中,所以必须确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
槽位定位算法:
Redis Cluster默认会对key值使用crc16算法进行hash,得到 一个整数值,然后用这个整数值对16384进行取模来得到槽位。
容错:Redis Cluster可以为每个主节点设置若干个从节点,当主节点发生故障时,集群会自动将其中某个从节点提升为主节点。如果某个主节点没有
从节点,那么当它发生故障时,集群将完全处于不可用状态。
Info指令:
在使用Redis时,时长会遇到很多问题需要诊断,在诊断之前需要了解Redis的运行状态,通过强大的Info指令,可以清晰地知道Redis内部一系列运行
参数。Info指令显示的信息繁多,分为9大块,每个块都有非常多的参数
1、Server 服务器运行的环境参数
2、Clients 客户端相关信息
3、Memory 服务器运行内存统计数据
4、Persistence 持久化信息
5、Stats 通用统计数据
6、Replication 主从复制相关信息
7、CPU CPU使用情况
8、Cluster 集群信息
9、KeySpace 键值对统计数量信息
Info stats|grep ops 每秒操作数
moniter 哪些key被访问得比较频繁
Info clients 连接了多少客户端
Info memory Redis占用了多少内存
分布式锁之Redlock算法
在Sentinel集群中,当主节点挂掉时,从节点会取而代之,但客户端上并没有明显感知。比如第一个客户端在主节点上申请成功了一把锁,但是
这把锁还没有来得及同步到从节点,主节点突然挂掉了,然后从节点变成了主节点,这个新的主节点内部没有这个锁,所以当另一个客户端过来请
求加锁时,立即就批准了。这样导致系统中同样一把锁被两个客户端同时持有,不安全性由此产生。
这种不安全仅在主从发生failover(失效接管)的情况下才会产生,持续的时间极短,业务系统多数情况下可以容忍。
Redlock的出现就是为了解决这个问题。要使用Redlock,需要提供多个Redis实例,这些实例之前相互独立,没有主从关系。同很多分布式算法
一样,Redlock也使用 “大多数机制“;
加锁时,它会向过半节点发送 set(key,value,nx=True,ex=xxx)指令,只要过半节点set成功,就认为加锁成功。释放锁时,需要向所有节点发
送del指令。不过Redlock算法还需要考虑出错重试、时钟漂移(时钟抖动频率在10hz一下)等很多细节问题。同时因为Redlock需要向多个节点进行
读写,意味着其相比单实例Redis的性能会下降一些
Redlock使用场景:非常看重高可用性,即使Redis挂了一台也完全不受影响就使用Redlock。代价是需要更多的Redis实例,性能也会下降,需
要引入额外的library,运维上也需要区别对待。
分布式锁之过期时间到了锁失效但任务还未执行完毕
某个线程在申请分布式锁的时候,为了应对极端情况,比如机器宕机,那么这个锁就一直不能被释放。一个比较好的解决方案是,申请锁的时候
,预估一个程序的执行时间,然后给锁设置一个超时时间,这样,即使机器宕机,锁也能自动释放。
但是这也带来了一个问题,就是在有时候负载很高,任务执行的很慢,锁超时自动释放了任务还未执行完毕,这时候其他线程获得了锁,导致程序
执行的并发问题。对这种情况的解决方案是:在获得锁之后,就开启一个守护线程,定时去查询Redis分布式锁的到期时间,如果发现将要过期了,就
进行续期。
朝生暮死-过期策略
设置了有效期的key到期了怎么删除呢?
