spark项目技术点整理
1.性能调优:
1>分配更多的资源:性能调优的王道就是分配和增加更多的资源。写完一个spark作业后第一个要是调节最优的资源配置,能够分配的资源达到你的能力范围的顶端后,才是考虑以后的性能调优。
2>分配那些资源:executor,cpu per executor,memory per executor.,driver memory
3>在哪里分配:在提交spark作业时,用spark脚本,里面调整参数
/usr/local/spark/bin/spark-submit
--class.cn.spark.sparktest.core.WordCountCluster
--num-executor 3
--driver-memory 100m
--executor-memory 100m
--executor-core
/usr/localSparkTest-0.0.1SNAPHOT-jar-with-dependencies.jar
4>调节多大合适:
spark standalone:根据公司集群配置,如每台可以提供4G内存,2个cpu core;20台机器:一个作业同时提交:executor:20,4g内存,2个cpu core ,平均每个executor。
yarn:资源队列。查看spark提交的队列大约有多少资源,如500G内存,100 CPUcore,那么平均每个executor:10G内存,2个CPUcore;
总结:有多少用多少。
5>为什么增加资源会提高性能?
增加executor:使得并行的task数量变多,即意味着Appliction的并行能力提升。比如,有3个executor,每个executor 有2个core ,那么并行的task就是6,而增加executor后并行的数量变多了,可以并行10个或者20个,性能的提升是10倍到20倍!增加 core同理。
增加memory:
1.如果要对RDD今年进行cache,那么更多的内存可以缓存更多 的数据,将更少的数据写入磁盘,甚至不写入磁盘。减少了磁盘IO。
2.对于task的执行,可能创建很多对象。如果内存较小,可能对导致频繁的JVM堆内存溢出(OOM),频繁gc,垃圾回收,minor GC和
full GC,速顿很慢。内存加大后会带来更少的GC,垃圾回收,速度就变快了。
3.对于shuffle操作,reduce端,会需要内存存取拉去的数据进行聚合,如果内存不够,也会写入磁盘。给executor分配更多的内存后,就会有更少的数据写入磁盘甚至不写入磁盘。减少磁盘IO,提升性能。
2.实际项目中调节并行度:
1.如果不设置并行度的后果:比如100个task,50个executor,每个executor有3个core ,即任何一个stage运行的时候都有总数150个core可以并行运行。但是现在100个task,平均分配,每个executor分配2个task,那么同时运行的task只有100,每个executor只会并行2个task,每个executor剩下一个core浪费掉了。
2.这样虽然给你的资源够了,但是并行度没有和资源相匹配,导致资源浪费。上述例子中,集群中有150个core就应该将并行度设置为150,还可以让每个task处理的数据量变少,比如150G的数据,如果是100个task,则每个task计算1.5G,增加到150个task后,每个task处理1G即可。
3.理想情况下,设置成与spark aplication总cpu相同。而官方推荐task数量,设置成application 总cpu core 的2~3倍,比如150core设置的task在300~500左右。因为实际情况和理想有出入,有的task快一点,50s就结束了,有的要1分多钟,所以设置的和 core 相同可能还是会导致资源浪费,实际生产中只能尽量做到让core不要空闲。
4.如何设置并行度?
