工作中不免会有碰到服务器磁盘空间不足,需要另外挂载磁盘上去的时候,这时候问题就来了,怎么能让datanode将数据写入新挂载的磁盘呢?
1、配置hdfs-site.xml
<property> <name>dfs.datanode.data.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/data1,file:///sdb1/dfs/data2</value> </property>
2、数据存放策略
参考大佬博客 https://blog.csdn.net/bigdatahappy/article/details/39992075
默认为轮询,现在的情况显然应该用“选择空间多的磁盘存”模式
配置hdfs-site.xml
<property> <name>dfs.datanode.fsdataset.volume.choosing.policy</name> <value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value> </property>
3、开启 数据均衡
bin/start-balancer.sh –threshold 10
##停止命令
bin/stop-balancer.sh
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
注意点
在实际运行时发现datanode节点起不来,报错
org.apache.hadoop.util.DiskChecker$DiskErrorException: Too many failed volumes - current valid volumes: 1, volumes configured: 2, volumes failed: 1, volume failures tolerated: 0
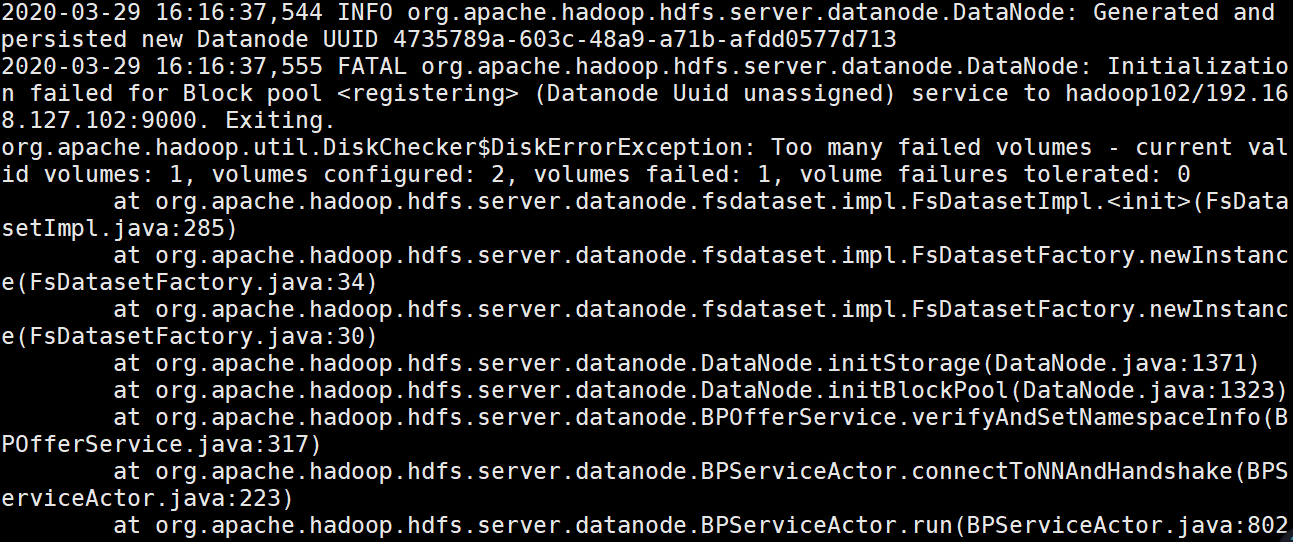
经过检查,是因为在102(新增硬盘的主机)配置了hdfs-site.xml 后,分发给了其他没有新增硬盘的主机,启动时因为没有检测到新的硬盘,所以会报错,这里建议千万不要分发hdfs-site.xml