Redis会将每个设置了过期时间的key放入一个独立的字典中,以后会定时遍历这个字典来删除到期的key。除了定时遍历之外还会使用惰性删除
过期的key。所谓惰性删除就是在客户端访问这个key的时候,Redis对key的过期时间进行检查,如果过期了就会立即删除。所以过期key的删除策略
是 定时删除+惰性删除
定时删除:Redis默认每秒进行10次过期扫描,过期扫描不会遍历过期字典中所有的key,而是采用了一种简单的贪心策略,步骤如下:
1、从过期字典中随机选出20个key
2、删除这20个key中已经过期的key
3、如果过期的key的比例超过1/4,那就重复步骤1
同时,为了保证过期扫描不会出现循环过度,导致线程卡死的现象,算法还增加了扫描时间的上限,默认不会超过25ms。
假设一个大型的Redis实例中所有的key在同一时间过期了,会出现怎么样的结果呢?毫无疑问,Redis会持续循环多次扫描过期字典,直到过期
字典中过期的key变得稀疏,才会停止(循环次数明显下降)。这就会导致线上读写请求出现明显的卡顿现象。导致这种卡顿的另外一种原因是内存
管理器需要频繁回收内存页,这也会产生一定的CPU消耗。
如当客户端到来时,服务器正好进入过期扫描状态,客户端的请求将会等待至少25ms后才会进行处理,如果客户端将超时时间设置的比较短,如10
ms,那么就会出现大量的请求因为超时而关闭。业务端会出现很多异常,而且这是你还无法从Redis的slowlog中看到慢查询记录,因为慢查询指的是
逻辑处理过程慢,而不包含等待时间。所以当客户端出现大量超时而慢查询日志无记录时,可能是当前时间段大量的key过期导致的。
所以在开发过程中一定要避免在同一时间内出现大量的key同时过期。尽量给key的过期时间设置一个随机范围,使其过期时间均匀分布。
从节点不会进行过期扫描,过期的处理是被动的,主节点在key到期时,会在AOF日志文件中增加一条del指令,同步到所有的从节点,从节点通过执行
这条del指令来删除过期的key。因为指令同步是异步的,所以会出现从节点的key删除不及时的情况。
惰性删除:
实际上Redis内部并不是只有一个主线程,它还有几个异步线程来处理一些耗时的操作。如果被删除的key是一个非常大的对象,那么del指令删除操作就
会导致单线程卡顿。所以4.0版本引入了unlink指令,可以对删除操作进行懒处理,丢给后台线程来异步回收内存。
在获取某个key的时候,Redis会检查一下这个key是否设置了过期时间以及这个是否到期了,如果到期了就交给后台线程去删除这个key,然后主线程什
么也不会返回。
优胜劣汰-LRU内存淘汰机制
当Redis内存超过物理内存限制时,内存的数据会开始和磁盘产生频繁的交换swap,交换会让Redis的性能急剧下降,对于访问量比较大的Redis来说,会
导致响应时间过长。所以在生产环境中不允许有这种交换行为,为了限制最大内存,Redis提供了配置参数maxmemory参数来限制内存使用阀值,当超出这个
阀值时,Redis提供了几种可选的内存淘汰策略供用户选择以腾出空间以继续提供读写服务。
1、noeviction 不会继续服务写请求,del和读服务可以继续进行,这是默认的淘汰策略
2、volatile-lru 尝试淘汰设置了过期时间的最近最少使用的key
3、volatile-ttl 尝试淘汰了设置了过期时间的ttl(Time to live)最少的key
4、volatile-random 尝试从设置了过期时间的key中随机淘汰一部分key
5、allkeys-lru 尝试淘汰所有的key中最近最少使用的key
6、allkeys-random 尝试从所有的key中随机淘汰一部分key
LRU算法
实现LRU算法除了需要key/value字典外,还需要附加一个链表,链表中的元素按照一定的顺序进行排列。当字典中的某个元素被访问时,会将它从在链
表中的某个位置移动到链表头部;当空间满的时候,会踢掉链表尾部的元素。所以链表元素的排列顺序就是元素最近被访问的顺序。
Redis使用的是近似的LRU算法,因为LRU算法需要占用大量的额外内存,还需要对现有的数据结构进行比较大的改造。近似LRU算法很简单,在现有的数据
结构的基础上使用随机采样法淘汰元素,通过给每个key增加一个额外的24bit的小字段存储最后一次被访问的时间戳。而且采用的是惰性策略,Redis在执行
写操作时,发现内存超过maxmemory,就会执行一次近似LRU算法,随机采样出5(可以设置)个key,然后淘汰掉最旧的key,如果淘汰后内存仍大于
maxmemory,继续采样淘汰,知道内存小于maxmemory为止。
手写一个LRU算法,有三种方案
1、数组,用数组来存储数据,并给每个数据项标记一个时间戳,每次插入新数据项的时候,先把数组中存在的数据项对应的时间戳自增,并将新
数据项的时间戳置为0并插入到数组中。每次访问数组中新数据项的时候,将被访问的数据项的时间戳置为0。当数组空间满时,将时间戳最大的数
据项淘汰。
2、链表,每次插入新数据的时候将新数据插入到链表的头部,每次访问数据也将被访问的数据移动到链表头部,当链表满时将链表尾部的数据淘汰
3、链表+hashMap,LinkedHashMap。当需要插入新的数据项的时候,如果新数据项在链表中存在(即命中),则把该节点移动到链表头部,如
果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把
该节点移到链表头部,否则返回-1,这样链表尾部的节点就是最近最少访问的数据项。
分析:使用数组需要不停维护数据项的访问时间戳,并且在插入数据,访问和删除数据(不知道数组下标)的时候,时间复杂度都是O(n),仅使用链表的情况下,