spark.default.parallelism.SparkConf conf =new SparkConf().set("spark.default.parallelism","500")
3.重构RDD架构以及RDD持久化
1概况:默认情况下,多次对RDD执行算子,获取不同的RDD,都会对这个RDD以及这个父RDD以及之前的 RDD都重新计算一遍,这种情况一定要避免!一旦出现RDD重复计算,会导致性能急剧下降。
2.RDD重构与优化:尽量复用RDD,差不多的RDD可以抽取成为一个共同的RDD,反复使用。
3.公共RDD一定要实现持久化。如果正常持久化在内存,可能导致内存占用过大,这样也许会OOM内存溢出。考虑使用序列化的方式存在内存中,缺点是获取数据时需要反序列化,内存不够使用内存加磁盘,最次就是内存加磁盘加序列化。
4.为了数据的可靠性,且内存充,可以使用 双副本机制,进行持久化,进行容错。(内存资源极度充足 )
5.持久化示例:对RDD调用persist方法,并传入持久化级别
sessionid2actionRDD = sessionid2actionRDD.persist(storageLevel1.MEMORY_ONLY());
4.广播大变量:
1.默认,task执行算子中使用了外部变量,每个task都会获得一份变量的副本,map本身不小,消耗内存,比如task都用到1M的map,那么首先map会拷贝1000个副本,通过网络传输到每个task中,总共1G的数据,网络开销很大!也消耗时间。
2.map是占内存的,1000个map分布在集群中,会消耗1G内存,不必要的内存占用和就导致RDD持久化到内存的时候,放不下,只能写入磁盘,导致在磁盘的IO消耗
3.task在 创建对象时发现堆内存放不下所有对象,导致频繁的GC了,GC的时候,一定会导致工作线程终止,也就是导致spark暂时工作。
4.广播,Broadcast,将大变量广播出去,而不是直接使用。一个spark作业在运行时,首先会在本地的blockManager上寻找需要的map,如果没有,会去driver端拉取数据(map),下一次同blockManager上的其他task拉数据时就直接从blockManager上拉取数据。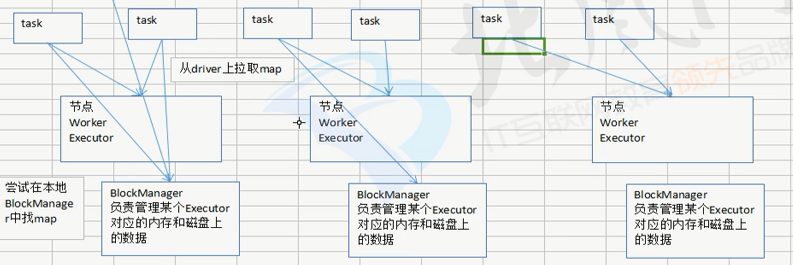
注意一点:blockManager会从driver端拉取数据,也可能从较近的blockManager上拉取对应的数据。broadcast(广播变量)初始时在driver有一份副本。task在运行时,使用广播变量的数据,此时首先在本地的Executor对应得blockManager中尝试获取变量副本,如果没有,就从driver端拉取变量副本,此后这个Executor上的task都会直接使用本地的广播变量副本。
5.如何使用广播变量:Broadcast<Map<String,Map<String,List<Integer>>>> dateHourExtractMapBroadcast = sc.broadcast(dateHorExtractMap);
就是用SparkContext 的broadcast方法传入要广播的变量
使用的时候直接用broadcast的.value方法或者.getValue方法就可以了。
6.使用Kyro序列化:set("spark.serializer",org.apache.spark.serializer.KyroSerializer")
1.默认情况:Spark使用Java的序列化机制ObjectOutputStream-ObjectInputStream,对象输入输出流数机制。优点是处理起来很方便,不需要手动做什么事情,只是在算子中实用的变量,必须实现Serializable接口,缺点是效率不高,速度比较慢。序列化后的数据占空间较大。
2.Kyro序列化:速度更快,序列化后的数据更小,大约是java序列化的十分之一(官网)。
3.序列化机制:算子中用的外部变量;持久化RDD;shuffle
4.Kyro没有被作为默认库的原因:要达到Kyro的最佳性能,就一定要注册你自定义的类,比如算子中使用的算子变量。否则达不到最佳性能。
5.如何使用:new SparkConf().set("spark.serializer",org.apache.spark.serializer.KyroSerializer").registerKyroClasses(new Class[ ]{})
7.使用FastUtils拓展集合类库:
1、介绍:提供了特殊类型的map,list,queue。提供了更小的内存占用,更快的存取速度。
2、使用:<dependency>(java7以上)
<groupId>fastUtil</groupId>
<artifactId>fastUtil</artifactId>
<version>5.0.9</<version>
</dependency>
3、使用场景:如果算子使用了外部变量,第一使用广播变量进行优化,第二可以使用Kyro序列化机制,第三,使用fastUtils库中的类
4、举例:比如List<Integer>对应的就是IntList
8.调节数据本地化等待时长:
1.相关术语解释:PROCESS_LOCAL:进程本地化,代码和数据在同一个进程内,即在一个Executor中,计算数据的task由executor执行,数据在对应的Executor的blockManager上,性能最好;
ONDE_LOCAL:节点本地化,代码和数据在一个节点上,数据作为HDFS block块,就在节点上,而task在节点上executor中执行,如果这两个节点不同,就需要进行进程间传输。
NO_PREF:对于task来说,数据从那里获得,没有好坏之分。
RACK_LOCAL:机架本地化,数据和task在一个机架的两个节点上,数据需要通过网络在两个节点传输。
ANY:数据和task可能在集群的任何地方,而不是一个机架上,效率最低。
2.spark.locality.wait:默认3s.
