XPath是一门在XML文档中查找信息的语言,被用于在XML文档中通过元素和属性进行导航。
XPath虽然是被设计用来搜寻XML文档,不过它也能很好地在HTML文档中工作,并且大部分浏览器也支持通过XPath来查询节点。
1.XPath节点
在XPath中,XML文档是被作为节点树来对待的,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点
树的根被称为文档节点或者根节点。下面以一段XML文档为例:
<?xml version="1.0" encoding="UTF-8"?> <classroom> <student> <id>1001</id> <name lang="en">marry</name> <age>20</age> <country>China</country> </student> </classroom>
在上面XML的文档中,各个标签分别代表:
<classroom>:文档节点
<id>1001</id>:元素节点
lang="en":属性节点
marry:文本
在XML中,节点关系有以下几种:
父(Parent):例如student就是id、name、age、country的父亲
子(Children):id、name、age、country是student的儿子
同胞(Sibling):id、name、age、country等互为同胞关系
先辈(Ancestor):classroot是id、name、age、countryde
后代(Descendant):id、name、age、country都是classroot的后代
2.XPath语法
XPath使用路径表达式来选区XML文档中的节点或者节点集。节点是沿着路径(Path)或者步(steps)来选择。
下面是一个简单的示例文档:
<?xml version="1.0" encoding="UTF-8"?> <classroom> <student> <id>1001</id> <name lang="en">marry</name> <age>20</age> <country>China</country> </student> <student> <id>1002</id> <name lang="en">jack</name> <age>21</age> <country>USA</country> </student> </classroom>
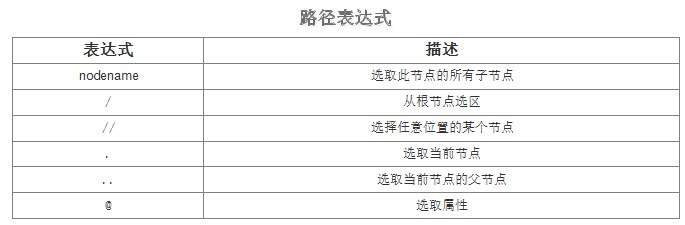
