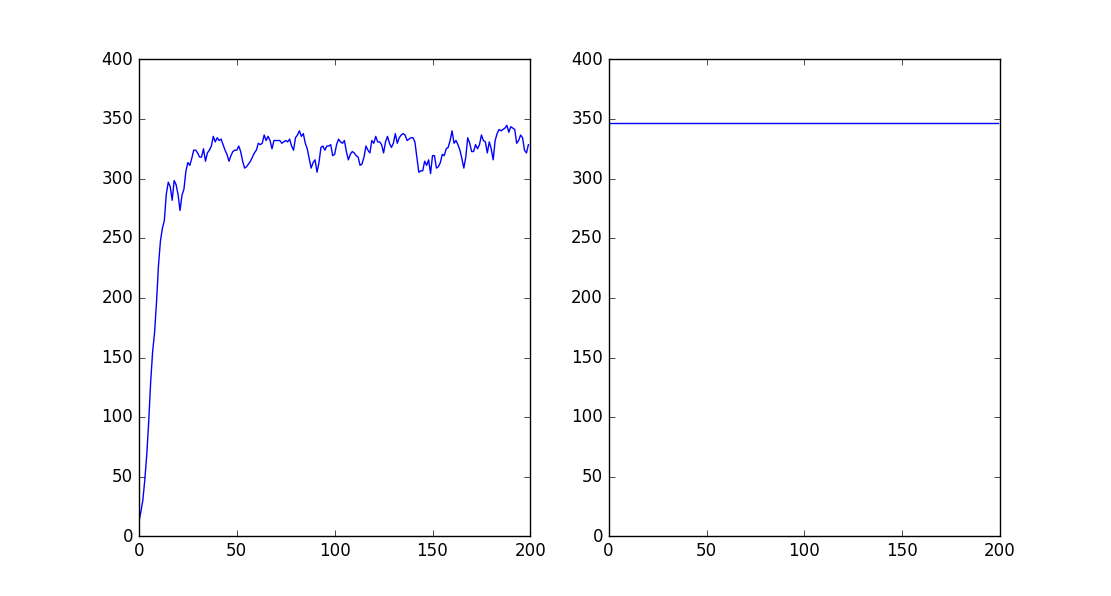
1 # 调试注意事项,当出现小数值时,可能时int位数设置不当,导致溢出 2 import numpy 3 import matplotlib.pyplot as plt 4 5 6 data = numpy.array([[71, 34, 82, 23, 1, 88, 12, 57, 10, 68, 5, 33, 37, 69, 98, 24, 26, 83, 16, 26], 7 [26, 59, 30, 19, 66, 85, 94, 8, 3, 44, 5, 1, 41, 82, 76, 1, 12, 81, 73, 32]]) 8 9 data = data.T 10 11 12 class GA(object): 13 """ 14 遗传算法解决0-1背包问题 15 """ 16 17 def __init__(self, length, number, iter_number): 18 """ 19 参数初始化 20 :param length: 20 21 :param number: 300 22 :param iter_number: 200 23 """ 24 self.length = length # 确定染色体编码长度 25 self.number = number # 确定初始化种群数量 26 self.iteration = iter_number # 设置迭代次数 27 self.bag_capacity = 200 # 背包容量 28 29 self.retain_rate = 0.2 # 每一代精英选择出前20% 30 self.random_selection_rate = 0.5 # 对于不是前20%的,有0.5的概率可以进行繁殖 31 self.mutation_rate = 0.01 # 变异概率0.01 32 33 def initial_population(self): 34 """ 35 种群初始化, 36 37 :return: 返回种群集合 38 """ 39 init_population = numpy.random.randint(low=0, high=2, size=[self.length, self.number], dtype=numpy.int64) 40 return init_population 41 42 def weight_price(self, chromosome): 43 """ 44 计算累计重量和累计价格 45 :param chromosome: 46 :return:返回每一个个体的累计重量和价格 47 """ 48 w_accumulation = 0 49 p_accumulation = 0 50 for i in range(len(chromosome)): 51 52 w = chromosome[i]*data[i][0] 53 p = chromosome[i]*data[i][1] 54 w_accumulation = w + w_accumulation 55 p_accumulation = p + p_accumulation 56 57 return w_accumulation, p_accumulation 58 59 def fitness_function(self, chromosome): 60 """ 61 计算适应度函数,一般来说,背包的价值越高越好,但是 62 当重量超过100时,适应度函数=0 63 :param chromosome: 64 :return: 65 """ 66 67 weight, price = self.weight_price(chromosome) 68 if weight > self.bag_capacity: 69 fitness = 0 70 else: 71 fitness = price 72 73 return fitness 74 75 def fitness_average(self, init_population): 76 """ 77 求出这个种群的平均适应度,才能知道种群已经进化好了 78 :return:返回的是一个种群的平均适应度 79 """ 80 f_accumulation = 0 81 for z in range(init_population.shape[1]): 82 f_tem = self.fitness_function(init_population[:, z]) 83 f_accumulation = f_accumulation + f_tem 84 f_accumulation = f_accumulation/init_population.shape[1] 85 return f_accumulation 86 87 def selection(self, init_population): 88 """ 89 选择 90 :param init_population: 91 :return: 返回选择后的父代,数量是不定的 92 """ 93 # sort_population = numpy.array([[], [], [], [], [], []]) 94 sort_population = numpy.empty(shape=[21, 0]) # 生成一个排序后的种群列表,暂时为空 95 for i in range(init_population.shape[1]): 96 97 x1 = init_population[:, i] 98 # print('打印x1', x1) 99 x2 = self.fitness_function(x1) 100 x = numpy.r_[x1, x2] 101 # print('打印x', x) 102 sort_population = numpy.c_[sort_population, x] 103 104 sort_population = sort_population.T[numpy.lexsort(sort_population)].T # 联合排序,从小到大排列 105 106 # print('排序后长度', sort_population.shape[1]) 107 # print(sort_population) 108 109 # 选出适应性强的个体,精英选择 110 retain_length = sort_population.shape[1]*self.retain_rate 111 112 # parents = numpy.array([[], [], [], [], [], []]) # 生成一个父代列表,暂时为空 113 parents = numpy.empty(shape=[21, 0]) # 生成一个父代列表,暂时为空 114 for j in range(int(retain_length)): 115 y1 = sort_population[:, -(j+1)] 116 parents = numpy.c_[parents, y1] 117 118 # print(parents.shape[1]) 119 120 rest = sort_population.shape[1] - retain_length # 精英选择后剩下的个体数 121 for q in range(int(rest)): 122 123 if numpy.random.random() < self.random_selection_rate: 