3.场景:spark在driver端,对Application的每一个stage的task,进行分配之前,都会计算每个task要计算的那个分片数据,RDD的某个partition,spark的分配算法,会希望task分配到他要计算的数据的节点上。这样就不用网络传输。
实际生产中,task可能没有机会分配到数据所在的节点,可能那个节点的计算资源和计算能力都饱和了,这个时候,spark通常会等待一段时间默认3s,(不是绝对,对于不同的本地化策略都回去等待),到最后,实在等待不了了,就会选择一个比较差的本地化级别,比如将task分配到离数据较近的一个节点上。
对于这种情况,一般来说,肯定要发生数据传输的,task通过所在节点blockManager获得需要数据,发现没有,通过调用一个getRemote()方法,通过TransferService从数据所在节点上获取数据。这样的话性能一定会下降,以及磁盘IO都是性能杀手。
4:何时调节这个参数?
观察日志,是Spark运行日志,观察task的本地化级别。如果大多是PROCESS_LOCAL,那就不用调节。如果发现都是NODE_LOCAL,ANY.那就调一下等待时长。
5.怎么调节:spark.locality.wait :默认3s->6s,9s(不要加s)
spark.locality.wait.process,spark.locality.wait.node,spark.locality.wait.rack,同理。
9.JVM调优之降低cache操作的内存占比:jvm相关参数通常不会造成太严重的性能问题,更多的是在troubleshooting中占据重要地位。
1.jvm相关知识回顾:堆内存:存放创建的对象,分为两块:old generation (老年代) young generation (年轻代),年轻代内部分为三块eden和两个survivor,spark的算子函数创建的的对象会放入年轻代中的Eden和一个survivor中,另外一survivor空闲,Eden和survivor存满后,会导致小型的垃圾回收minorGC,把不使用的对象清除,存活下来的对象放入空闲的survivor中。默认内存大小占比eden:survivor1:survivor = 8:1:1。如果存下来的对象是1.5,一个survivor放不下,此时可能通过jvm的担保机制放入老年代。如果内存不够会导致频繁minorGC, 会导致有些对象多次回收没有回收掉,这种短生命周期对象经过多次回收年龄过大,跑到老年代。老年代中可能因为囤积了大量这种对象,导致内存不足,会导致老年代频繁满溢,频繁进行FullGC,由于老年代的回收算法是针对数量很少,回收频率低的对象,耗费时间和性能的算法,会消耗大量时间和性能。,fullGC很慢。无论是minorGC还是fullGC都会导致工作线程停止(stoptheworld)
2.调优第一点:降低cache操作的内存占比。在spark中,堆内存又被分为了两块,一块专门为了RDD的cache和persist等操作进行数据缓存用的。另一块是用来给spark算子创建对象用的。默认情况下,给RDD cache的内存占比为0.6,60%的内存给cache占用,问题是在某些作业中,cache操作不是那么必须,而又要进行大量的算子操作创建大量的对象,内存就不够用了。就会导致频繁的minorGC甚至是fullGC,就导致spark停止工作了。
3如何做:查看spark工作UI。如果有gc频繁,就适当降低cache内存占比。参数设置:spark.storage.memoryFraction:0.6->0.5->0.4
10.调节executor堆外内存与连接等待时长
1.问题诊断:spark处理数据量特别大,运行时经常报错,可能是executor堆外内存不够用,导致堆外内存溢出。
2.如何调节:在spark-submit脚本里,用--conf方式去添加配置,只能在脚本里里配置,在setConf模式没有用!