下面列举一些常用的路径表达式进行节点的选取:
下面是针对上面的文档进行节点选取的示例:
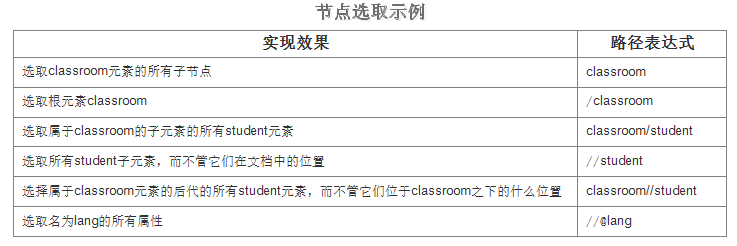
上面的示例都是选取所有符合条件的节点,但是如果我们要选取某个特定的节点或者包含某一个指定值的节点呢?
那么就要用到谓语,谓语被嵌在方括号中。下面是一些常规的谓语示例:
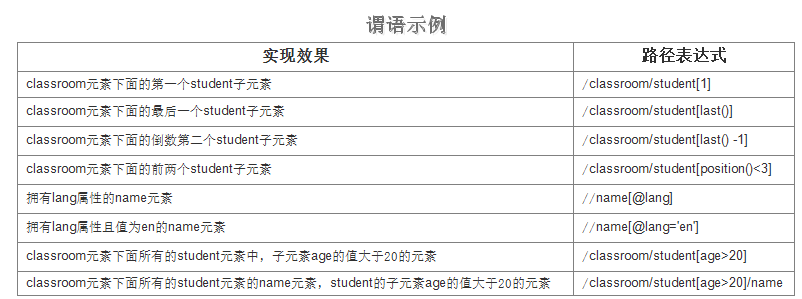
XPath在进行节点选取的时候可以使用通配符“*”匹配未知的元素,同时使用操作符“|”一次选取多条路径。下面是示例:

3.XPath语法
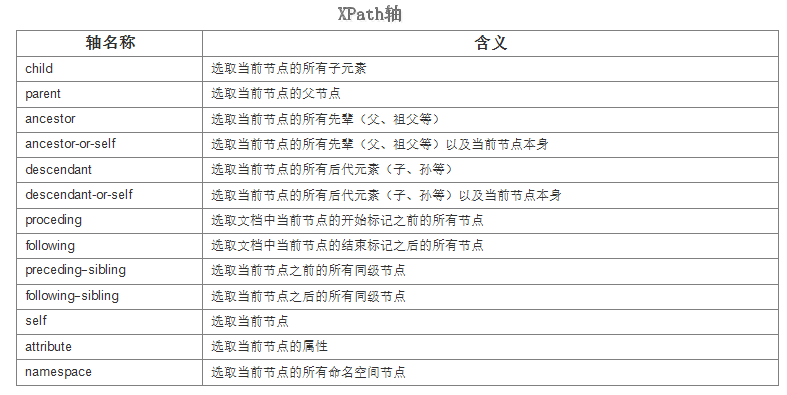
轴定义了所选节点与当前节点之间的树关系。
在python爬虫开发中,提取网页中的信息会遇到这种情况:首先提取到一个节点的信息,
然后想在这个节点的基础上提取它的子节点或者父节点,这个时候了就需要用到轴的概念。轴的存在会使提取变得更加灵活和准确。
在说轴的用法之前,需要了解位置路径表达式中的相对位置路径、绝对位置路径和步的概念。
位置路径可以是绝对的、也可以是相对的。绝对路径起始于正斜杠(/)。
步(step)包括:轴(axis)、节点测试(node-test)、零个或者更多谓语(predicate)。
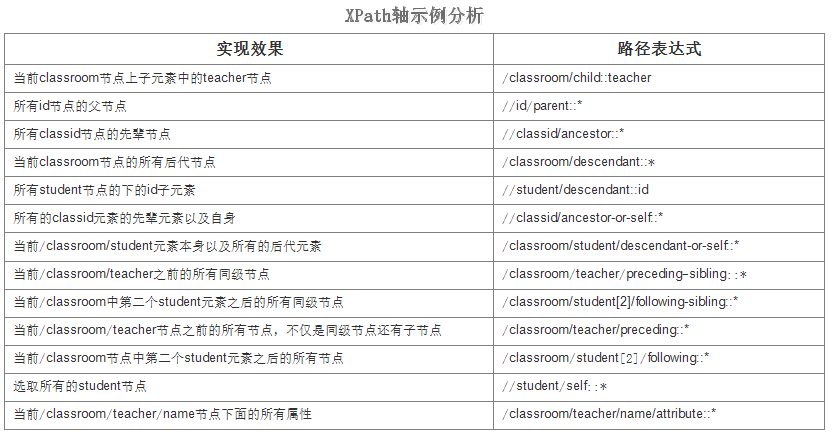
下面是一个简单的XML文档示例:
<?xml version="1.0" encoding="UTF-8"?> <classroom> <student> <id>1001</id> <name lang="en">marry</name> <age>20</age> <country>China</country> </student> <student> <id>1002</id> <name lang="en">jack</name> <age>21</age> <country>USA</country> </student> <teacher> <classid>1</classid> <name lang="en">jack</name> <age>21</age> <country>USA</country> </teacher> </classroom>
针对上面的文档进行示例演示:
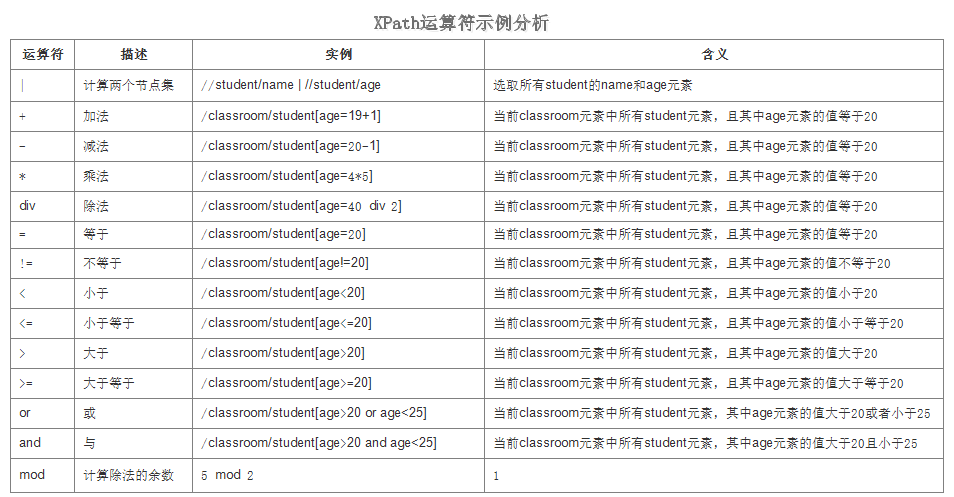
4.XPath运算符
XPath表达式可返回节点集、字符串、逻辑值以及数字。