集成学习方法(Ensemble Method)

1.Majority Voting
不同的模型
1.1 hard voting mode :取众数

1.2 为什么做majority voting?

1.3 soft voting


2.Bagging(Boostrap Aggregating)

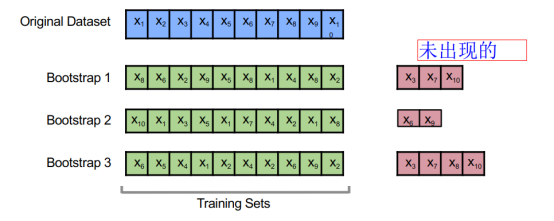
数据boostrap
把一个数据变成了n个数据集,再对n个数据集D_i,训练base分类器,训练n个分类器,把n个分类器的结果做众数。(相同的算法,只是数据变了)

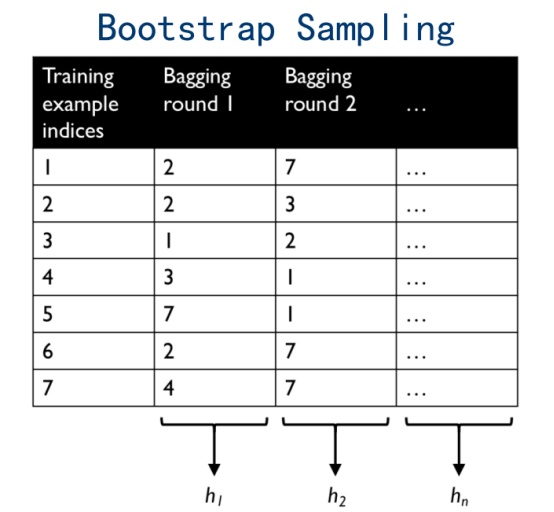
2.1Boostrap Sampling
有放回的随机采样,可能重复
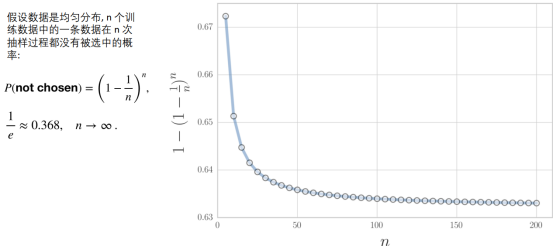
一个数据不被采样的概率会有多高
2.2 具体流程

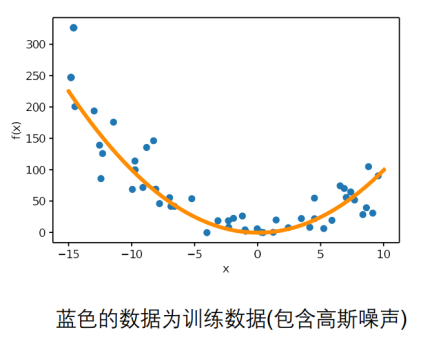
2.3 Bias-Variance 分解
Loss = Bias + Variance + Noise

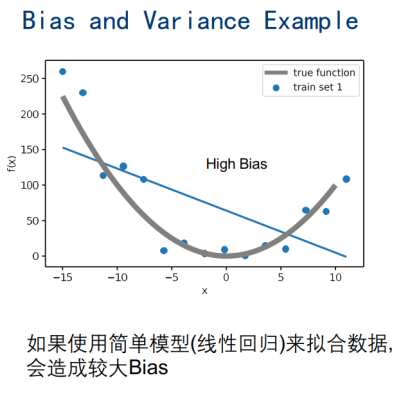
简单模型,Bia偏差太大
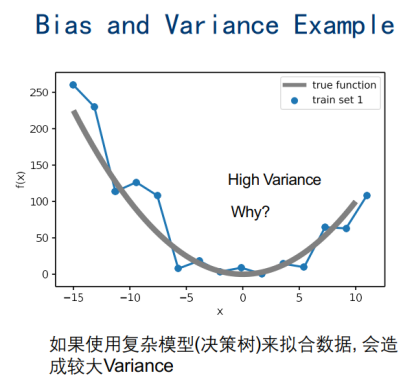
复杂模型,Variance方差,不一致性过大
Boostrap sampling后的:
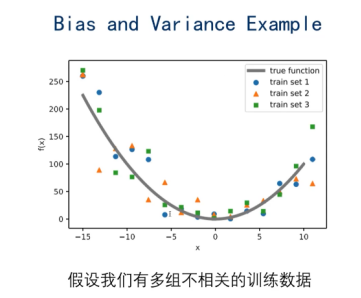
对模型求均值