3.调节多大:--conf spark.yarn.executor.memoryoverhead =2048 ,堆外内存默认300多M,实际调节到1G或者以上。
4.问题诊断:当executor要进行远程拉取数据时,正好碰上垃圾回收GC,就会卡住,没有响应,spark默认的网络连接超时时间为60s,如果60s都无法建立连接,就宣告连接失败。报错几次后spark作业奔溃。
5.如何调节:同上:--conf spark.core.connection.ack.wait.timeout =300
11.shuffle调优之合并map端输出文件:new SparkConf().set("spark.shuffle.consolidateFiles","true")
1.不合并会怎样:以实际生产配置为例:100个节点,每个节点一个executor有2个core,1000个task,每个executor分10个task,则每个task会输出10*1000=1万个文件,总共多少个文件100*1万=1百万!个文件。而shuffle中的写磁盘操作,基本上就是最消耗性能的部分。
2.开启参数后:第一个stage执行完2个task后,在执行另外2个task后,不会重新创建输出文件,而是复用刚才创建的文件,将输出数据写入上一批task的输出数据中。
第二个stage拉取数据时就不会拉取每一个task输出的数据,而是拉取少量数据,每个task可能包含了多个map端的输出数据。
此时的输出文件:每个节点:2*1000=2000 总共 100*2000=20万 比起之前立减5倍!对于实际生产中的性能提升还是很可观的,以前需要5个小时,优化后可能变成三个小时或更少。
12.shuffle调优之调节map端内存缓冲与reduce端内存占比
1.reduce task,在聚合等操作时,使用的是自己对应得executor内存,默认给reduce task 进行聚合的比例是0.2,这样拉取的数据很多 ,在内存中放不下,这个时候默认行为是将放不下的数据写到磁盘中
2.map端内存缓冲每个task是32kb,reduce端聚合 内存比例是0.2.
3.在map task处理的数据比较大的情况下,而task内存缓冲比较小,可能造成map端往磁盘溢写,更要命的是,磁盘溢写的数据越多,可能多次读取瓷盘中的文件。
4.调节参数:map task内存缓冲:spark.shuffle.file.buffer reduce端聚合内存占比:spark.shuffle.memoryFraction ,0.2。调节的时候,buffer每次扩大一倍,64,128然后看效果,memoryFraction每次提高0.1。
5.如何调节:看Spark UI 4040端口,或者yarn界面。
13.shuffle 调优之HashShuffleManager与SortShuffleManager。
1.spark1.2.x版本以后默认的是sortShuffleManager。(之前的是HashShuffleManager)
2.SortShuffleManage与HashShufflemanager有俩点不同;
1.SortShuffleManager会对每个reduce task要处理的数据进行排序(默认)
2.SortShuffleManager会避免HashShuffleManager那样,默认创建多份磁盘文件,每个task只会写入一盒磁盘文件,不同的task数据,用offset划分界定。
3.spark1.5.x后出现新的manager tungsten-sort(钨丝),唯一你不同之处,是钨丝manager是使用了自己实现的内存管理机制,性能大幅度提升,而且可以避免shuffle中的各种内存溢出。
3.如何选择:需要对数据排序就用SortShuffleManager,不需要就使用HashShufflemanager,因为排序是消耗性能的。
4.参数设置:new SparkConf().set("spark.shuffle.manager","hash") 默认为sort
14.算子调优之MapPartition提升Map类操作性能:
1.普通map操作与mapPartition比较:普通map 操作,如一个partition里面有1万条数据,那么你的function要执行和计算1万次。但是用MapPartition 后,function只会执行一次,function会一次接受一万条数据。
2.mapPartitions的缺点:对于大量数据来说,甚至一个partition100万数据,一次传入一个function后导致内存不足,有没有办法腾出更多的内存,就会导致OOM。
15.算子调优filter过后使用coalesce减少分区数量
1.问题分析:经过filter之后,RDD每个partition中的数据量,可能不太一样。
1.每个partition数据量变少,但是还要有和partition数量的task来处理。
2.会导致后面每个task要处理的数据量不同,就很容易发生数据倾斜,不同task处理的数据量可能在9倍10倍以上,那么处理速度就会有10倍以上的差距,就会导致有的task运行很快,有的很慢,这就是数据倾斜。
