hadoop官方案例
官方Grep案例:grep:通过指定好的正则,匹配输入文件中满足条件规则的单词并且输出
首先进入到安装hadoop里的目录,然后创建一个文件夹input(叫什么名都可以),创建一个文件,输入单词,如下图

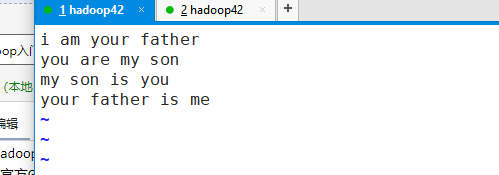
a.txt内容如下,输入完内容后保存退出

回到hadoop安装目录,执行语句hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output1 'hdfs[a-z0-9]+'
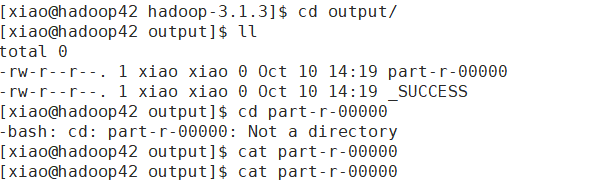
output1系统会帮我们创建。input是我们输入文件,系统会遍历该目录里的所有文件 hdfs[a-z0-9]+我们写的正则表达式.重要一点:输出目录必须是不存在的,如果存在会报错。执行命令,执行完后进入output1目录里
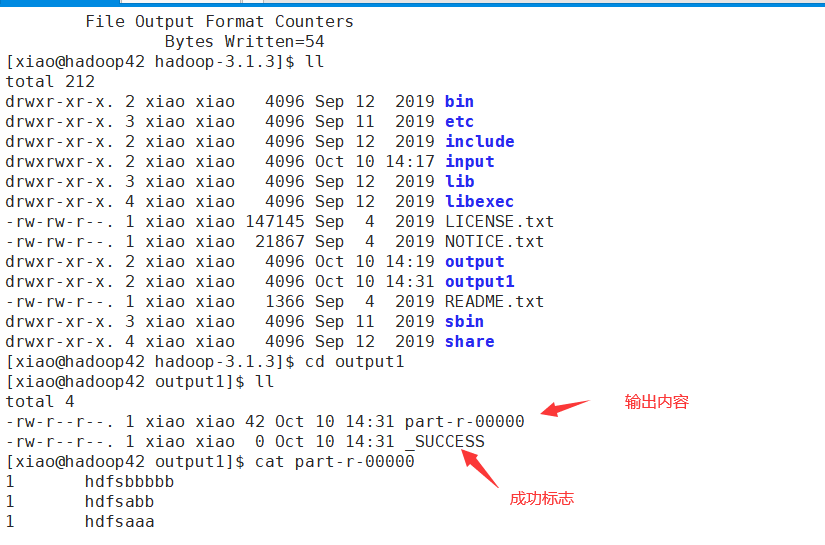
如果执行成果了,发现内容为空,但是有成功标志,往上看消息,如果有下图错误,只需要将配置文件中将每个task的jvm进程中的-Xmx所配置的java进程的max heap size加大

进入到/opt/module/hadoop-3.1.3/etc/hadoop/ 目录里,编写hadoop-env.sh文件vi hadoop-env.sh,添加或修改为export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"来增加java可用的最大堆内存大小,最后运行 grep命令(别忘了输出路径,必须是不存在的)
官方WordCount案例
和Grep案例一样,在hadoop安装目录创建一个文件夹,在文件夹创建一个文件,并输入单词,单词之间以空格隔开,如下图

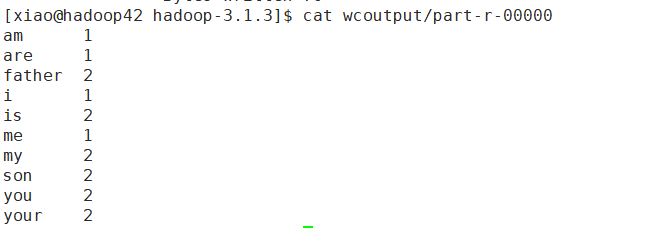
回到hadoop安装目录,执行命令hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput,查看输出文件