在访问定位数据的时间复杂度为O(n),所以一般使用LinkedHashMap的方式。LinkedHashMap的底层就是使用HashMap加双向链表实现的,而且本身是有序的(
插入和访问顺序相同),新插入的元素放入链表的尾部;且其有removeEldestEntry方法用于移除最老的元素,不过默认返回false,表示不移除,需要重写此方法当超过map容量时移除最老的元素即可。
LinkedHashMap:
/** * Returns <tt>true</tt> if this map should remove its eldest entry. * This method is invoked by <tt>put</tt> and <tt>putAll</tt> after * inserting a new entry into the map. It provides the implementor * with the opportunity to remove the eldest entry each time a new one * is added. This is useful if the map represents a cache: it allows * the map to reduce memory consumption by deleting stale entries. * * <p>Sample use: this override will allow the map to grow up to 100 * entries and then delete the eldest entry each time a new entry is * added, maintaining a steady state of 100 entries. * <pre> * private static final int MAX_ENTRIES = 100; * * protected boolean removeEldestEntry(Map.Entry eldest) { * return size() > MAX_ENTRIES; * } * </pre> * * <p>This method typically does not modify the map in any way, * instead allowing the map to modify itself as directed by its * return value. It <i>is</i> permitted for this method to modify * the map directly, but if it does so, it <i>must</i> return * <tt>false</tt> (indicating that the map should not attempt any * further modification). The effects of returning <tt>true</tt> * after modifying the map from within this method are unspecified. * * <p>This implementation merely returns <tt>false</tt> (so that this * map acts like a normal map - the eldest element is never removed). * * @param eldest The least recently inserted entry in the map, or if * this is an access-ordered map, the least recently accessed * entry. This is the entry that will be removed it this * method returns <tt>true</tt>. If the map was empty prior * to the <tt>put</tt> or <tt>putAll</tt> invocation resulting * in this invocation, this will be the entry that was just * inserted; in other words, if the map contains a single * entry, the eldest entry is also the newest. * @return <tt>true</tt> if the eldest entry should be removed * from the map; <tt>false</tt> if it should be retained. */ protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
构造方法:
/** * Constructs an empty <tt>LinkedHashMap</tt> instance with the * specified initial capacity, load factor and ordering mode. * * @param initialCapacity the initial capacity * @param loadFactor the load factor * @param accessOrder the ordering mode - <tt>true</tt> for * access-order, <tt>false</tt> for insertion-order * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive */ public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