2.解决方案:对于第一个问题,进行partition压缩。第二个问题,也一样。总结就是使得每个task处理的数据量均匀。
3.解决算子:coalesce算子,压缩partition。实例:sessionid2dataRDD.filter(new Function(){}.coalesce(100)
16.算子调优之使用foreachPartition优化写数据库性能:
1.默认foreach的缺陷:对于每一条数据,task都要去执行function函数,如果有100万数据,就要执行100万次,性能差;如果每条数据都要创建一个数据库连接那就得创建100万次数据库连接,以及发送100万条sQL语句,非常消耗性能。
2.foreachParttion算子好处:1.调用一次,传入一个Partition所有数据;2.主要创建一个数据库连接就行;3.只要向数据库发送一次SQL语句和参数即可。
3.注意点:如果一个分区数量特别大,还是会发生OOM。
17.算子调优之使用repartition解决 SparkSQL 低并行度的性能问题。
1.并行度的生效范围:Spark SQL的stage并行度你无法指定,SparkSQL会自己根据hive表对应的hdfs文件的block,自动设置并行度。
2.解决办法:rePartition算子,你可以将SparkSQL查询出来的 RDD使用repartition算子,然后repartition后的RDD,再往后,并行度和task数量就会按照你的预期来了,就可以避免跟SparkSql绑定在一个stage的中的算子,只能使用少量的task去处理大量的复杂逻辑。
3.使用:return actionDF.JavaRDD().repartition(1000);
18.算子调优之reduceByKey本地聚合介绍:
1.特点:会进行map端的本地聚合,即map端的每个task输出文件中,写数据之前,也会进行本地的combiner,也即是对每个key,都会执行算子(_+_)
2.性能的提升:在本地聚合之后,在map端的数据量减少了减少磁盘IO,而且减少磁盘占用;下一个stage拉去的数据量变少,减少网络传输开销;reduce端数据缓存的内存减少;reduce端 的聚合数据减少。
3.使用场景:对于复杂场景,有的时候也可以使用。
19.troubleshooting之控制shuffle reduce端的缓冲大小以避免OOM
1. shuffle原理深入:map端task不断输出数据,数据量很大,但reduce端的task并不是等到map端的task将属于自己那份数据全部写入磁盘后才开始工作,而是拉取一部分就立即进行聚合,算子函数的运用。每次reduce拉取多少数据就由buffer决定。然后再由executor中的对内存占比0.2,去进行后续的函数。
2.reduce端buffer可能出现的问题:buffer默认48M,大多数不会出现问题,有的时候map端数据量特别大,写的速度特别快,reduce端的task拉取的时候达到自己缓冲的最大极限值,48M。这个时候再加上,reduce端聚合代码的执行,可能创建大量对象,内存就撑不住了就会OOM,发生内存溢出。
3.解决办法:减少reduce端缓冲大小,调成12M。不容易OOM,但是性能有所下降,因为拉取的次数就多了,走更多的网络传输。
4.性能调优:如果map端数据量不大而且资源充足,可以适当调大reduce缓冲大小
5.参数调节:spark.reducer.maxSizeInFlight,24(默认48)
20.troubleshooting之解决JVM GC导致的shuffle文件拉取失败
1.原理:executor的JVM进程内存不够了,那么执行GC,一旦发生就会导致executor内的所有工作进程停止,task想要拉取上一个stage的数据就会报shuffle file not found,下一次提交就可能没说这个问题了,疑问GC结束了。
2.解决办法:调节两个参数:
1.spark.shuffle.io.maxRetries 3:-60表示shuffle文件拉取的时候,如果没有拉到,最多重试几次,默认三次。
2.spark.shuffle.io.retryWait 5s -60:表示假如第一个stage的executor正在进行漫长的等待,第二个executor尝试去拉取文件,结果没有拉到,默认会重复拉取3次,每次间隔5s,最多等待3*5=15s,没有啦到就会报出shuffle file not found异常。
3.最大忍受1个小时60*60
21.troubleshooting之解决yarn队列资源不足导致的application直接失败。
1.在j2ee平台限制同时只能提交一个spark作业到yarn上执行,确保一个spark作业资源是有的。
2.采用简单的调度方式,将长时间的作业和段时间的作业区分开,即两个调度队列,这样避免了长时间的作业阻塞段时间的。