124 y2 = sort_population[:, q] 125 parents = numpy.c_[parents, y2] 126 127 parents = numpy.delete(parents, -1, axis=0) # 删除最后一行,删除了f值 128 # print('打印选择后的个体数') 129 # print(parents.shape[0]) 130 131 parents = numpy.array(parents, dtype=numpy.int64) 132 133 return parents 134 135 def crossover(self, parents): 136 """ 137 交叉生成子代,和初始化的种群数量一致 138 :param parents: 139 :return:返回子代 140 """ 141 # children = numpy.array([[], [], [], [], []]) # 子列表初始化 142 children = numpy.empty(shape=[20, 0]) # 子列表初始化 143 144 while children.shape[1] < self.number: 145 father = numpy.random.randint(0, parents.shape[1] - 1) 146 mother = numpy.random.randint(0, parents.shape[1] - 1) 147 if father != mother: 148 # 随机选取交叉点 149 cross_point = numpy.random.randint(0, self.length) 150 # 生成掩码,方便位操作 151 mark = 0 152 for i in range(cross_point): 153 mark |= (1 << i) 154 155 father = parents[:, father] 156 # print(father) 157 mother = parents[:, mother] 158 159 # 子代将获得父亲在交叉点前的基因和母亲在交叉点后(包括交叉点)的基因 160 child = ((father & mark) | (mother & ~mark)) & ((1 << self.length) - 1) 161 162 children = numpy.c_[children, child] 163 164 # 经过繁殖后,子代的数量与原始种群数量相等,在这里可以更新种群。 165 # print('子代数量', children.shape[1]) 166 # print(children.dtype) 167 children = numpy.array(children, dtype=numpy.int64) 168 return children 169 170 def mutation(self, children): 171 """ 172 变异 173 174 :return: 175 """ 176 for i in range(children.shape[1]): 177 178 if numpy.random.random() < self.mutation_rate: 179 j = numpy.random.randint(0, self.length - 1) # s随机产生变异位置 180 children[:, i] ^= 1 << j # 产生变异 181 children = numpy.array(children, dtype=numpy.int64) 182 return children 183 184 def plot_figure(self, iter_plot, f_plot, f_set_plot): 185 """ 186 画出迭代次数和平均适应度曲线图 187 画出迭代次数和每一步迭代最大值图 188 :return: 189 """ 190 plt.figure() 191 192 ax1 = plt.subplot(121) 193 ax2 = plt.subplot(122) 194 195 plt.sca(ax1) 196 plt.plot(iter_plot, f_plot) 197 plt.ylim(0, 400) # 设置y轴范围 198 199 plt.sca(ax2) 200 plt.plot(iter_plot, f_set_plot) 201 plt.ylim(0, 400) # 设置y轴范围 202 plt.show() 203 204 def main(self): 205 """ 206 main函数,用来进化 207 对当前种群依次进行选择、交叉并生成新一代种群,然后对新一代种群进行变异 208 :return: 209 """ 210 init_population = self.initial_population() 211 # print(init_population) 212 213 iter_plot = [] 214 f_plot = [] 215 iteration = 0 216 217 f_set_plot = [] 218 219 while iteration < self.iteration: # 设置迭代次数300 220 221 parents = self.selection(init_population) # 选择后的父代 222 children = self.crossover(parents) 223 mutation_children = self.mutation(children) 224 225 init_population = mutation_children 226 227 f_set = [] # 求出每一步迭代的最大值 228 for init in range(init_population.shape[1]): 229 f_set_tem = self.fitness_function(init_population[:, init]) 230 f_set.append(f_set_tem) 231 232 f_set = max(f_set) 233 234 f_set_plot.append(f_set) 235 236 iter_plot.append(iteration) 237 iteration = iteration+1 238 print("第%s进化得如何******************************************" % iteration) 239 f_average = self.fitness_average(init_population) 240 f_plot.append(f_average) 241 print(f_set) 242 # f_accumulation = f_accumulation + f 243 # f_print = f_accumulation/(iteration + 1) 244 # print(f_print) 245 self.plot_figure(iter_plot, f_plot, f_set_plot) 246 247 248 if __name__ == '__main__': 249 g1 = GA(20, 300, 200) 250 g1.main()