自定义LRU实现:
package lru; import java.util.LinkedHashMap; import java.util.Map; /** * LinkedHashMap 实现LRU算法 * 〈功能详细描述〉 * * @author 17090889 * @see [相关类/方法](可选) * @since [产品/模块版本] (可选) */ public class LRU<k, v> extends LinkedHashMap<k, v> { /** * 容量,实际能存储多少数据 */ private final int MAX_ENTRIES; /** * Math.ceil(cacheSize/0.75f)+1 HashMap的initialCapacity * 0.75f 负载因子 * accessOrder 排序模式,true:按照访问顺序进行排序,最近访问的放在尾部 false:按照插入顺序 * * @param maxEntries */ public LRU(int maxEntries) { super((int) (Math.ceil(maxEntries / 0.75f) + 1), 0.75f, true); MAX_ENTRIES = maxEntries; } /** * 重写移除最老元素方法 * 返回true,表示删除最老元素 false 表示不删除 * * @param eldest * @return */ @Override protected boolean removeEldestEntry(Map.Entry<k, v> eldest) { // 当实际容量大于指定的容量的时候就自动删除最老的元素,链表头部的元素 return size() > MAX_ENTRIES; } }
插入测试:
LRU<String, String> lru = new LRU<>(5); lru.put("3", "3"); lru.put("1", "1"); lru.put("5", "5"); lru.put("2", "22"); lru.put("3", "33"); lru.get("5");
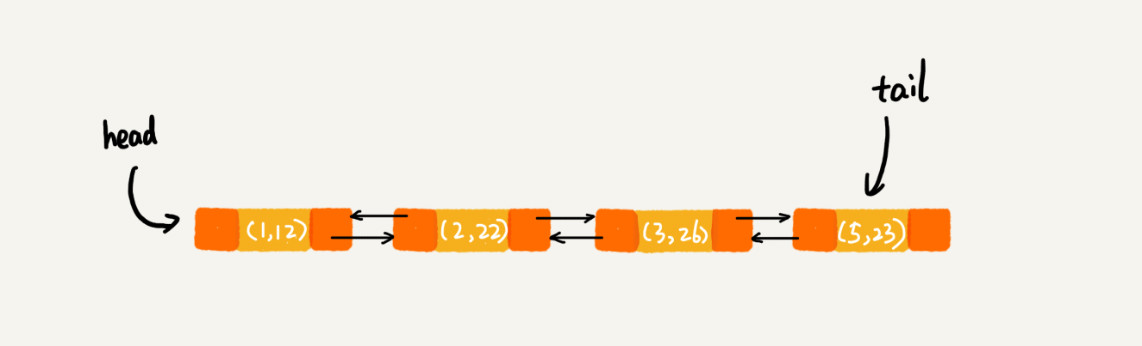
遍历得到的结果:1 2 3 5
存储链表结构为:
LFU算法
Redis 4.0 引入了一个新的淘汰策略,LFU(Lasted Fequently Used) :最少频繁使用。按照最近的访问频率进行淘汰,比LRU更加精确地表示了一个key被访问的热度。
如果一个key长时间不被访问,只是偶尔被访问了一下,那么它在LRU算法中就被移动到了链表的头部,是不容易被淘汰的,因为LRU算法会认为它是一个热点key。
而LFU需要追踪最近一段时间内key的访问频率,只有最近一段时间内被访问多次的key,LFU才认为是热点key。
缓存穿透
指查询一个数据库中一定不存在的数据,如根据商品编号查询详情;首先去查询缓存,缓存中自然没有然后去查询数据库,如果对这个key的请求
量巨大,会直接穿透缓存直接查询数据库给数据库造成很大的压力
解决方案:
1、对查询结果为空的情况也进行缓存,不过缓存时间设置短一些,如60s。如果对该key插入了数据到db之后要清理缓存
2、使用布隆过滤器,将所有可能存在数据的key放在布隆过滤器中,查询缓存中没有数据之后,再使用布隆过滤器进行过滤请求,判断查询的key
是否在布隆过滤器中,如果不在,则直接返回不再查询数据库
缓存击穿
某个key是热点数据,扛着高并发请求集中对这个key进行访问,避免了访问数据库。那么在这个key失效的瞬间,持续的高并发就击穿了缓存直接
请求数据库,对数据库造成很大压力。
解决方案:
1、热点key缓存永远不过期
不设置过期时间
将过期时间存在key的value中,程序判断将要过期时,异步线程对改key进行更新
2、互斥锁,mutex lock 。当缓存失效的时候,线程不是立即去查询数据库,而是通过设置锁的方式占坑,如Redis的SETNX,判断返回值,谁拿
到了锁谁去查询数据库然后设置缓存,没拿到锁的线程重试get方法。
缓存雪崩
在某个时间段,缓存中大量的key集中过期失效
解决方案:
1、使用互斥锁
2、数据预热
通过缓存reload机制,预先去设置或更新缓存,在即将大并发访问前手动在后台触发加载缓存不同的key,然后设置不同的过期时间,让缓存
过期失效的时间点尽量均匀
3、二级缓存
两个缓存,a1为原始缓存,a2为备份缓存;a1短期,a2长期;a1过期了再去查询a2
4、缓存永远不过期
互斥锁实现逻辑
public String get(key) { String value = redis.get(key); if (value == null) { //代表缓存值过期 //设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功 value = db.get(key); redis.set(key, value, expire_secs); redis.del(key_mutex); } else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可 sleep(50); get(key); //重试 } } else { return value; } }