3.你的队列无论何时都只有一个作业再跑,再运用性能调优,尽量让每次spark作业都能达到最满的 资源使用率,最快的速度,最好的性能。
4.如何做:ExecutorService ThreadPool =Executor.newFixedThreadPool(1);
22.troubleshooting之解决各种序列化的报错
1.几种序列化报错:log出现Serializable,Serialize,即序列化报错
2.注意三点:1.算子函数中使用外部定义类型变量,要求必须可序列化
2.如果将自定义类型,作为RDD的元素类型,那么自定义类型也必须实现序列化
3.不能在上述两种情况下,使用第三方不支持序列化类型。(Connection)
23.troubleshooting之解决算子函数返回null导致的问题
1.对于某些值,不想有返回值直接返回null会报错。例如Scala.Math(null)
2.解决办法:返回特殊的值比如“-999”
3.如:filter之后使用coalesce压缩RDD的partition数量让各个partition数据比较紧凑。
24.troubleshooting之yarn-client导致的网卡流量激增问题
1.问题产生:由于driver是启动在本地机器,而driver全权负责所有任务调度,也就是说要和yarn上集群运行的多个executor频繁通信(task的启动消息,task的执行统计消息,task的运行状态,shuffle的输出结果)。本地机器在30分钟内可能进行大量的网络通信,导致本地机器网卡流量激增!大公司对每个机器使用情况都有监控,不允许单个机器耗费大量网络带宽等等。
2.解决方法:yarn-client 模式只会使用在测试环境中。测试行为是偶尔行为,还可以在本地机器看到详细全面的log,解决线上报错,进行性能观察,并进行性能调优。生产环境就都用yarn-cluster,就不会出现这样的问题。
25.troubleshooting之yarn-cluster模式的JVM的栈内存溢出问题。
1.问题:运行spark SQL作业可能会遇到在yarn-client可以运行,而yarn-cluster不能运行,会报出JVM的PermGen(永久代)内存溢出OOM。yarn-client模式下driver运行在本地机器上,spark使用的是JVM的PermGen配置,永久代大小是128M,在cluster模式下,driver运行在某个节点上,使用的是没有配置的PermGen:82M。所以如果对用永久代的需求超82M就有问题了,报PermGen out of memory。
2.解决方法:多设置一些:--conf spark.driver.extraJavaOptions="XX:PermSize=128M -XX:MaxPermSize=256M"
26.troubleshooting之错误的持久化方式以及checkpoint使用
1.userRDD.cache() userRDD.count() userRDD.take() 报错!
2.正确使用方式,val cachedUserRDD =userRDD.cache()
3.使用checkPoint的时机:计算某个RDD非常耗时,持久化一份到文件系统(hdfs),可靠但消耗性能
4.如何使用:1设置checkpoint目录sc.checkpointFile("/hdfs://") actionRDD.checkpoint()
27.数据倾斜方案之原理及现象分析。
1.数据倾斜的原理:例:90万数据三个task,平局来说每个task分到30万数据。在shuffle过程中,同一个key一定分配到一个reducetask处理。多个key对应的value总共是90万。某个key 对应88万数据,分配到一个reducetask上。前两个各分匹配1万数据,需要10分钟,那么第三个就要88*10=880分钟=15小时!!!这种情况就属于数据倾斜 。
2.数据倾斜的现象:1.大部分task,执行很快,剩下几个task执行特别特别慢,比如剩下1个2个,执行23个小时,出现数据倾斜;2.其他task很快,突然报OOM,反复几次就挂了。task分配的数据量太大,内存放不下。
3.定位与出现问题的位置:基本上只有shuffle的操作才可能出现数据倾斜。看看那些地方使用了产生shuffle的算子groupByKey() countByKey(),reduceByKey(),join,或者看log,看看执行到那个stage。
28.数据倾斜之聚合数据源以及过滤掉导致倾斜的key
1.在生成的hive表的etl中,对数据进行聚合,比如按照key 分组,将key对应的所有values,用特殊的格式拼接起来比如“key=sessionid,value:action_seq=1|user_id=1|search_keyword=火锅”。对key进行group。在spark中拿到key=sessionid,values<Iterable>hive etl中,直接对key 进行聚合。也就意味着每个key对应一条数据。在spark中就不用执行grouByKey这种操作了,直接对key 对应的values字符串map操作即可,就不需要执行shuffle 操作,也就不会导致数据倾斜了。
