文件操作:
工作中避免不了要和文件打文件,Python提供了标准输入和输出进行读写,
f = codecs然后按Alt + Enter快捷键然后直接回车,直接导入模块


a)读取文件内容:
打开文件需要以下几步:
1.open文件
2.文件操作(如读或者写)
3.关闭文件
当前目录下有一个text.txt文件,文件内容如下:
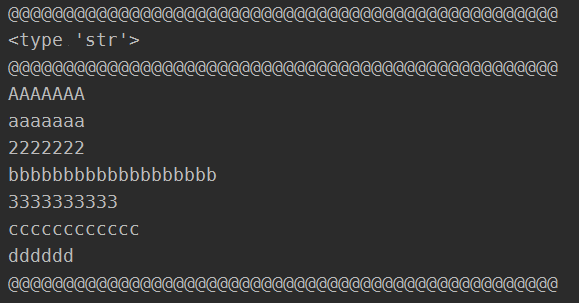
1111111
aaaaaaa
2222222
bbbbbbbbbbbbbbbbbbb
3333333333
cccccccccccc
dddddd
直接打印内容文件:
f = codecs.open('1.txt')
print('@'*50)
print(f.read())
f.close()
打印结果为:

f = codecs.open('1.txt')
print('@'*50)
# print(f.read())
# print('@'*50)
text = f.read()
# print('@'*50)
print(type(text)) #字符串类型
print('@'*50)
result = text.replace('1','A') #把全部1换成大写的A
print(result)
print('@'*50)
# print(f.read())
# # print(dir(f))
f.close()
打印结果为:
codecs类:这个模块主要是用来解决文件乱码的问题
import codecs
#open是打开这个文件的,ctrl+左键单击查看open中的w是干嘛用的,第一个是文件名字,mode有几个参数需要学习,默认就是rb,r是读,w是写,b是二进制读取,a是追加(读或写)
f = codecs.open('2.txt','wb')
f.write('Hello World!
')
f.write('Hello YJB!
')
f.write('You are very very coll
')
f.write('we love this thearch
')
f.write('###########****************
')
f.close()
运行后会自动创建一个2.txt的文件,2.txt文件内容为:
Hello World!
Hello YJB!
You are very very coll
we love this thearch
###########****************
改为:
f = codecs.open('2.txt','ab')
会在2.txt文件追加文件后面又写一遍
Hello World!
Hello YJB!
You are very very coll
we love this thearch
###########****************
Hello World!
Hello YJB!
You are very very coll
we love this thearch
###########****************
f.write('You are very very coll
')也可以用字符串的形式:
f.write(('You {0}
').format('YJB'))
f = open('2.txt','rb')
print(dir(f))
f.close()
flush:flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。
readlines:readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for... in ... 结构进行处理。
如果碰到结束符 EOF 则返回空字符串。
语法
readlines(self, size=None)
readlines([size]) -> list of strings, each a line from the file.
return []
参数
无
返回值
返回列表,包含所有的行。
f = open('2.txt','rb')
# print(dir(f))
print(f.readlines())
f.close()
打印结果为:

f = open('2.txt','rb')
print(f.readlines())
print(f.readlines()[0])
f.close()
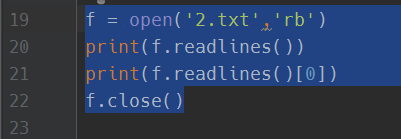
则直接报错:

修改为:
f = open('2.txt','rb')
text_list = f.readlines()
print(type(text_list))
print(f.readlines())
print(text_list[0])
f.close()
打印结果为:
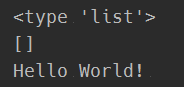
f已经执行完readlines后,下次再去读的时候,会从末尾开始读,所以读出来会是[]空字符串(空字典),所以打印print(f.readlines())这一行给注释掉,打印结果为:
或者把光标位置重新定位到文件首行(Python支持光标调到第一行),
readline:readline() 方法用于从文件读取整行,包括 "
" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "
" 字符。
语法
readline(self, size=None)
pass
参数
size -- 从文件中读取的字节数。
返回值
返回从字符串中读取的字节。
f = codecs.open('2.txt','rb')
print(f.readline())
f.close()
打印结果为:
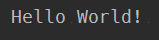
如果再加上print(f.readline())则打印第二行,打印完第一行后光标变到第二行上,
readlines是把所有每一行搞成一个元素,每个元素是一个字符串,
readline 是把每一行做成一个字符串,
next:next() 方法在文件使用迭代器时会使用到,在循环中,next()方法会在每次循环中调用,该方法返回文件的下一行,如果到达结尾(EOF),则触发 StopIteration
语法
next() 方法语法如下:
fileObject.next();
参数
无
返回值
返回文件下一行。
write:write() 方法用于向文件中写入指定字符串。在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这时你在文件中是看不到写入的内容的。跟read()相对应的
语法
write(self, p_str)
pass
参数
str -- 要写入文件的字符串。
返回值
该方法没有返回值。
f = open('file3.txt','wb')
f.write('HELLO WORLD
eighieg82483
eighw8u323u
')
f.close()
writelines:writelines() 方法用于向文件中写入一序列的字符串。这一序列字符串可以是由迭代对象产生的,如一个字符串列表。换行需要制定换行符
。
语法
writelines(self, sequence_of_strings)
pass
参数
str -- 要写入文件的字符串序列。
返回值
该方法没有返回值。
f.writelines(['aaa','bbb','cccccccccccccccc','dddd'])
tell:tell() 方法返回文件的当前位置,即文件指针当前位置。
tell() -> current file position, an integer (may be a long integer).
pass
语法
fileObject.tell(offset[, whence])
参数
无
返回值
返回文件的当前位置。
f = codecs.open('file3.txt','wb')
print(dir(f))
f.write('hello world!
YJB')
print(f.tell())
f.writelines(['a
','b
','c
'])
f.close()
seek:seek() 方法用于移动文件读取指针到指定位置。
语法
seek(self, offset, whence=None)
fileObject.seek(offset[, whence])
参数
offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
返回值
该函数没有返回值。
打印文件名:
print(f.name)
关闭文件就返回True,没关闭文件则返回False
print(f.closed)
print(f.mode)