3.Boosting
下一次训练的模型,是根据上一层的误差决定的,调整训练数据的权重
同一数据+同一模型
Adaptive Boosting,这里讲的是这个,把很简单的算法变得很strong
Gradient Boosting:eg:LightGBM,XGBoost
3.1 Adaboost过程
主要区别:如何训练每一个模型,如何集成模型


3.2 Adaboost原文过程


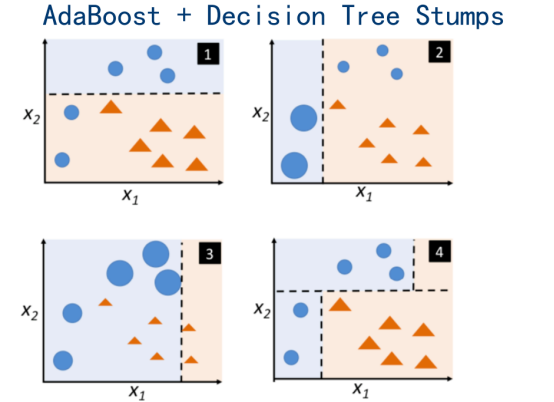
附加:决策边界
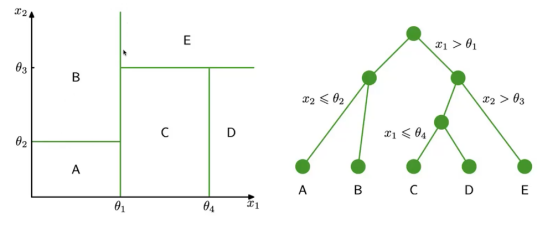
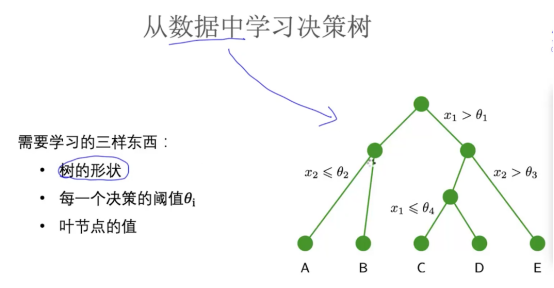
设计决策树:贪心算法
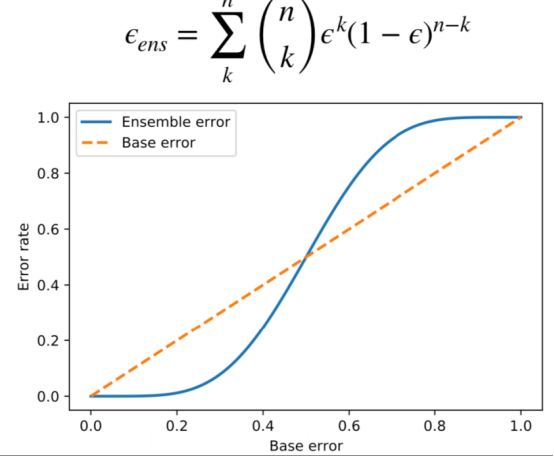
3.3 误差上限

4.Random Forests
把很多树集合起来
Random Forests = Bagging+ w.trees + random feature subsets
1998年,为每一颗树随机
2001年,为每一个树的节点(常用),每次分叉的时候,从所有的特征中随机的选取哪个子集的特征。
5. Stacking
1992年
输出作为第二次的输入
5.1 论文概述

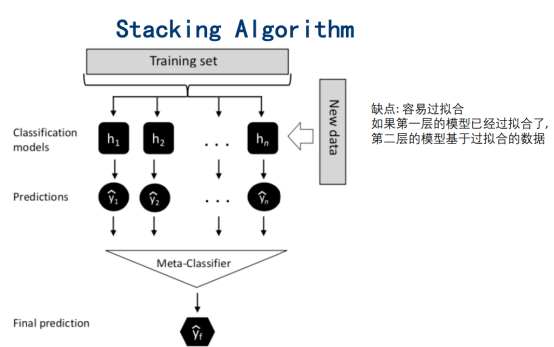
5.2 防止过拟