2.可能无法对每一个key聚合出一条数据,妥协的办法是,放粗粒度。如10万条数据里包含了几个城市,几天,几个地区的数据,现在放粗粒度,直接对城市粒度进行聚合,尽量去聚合,减少每个key对应的数据量。
3.对于spark程序来说,完全可以把aggregateByKey放到hive etl中来做,形成一个新表,对于每天用户访问行为,都按照session粒度聚合,写一个hive sql。在spark中就直接怂session聚合表中用sparksql查询对应的数据即可。
4.第二个方案:过滤掉导致数据倾斜的key。如果可以接受,在hive表中查询时直接用where条件过滤掉某几个key
29.数据倾斜解决方案之提高shuffle操作reduce并行度
1.将reduce task的数量变多,就可以让每个reduce task分到的数据量更少,这样也许就可以缓解甚至是基本解决数据倾斜的问题。
2.如何操作:主要给shuffle算子,比如groupByKey,countBykey,reduceBykey,在调用的时候,传入一个参数,一个数字,对应的就是reduce端的并行度。如原本task数据特别多,直接OOM,程序没跑,传入并行度以后至少可以避免OOM,让程序可以正常运行。
3.缺点:治标不治本,没有从源头解决数据倾斜问题,只能缓解和减轻shuffle和reduce task的数据压力。
4.实际生产的经验:如果之前task运行缓慢,要5小时,,现在稍微块一点4小时,出现这种情况直接使用后面的方法。
30.数据倾斜解决方案之使用随机key实现双重聚合
1.原理:第一轮聚合对key进行打散,将原先一样的key变成不一样的key,进行局部聚合,然后在去掉每个key的前缀,再对所有key进行全局聚合,对groupByKey,reduceBYKey,有比较好的效果。
2.如何使用:1.打上随机数:Random random = new Random();
int prefix =random.nextInt(10);
return new Tuple2<String ,Long > (prefix +"_"+tuple._1,tuple._2);
2.执行第一轮聚合: mappedClickCategoryRDD.reduceByKey();
3.去除前缀:long categoryid = Long_valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long,Long>(categoryId,tuple._2);
4.进行全局聚合:resoredRDD.reduceByKey();
31.数据倾斜解决方案之将reduce join 转化为map join
1.适合场景:如果两个RDD进行join ,其中一个RDD比较小,比如一个是1亿数据,另外一个是100万数据,必须一个比较小。因为小的RDD需要进行broadcast,以后在每个executor中驻留一份,确保内存足够存放小RDD的数据。如果两个都比较大,很可能导致内存,不足,最终导致内存溢出。这种方式下就不会发生shuffle,也就不会有数据倾斜产生,join中you数据倾斜,优先考虑这种方式解决。
2.使用: 1.将小的RDD做成广播变量:Broadcast <List<Tuple2<Long,Row>>> userInfoBroadcast = sc.broadcast(userInfo);
2.大的RDD进行map操作:userid2PartAggrInfoRDD.mapToPair()
3.总结:对于join操作,优先考虑使用reduce join转 map join,在牺牲一点内存资源的情况下,这么使用会提高性能。
32.数据倾斜解决方案之smple采样倾斜key单独进行join
1.原理:关键之处在于将发生数据倾斜的key拉出来,放到一个RDD中,就用原本会发生数据倾斜的keyRDD和其他RDD单独join,这个时候key对应的数据就会分散到多个task中去join操作。
2.合适使用:优先对于join,对于你的RDD数据可以转换成中间表,或者直接用countByKey查看各个RDDkey对应的数据量,如果发现RDD比较少建议拉取出来比如就一个key对应的数据比较多。
3.实际使用:1.sample随机采样sampledRDD=user2PartAggrInfoRDD.sample(false,0.1,9);
33.数据倾斜之使用随机数以及扩容表进行join
1.描述:该方案没法彻底解决数据倾斜,更多是缓解。
2.使用:1.选择一个RDD用flatMap进行扩容,将每条数据映射为多条数据,每条映射出来的数据都带了一个n以内的随机数,通常n=10
2.将另外一个RDD,做普通map映射操作,每条数据都打上1到10 的随机数。
3.最后,将两个处理后的RDD进行join。
3.局限性:两个RDD都很大,没法扩的很大,而且数据倾斜只能缓解而无法彻底解决。