相关文章链接
CentOS7安装CDH 第二章:CentOS7各个软件安装和启动
CentOS7安装CDH 第四章:CDH的版本选择和安装方式
CentOS7安装CDH 第五章:CDH的安装和部署-CDH5.7.0
CentOS7安装CDH 第六章:CDH的管理-CDH5.12
CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
CentOS7安装CDH 第八章:CDH中对服务和机器的添加与删除操作
1. 静态资源池
在CDH中,一般情况下不建议使用静态资源池,在CDH中默认的资源池是动态资源池,为什么不建议使用静态资源池,原因如下:
假设给NodeManager分配了4G内存,刚刚开始使用的时候使用了3G,一段时间后任务增多,使用到了4G内存,当任务再增多时,静态资源池会OOM,但动态资源池会从其他地方调集资源过来接着使用。
2. 动态资源池的三种默认使用池
1、使用池已在运行时指定 ,如果该池不存在则加以创建:
hadoop jar -Dmapreduce.job.queuename=etl xxx.jar
假如有资源池就使用etl,没有创建etl
2、使用池 root.users.[username] ,如果该池不存在则加以创建:
hadoop jar xxxx.jar
以root来提交 root.users.root
以hdfs来提交 root.users.hdfs
3、使用池 root.default:
此规则始终满足。不会使用后续规则
3. 使用动态资源池
3.1. 动态资源池的其中2种性质
1、根据多个项目一个大的资源池的性质:
A项目(spark streaming),B项目(spark sql/hive)
一个项目:
spark streaming 10%
hive 30%
spark sql 60%
---Dmapreduce.job.queuename=root.sparkstreaming
2、根据一个项目一个大的资源池性质:
生产项目product,开发项目develop, 测试项目qa, 默认资源池
人员:
product1、product2: product
develop1、develop2: develop
qa1、qa2: qa
3.2. 配置动态资源池示例
1、创建资源池product,develop,qa和default,这些都是root的子资源池,其中内存和CPU可以自己设置,但一般不设置,就只设置权重就可以了,记得修改后要刷新动态资源池:


2、创建我们自己的放置规则:

当product1用户提交hadoop jar xxxx.jar命令时,是使用的哪个资源池?
product1用户提交的时候,取用户组是product,拼接root.product
此时判断root.product池在不在系统配置里?
假如在,就使用root.product,假如不在,第二条规则
3、配置CDH集群的Java Home目录:

在所有主机界面的配置选项中,使用安装JDK建议使用tar包解压安装,解压的目录为/usr/java下,配置好Java Home目录后请到CDH主界面更新配置,如果不更新那该资源就不会生效。
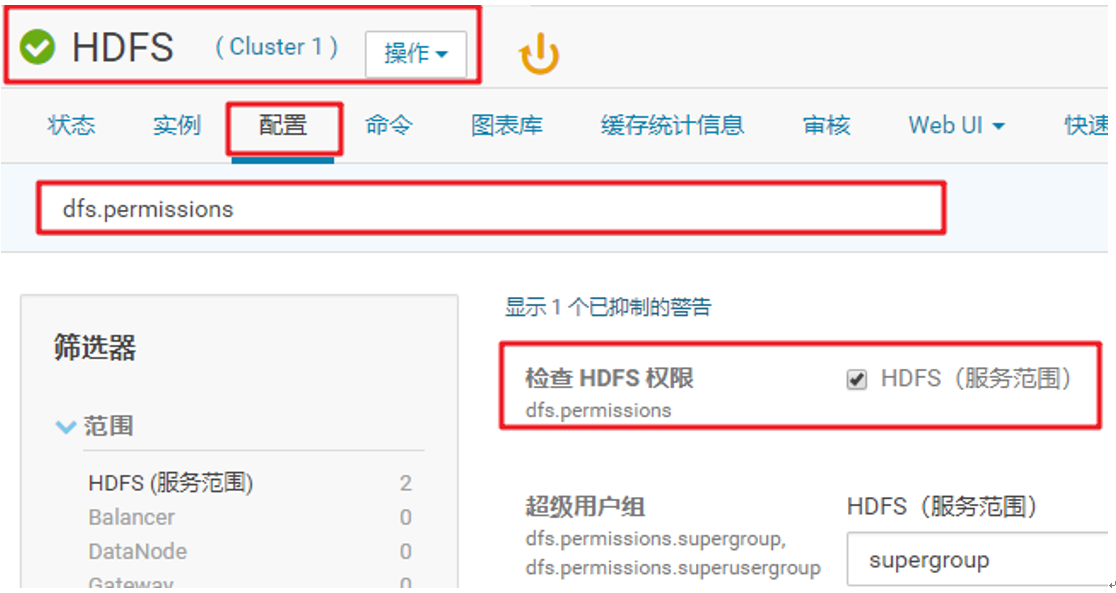
4、开启HDFS权限检查(dfs.permissions):
5、创建用户组和用户:

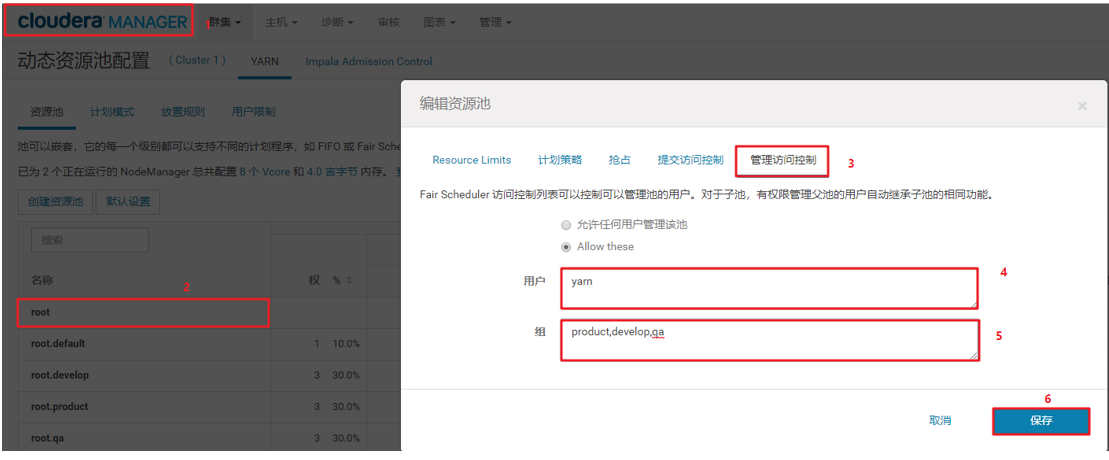
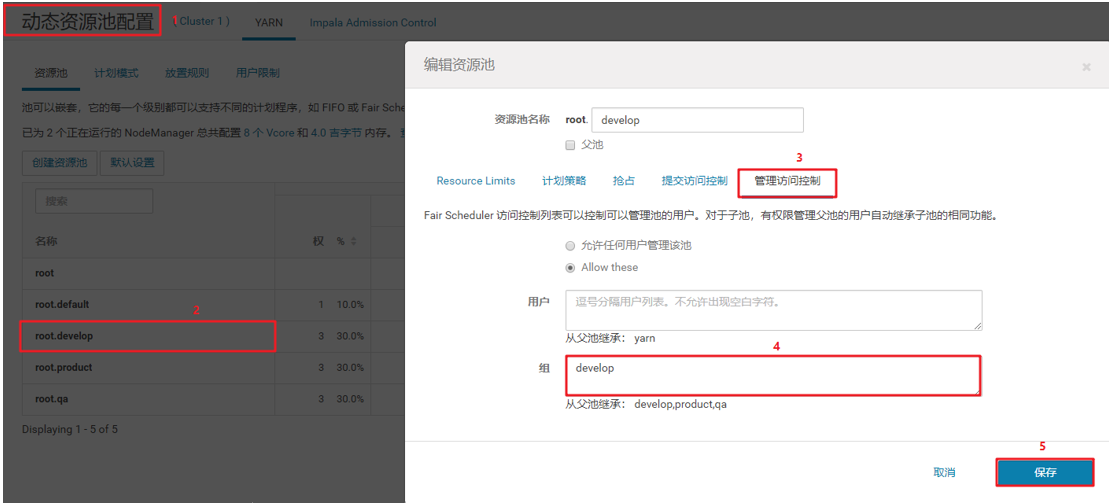
6、开启资源管理器ACL和设置相应的用户或者用户组:

管理ACL的格式为:" 以逗号分隔的用户列表+空格+以逗号分隔的用户组列表" ,例如 "user1,user2 group1,group2"
7、不允许未声明的池:

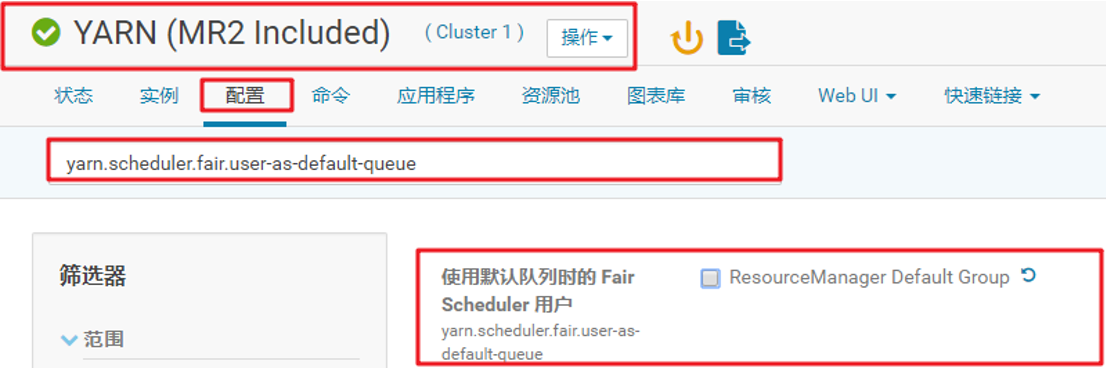
8、不使用默认队列时的 Fair Scheduler 用户:
9、生效配置,重启服务:
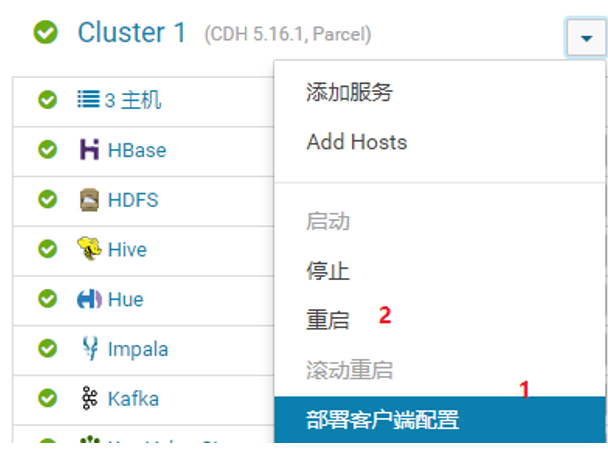
或点击电源按钮。
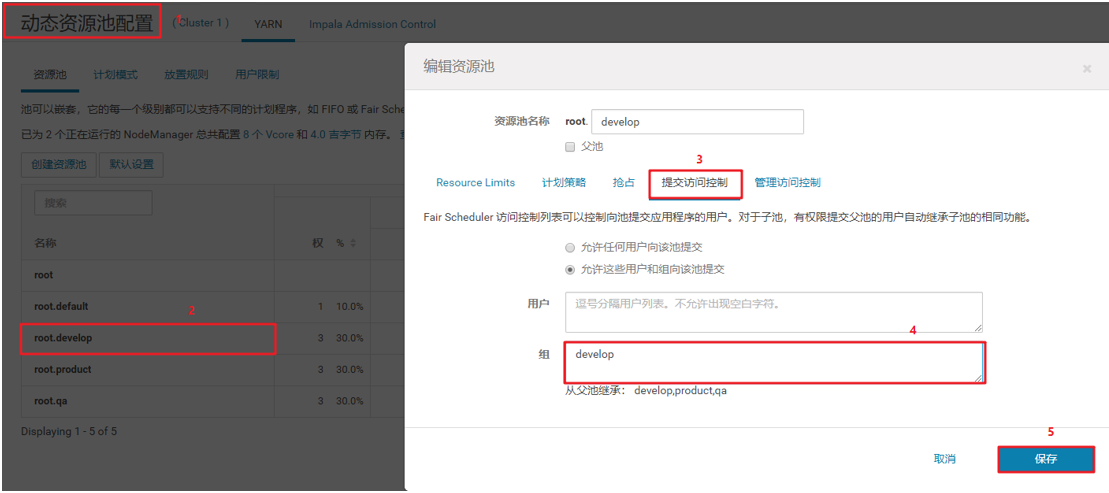
10、提交访问控制:
对root用户进行设置:

对其他用户进行设置,以下以develop举例,其他类似:
在动态资源池中主要刷新动态资源池就可以生效了,不需要重启服务。
3.3. 使用动态资源池示例
1、创建用户和用户组:

2、在HDFS中创建目录:
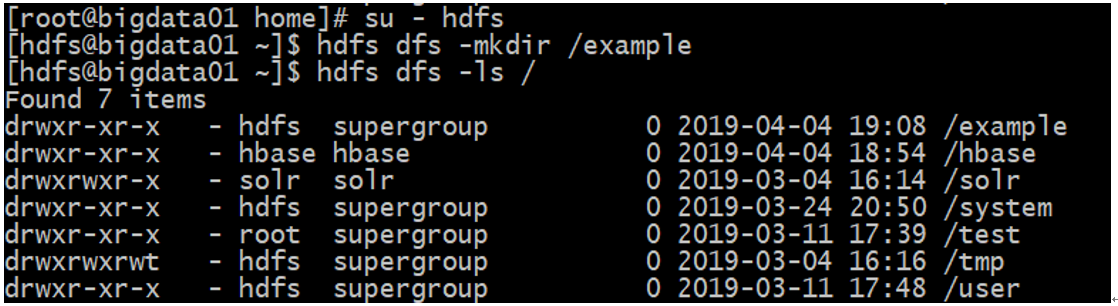
3、给创建的目录授权:
hdfs dfs -chmod -R 777 /example
4、使用product1用户上传一个文件到创建的目录下:
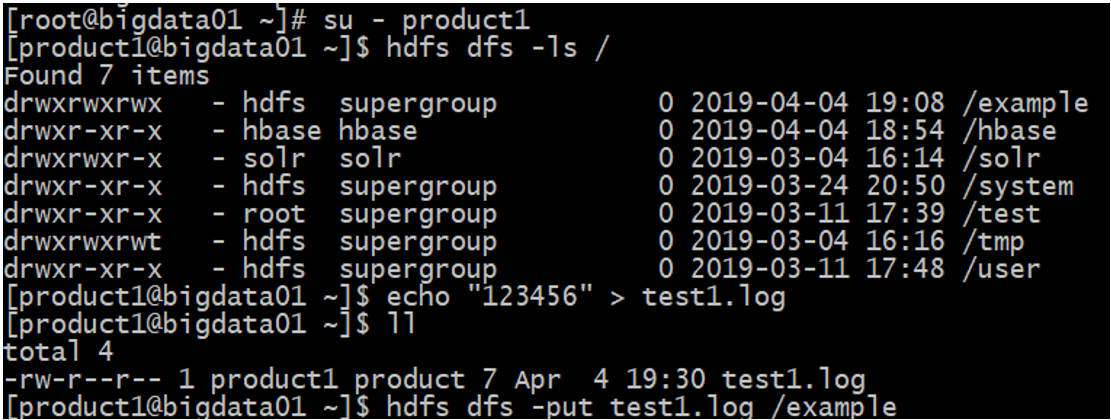
5、使用product1用户在HDFS中创建一个文件夹:

6、使用product1用户创建一个测试文件夹,并上传到/example/input/目录下:
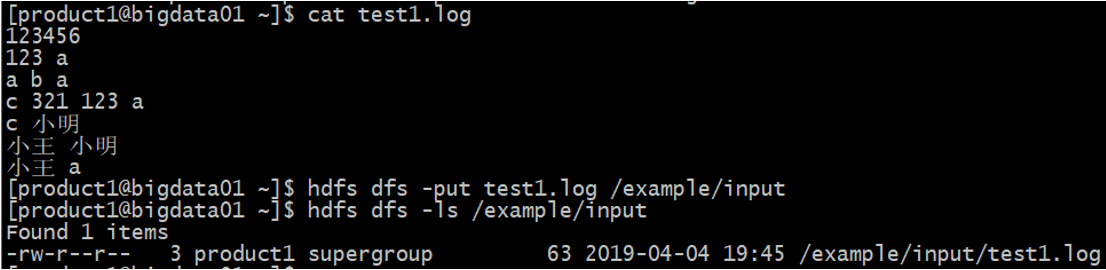
7、进入到hadoop的跟目录下,并找到hadoop自带的测试jar包:

8、使用product1用户执行此jar包下的wordcount程序:
hadoop jar
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.16.1.jar
wordcount
/example/input
/example/output1
错误一:/user目录访问权限问题,可以通过修改HDFS的/user目录权限解决

修改前:

修改命令(需使用hdfs用户来修改):
[hdfs@bigdata01 ~]$ hdfs dfs -chmod -R 777 /user/
修改后:
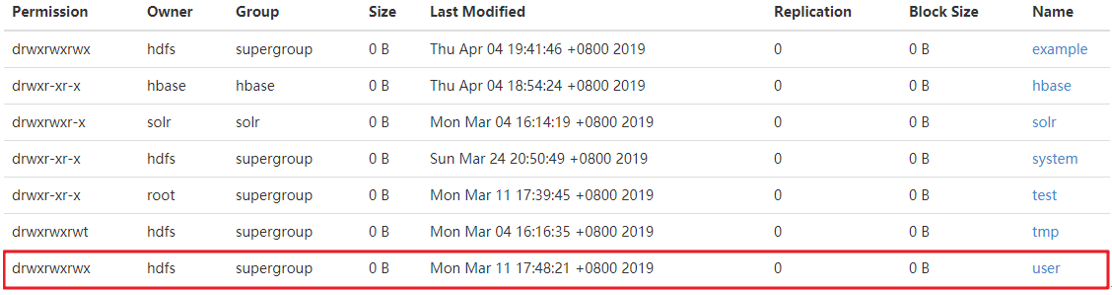
注:该文件列表中user文件夹可以进行修改,但一些业务数据的文件夹,比如hbase文件夹就不能进行修改了。
错误二:用户根无法向队列root.default提交应用程序

此错误为没有将任务提交到product资源池中,可以将default资源池池设置成所有用户都可以访问即可,还可以进行其他设置,请去百度查看。
3.4. 提交一个spark程序中遇到的问题
1、当在CDH中安装spark2后,提交spark程序的命令为spark2-submit ;
2、提交任务命令如下:
cd /opt/cloudera/parcels/SPARK2/lib/spark2/examples/jars
spark2-submit
--master yarn
--queue $QUEUE_NAME
--class org.apache.spark.examples.GroupByTest
spark-examples_2.11-2.2.0.cloudera4.jar
3、错误一
17/10/21 13:18:48 INFO spark.SparkContext: Successfully stopped SparkContext
Exception in thread "main" java.lang.IllegalArgumentException:
Required executor memory (1024+384 MB) is above the max threshold (1049 MB) of this cluster!
Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
at org.apache.spark.deploy.yarn.Client.verifyClusterResources(Client.scala:334)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:168)
需要在yarn中配置yarn.nodemanager.resource.memory-mb参数
4、错误二
job的日志 HDFS:
User [dr.who] is not authorized to view the logs for container_e25_1508567262904_0002_01_000001 in log file [i-bsbhj3uw_8041]
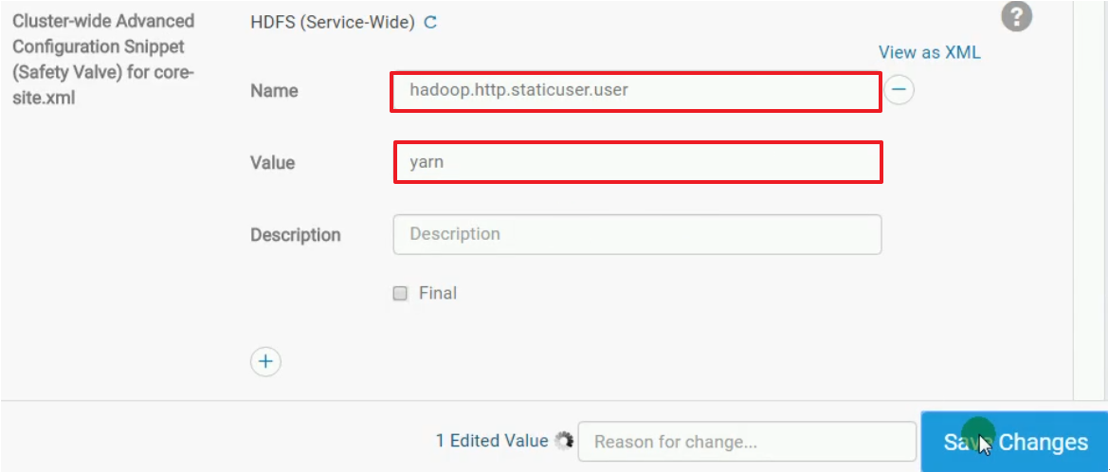
此时是没有权限访问hdfs中的日志,需要在hdfs的配置文件中查找core-site,然后添加如下配置: