caffe模型转pytorch---LSTM
本文官方链接https://www.cnblogs.com/yanghailin/p/15599428.html,未经授权勿转载
先来个总结:
具体的可以看博客:
https://www.cnblogs.com/yanghailin/p/15599428.html
caffe提取权重搭建pytorch网络,实现lstm转换。
pytorch1.0,cuda8.0,libtorch1.0
pytorch1.0上面是可以的,精度一致,但是转libtorch的时候也没有问题,没有任何提示,转pt是没有问题的。
但是就是最后精度不对,找到问题就是lstm那层精度不对。上面一层精度还是对的。无解。
然后又试验了pytorch1.1.0环境,没问题。
github提的issue:
https://github.com/pytorch/pytorch/issues/68864
之前完成了几个网络的caffe转pytorch。
refinenet https://www.cnblogs.com/yanghailin/p/13096258.html
refinedet https://www.cnblogs.com/yanghailin/p/12965695.html
上面那个是提取caffe权重然后转libtorch,下面是直接对应的pytorch版本转libtorch,大量的后处理用libtorch完成,后来同事也完成了直接拿caffe权重转libtorch。
无出意外,上面的都是需要编译caffe的python接口完成。但是一般的工程场景是我们只用caffe的c++,有时候没有对应的python工程。然后编译python接口并调用会有一些麻烦。
后来我想为啥我们要多此一举,直接用caffe跑前向的c++工程难道不行吗?
其实是可以的,只是caffe的源码复杂,一开始看不懂。
本系列的博客就是直接用caffe的c++工程直接提取权重,搭建同样的pytorch网络,把caffe权重填充过来就可以直接运行跑前向推理。
我是这么处理的,首先编译caffe lstm的cpu版本,可以在clion里面debug,我是在/caffe_ocr/tools/caffe.cpp 把caffe.cpp原有的都删了,然后换上了lstm 跑前向推理的代码,这样编译出来的caffe源码。
然后我就可以打断点调试了。
caffe源码是一个高度抽象的工程,通过Layer作为基类,其他所有算法模块都是在这个Layer上派生出来的。
net类是一个很重要的类,它管理与统筹了整个网络,在net类中可以拿到网络所有中间feature map结果,可以拿到每个层对应的权重。
由于我的目的是需要转lstm到pytorch。所有把lstm这个算子实现方法整明白至关重要。一看不知道,再看直接傻眼。lstm实现真是复杂啊!它内部自己整了一个net类!!!双向lstm就是整了2个net类,派生于RecurrentLayer这个类。
lstm原理的话就是那6个公式,看这个博客就可以:
https://www.jianshu.com/p/9dc9f41f0b29
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
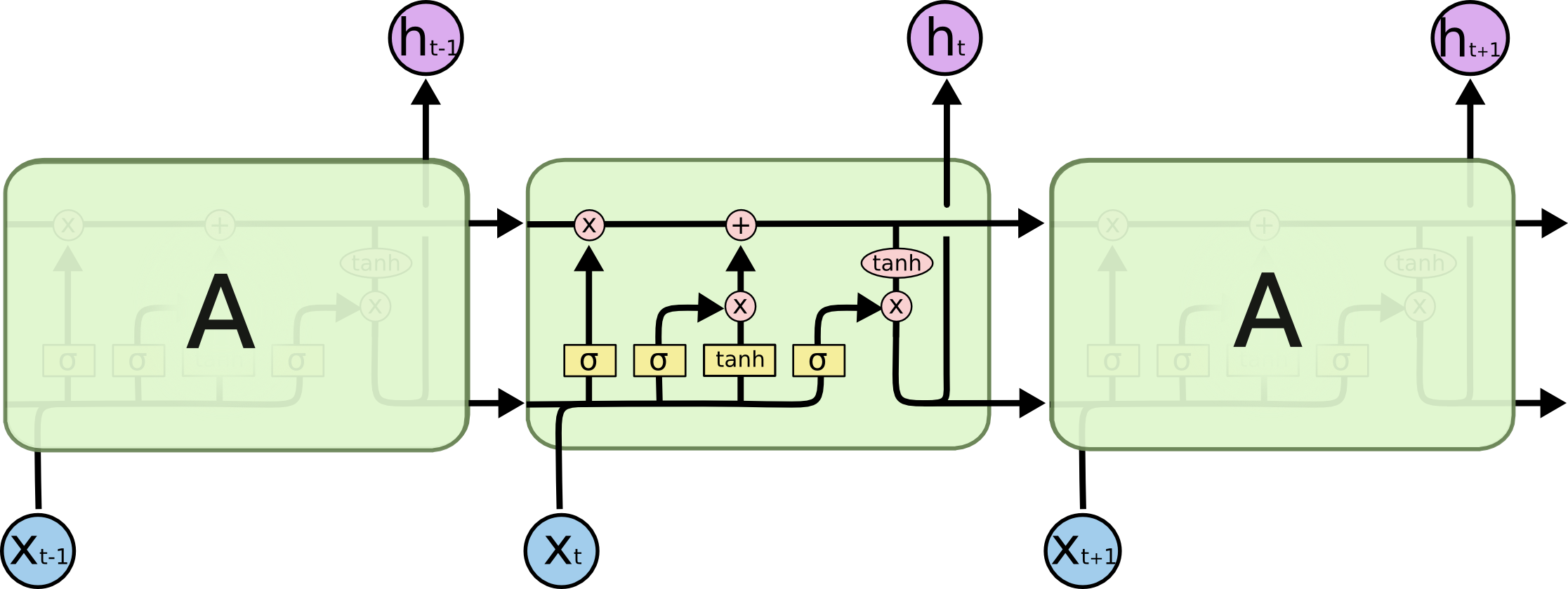

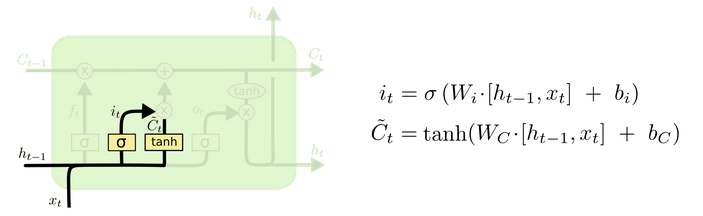

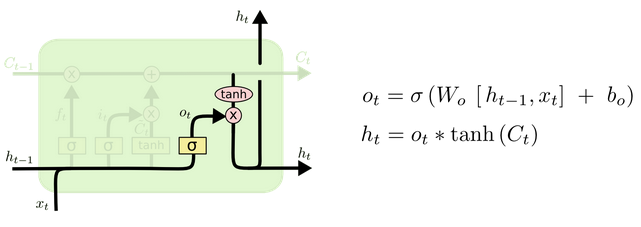
本文并不打算仔细讲解caffe源码与lstm具体实现方式。后面有机会单独开一个博客吧。
本文具体讲解从caffemodel提取各个层的权重。权重是一般是很大的一个矩阵,比如[64,3,7,7], 需要把这些权重保存起来供Python读取。
一开始我也在c++想有啥办法和Python numpy一样的方便处理矩阵,想过了用json,xml或者直接用caffe自带的blob类,但是不会用啊!用caffe的proto应该是可以的,但是不会用。
然后就用最直接的方法吧,就是把权重直接一行一个保存在本地txt中,文件命名就直接是该层的层名,比如该层层名是conv1,那么就是conv1_weight_0.txt,conv1_weight_1.txt。第一行放形状,比如64,3,7,7。
由于权重也是以blob形式存在的,所以我在blob源码里面加上了保存该blob数据到本地txt的函数,只需要提供保存的地址就可以。如下:
void save_data_to_txt(const string path_txt,bool b_save_shape = true)
{
std::ofstream fOut(path_txt);
if (!fOut)
{
std::cout << "Open output file faild." << std::endl;
}
if(b_save_shape)
{
for(int i=0;i<shape_.size();i++)
{
fOut << shape_[i];
if(i == shape_.size()-1)
{
fOut<<std::endl;
}else
{
fOut<<",";
}
}
}
const Dtype* data_vec = cpu_data();
for (int i = 0; i < count_; ++i) {
fOut << data_vec[i] << std::endl;
}
fOut.close();
}
下面直接上我的代码,保存每层权重到txt的代码如下:
std::cout<<"\n\n\n\n============2021-11-18======================================="<<std::endl;
shared_ptr<Net<float> > net_ = classifier.get_net(); //这里是从跑前向的类里面拿Net类
vector<shared_ptr<Layer<float> > > layers = net_->layers(); //拿到每层Layer算子的指针
vector<shared_ptr<Blob<float> > > params = net_->params();//拿到所有权重指针
vector<vector<Blob<float>*> > bottom_vecs_ = net_->bottom_vecs();//拿到所有bottom feature map
vector<vector<Blob<float>*> > top_vecs_ = net_->top_vecs();//拿到所有top feature map //注意这里面的layers和bottom_vecs_ top_vecs_都是一一对应的
std::cout<<"size layer=" << layers.size()<<std::endl;
std::cout<<"size params=" << params.size()<<std::endl;
string path_save_dir = "/data_1/Yang/project/save_weight/";
for(int i=0;i<layers.size();i++)
{
shared_ptr<Layer<float> > layer = layers[i];
string name_layer = layer->layer_param().name();//当前层层名
std::cout<<i<<" layer_name="<<name_layer<<" type="<<layer->layer_param().type()<<std::endl;
int bottom_name_size = layer->layer_param().bottom().size();
std::cout<<"=================bottom================"<<std::endl;
if(bottom_name_size>0)
{
for(int ii=0;ii<bottom_name_size;ii++)
{
std::cout<<ii<<" ::bottom name="<<layer->layer_param().bottom(ii)<<std::endl;
Blob<float>* ptr_blob = bottom_vecs_[i][ii];
std::cout<<"bottom shape="<<ptr_blob->shape_string()<<std::endl;
}
} else{
std::cout<<"no bottom"<<std::endl;
}
std::cout<<"=================top================"<<std::endl;
int top_name_size = layer->layer_param().top().size();
if(top_name_size>0)
{
for(int ii=0;ii<top_name_size;ii++)
{
std::cout<<ii<<" ::top name="<<layer->layer_param().top(ii)<<std::endl;
Blob<float>* ptr_blob = top_vecs_[i][ii];
std::cout<<"top shape="<<ptr_blob->shape_string()<<std::endl;
}
} else{
std::cout<<"no top"<<std::endl;
}
vector<shared_ptr<Blob<float> > > params = layer->blobs();
std::cout<<"=================params ================"<<std::endl;
std::cout<<"params size= "<<params.size()<<std::endl;
if(0 == params.size())
{
std::cout<<"has no params"<<std::endl;
} else
{
for(int j=0;j<params.size();j++)
{
std::cout<<"params_"<<j<<" shape="<<params[j]->shape_string()<<std::endl;
params[j]->save_data_to_txt(path_save_dir + name_layer + "_weight_" + std::to_string(j)+".txt");
}
}
std::cout<<std::endl;
}
//这里是为了对比caffe和pytorch的某一层输出是否一致,先保存caffe的某层feature map输出。
string name_aim_top = "premuted_fc";
const shared_ptr<Blob<float>> feature_map = net_->blob_by_name(name_aim_top);
bool b_save_shape = false;
std::cout<<"featuremap shape="<<std::endl;
std::cout<<feature_map->shape_string()<<std::endl;
feature_map->save_data_to_txt("/data_1/Yang/project/myfile/blob_val/"+name_aim_top+".txt",b_save_shape);
看caffe网络的话,可以直接把prototxt文件复制到网页上面查看。
http://ethereon.github.io/netscope/quickstart.html
这样看比较直观。
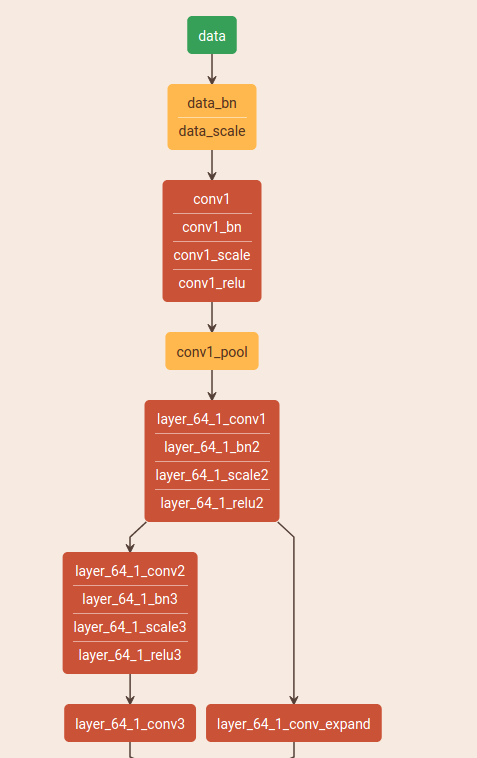
这里需要特别注意的是一个,就地操作。就是比如图上网络连在一起的conv1,conv1_bn,conv1_scale,conv1_relu由于它们的bottom和top名字一样,导致经过该层的运算结果直接会覆盖bottom,就是共用了一块内存。
这里是一个坑,之前一个同事也在做类似的工作,然后不同框架之间对比检查精度,发现刚开始的几层精度就对不上了,苦苦找问题找了一周都没有找到,最后让我帮忙看了看,我看了大半天才发现是这个就地操作导致的,你想拿conv1的feature map的结果是拿不到,你拿的实际已经是经过了conv1,conv1_bn,conv1_scale,conv1_relu这4步操作之后的结果了!
以上,就会生成每层权重,如果该层有多个权重,就直接是文件名末尾计数0,1,2来区分的,命名方式是layerName+_weight_cnt.txt。文件txt第一行是权重的shape,比如64,64,1,1。
完事之后,在Python端,我先写了一个脚本,读取txt把这些权重保存在一个字典里面。
import os
import numpy as np
#这个类主要是为了能够多重字典赋值
class AutoVivification(dict):
"""Implementation of perl's autovivification feature."""
def __getitem__(self, item):
try:
return dict.__getitem__(self, item)
except KeyError:
value = self[item] = type(self)()
return value
def get_weight_numpy(path_dir):
out = AutoVivification()
list_txt = os.listdir(path_dir)
for cnt,txt in enumerate(list_txt):
print(cnt, " ", txt)
txt_ = txt.replace(".txt","")
layer_name, idx = txt_.split("_weight_")
path_txt = path_dir + txt
with open(path_txt, 'r') as fr:
lines = fr.readlines()
data = []
shape_line = []
for cnt_1, line in enumerate(lines):
if(0 == cnt_1):
shape_line = []
shape_line = line.strip().split(",")
else:
data.append(float(line))
shape_line = map(eval, shape_line)
data = np.array(data).reshape(shape_line)
# new_dict = {}
out[layer_name][int(idx)] = data
return out
if __name__ == "__main__":
path_dir = "/data_1/Yang/project/save_weight/"
out = get_weight_numpy(path_dir)
conv1_weight = out['conv1'][0]
conv1_bias = out['conv1'][1]
下面直接给出把caffe保存的权重怼到搭建的pytorch 层上:
# coding=utf-8
import torch
import torchvision
from torch import nn
import torch.nn.functional as F
import cv2
import numpy as np
from weight_numpy import get_weight_numpy
class lstm_general(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
super(lstm_general, self).__init__()
# self.conv1_1 = nn.Conv2d(3, 64, 3, 1, 1)
self.data_bn = nn.BatchNorm2d(3)
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3)
self.conv1_bn = nn.BatchNorm2d(64)
self.conv1_pool = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.layer_64_1_conv1 = nn.Conv2d(64, 64, 1, 1, 0, bias = False)
self.layer_64_1_bn2 = nn.BatchNorm2d(64)
self.layer_64_1_conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer_64_1_bn3 = nn.BatchNorm2d(64)
self.layer_64_1_conv3 = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_64_1_conv_expand = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_128_1_bn1 = nn.BatchNorm2d(256)
self.layer_128_1_conv1 = nn.Conv2d(256, 128, 1, 1, 0, bias=False)
self.layer_128_1_bn2 = nn.BatchNorm2d(128)
self.layer_128_1_conv2 = nn.Conv2d(128, 128, 3, 1, 1, bias=False)
self.layer_128_1_bn3 = nn.BatchNorm2d(128)
self.layer_128_1_conv3 = nn.Conv2d(128, 512, 1, 1, 0, bias=False)
self.layer_128_1_conv_expand = nn.Conv2d(256, 512, 1, 1, 0, bias=False)
self.last_bn = nn.BatchNorm2d(512)
# self.lstm_1 = nn.LSTM(512 * 8, 100, 1, bidirectional=False)
self.lstm_lr = nn.LSTM(512 * 8, 100, 1, bidirectional=True)
self.fc1x1_r2_v2_a = nn.Linear(200,7118)
def forward(self, inputs):
# x = F.relu(self.bn1_1(self.conv1_1(inputs)))
x = self.data_bn(inputs)
x = F.relu(self.conv1_bn(self.conv1(x)))
x = self.conv1_pool(x) #[1,64,8,80]
x = F.relu(self.layer_64_1_bn2(self.layer_64_1_conv1(x))) # 1 64 8 80
layer_64_1_conv1 = x
x = F.relu(self.layer_64_1_bn3(self.layer_64_1_conv2(x)))
x = self.layer_64_1_conv3(x)
layer_64_1_conv_expand = self.layer_64_1_conv_expand(layer_64_1_conv1)
layer_64_3_sum = x + layer_64_1_conv_expand #1 256 8 80
x = F.relu(self.layer_128_1_bn1(layer_64_3_sum))
layer_128_1_bn1 = x
x = F.relu(self.layer_128_1_bn2(self.layer_128_1_conv1(x)))
x = F.relu(self.layer_128_1_bn3(self.layer_128_1_conv2(x)))
x = self.layer_128_1_conv3(x) #1, 512, 8, 80
layer_128_1_conv_expand = self.layer_128_1_conv_expand(layer_128_1_bn1) #1, 512, 8, 80
layer_128_4_sum = x + layer_128_1_conv_expand
x = F.relu(self.last_bn(layer_128_4_sum))
x = F.dropout(x, p=0.7, training=False) #1 512 8 80
x = x.permute(3,0,1,2) # 80 1 512 8
x = x.reshape(80,1,512*8)
#
# merge_lstm_rlstmx, (hn, cn) = self.lstm_r(x)
lstm_out,(_,_) = self.lstm_lr(x) #(80,1,200)
out = self.fc1x1_r2_v2_a(lstm_out) #(80,1,7118)
return out
def save_tensor(tensor_in,path_save):
tensor_in = tensor_in.contiguous().view(-1,1)
np_tensor = tensor_in.cpu().detach().numpy()
# np_tensor = np_tensor.view()
np.savetxt(path_save,np_tensor,fmt='%.12e')
def access_pixels(frame):
print(frame.shape) # shape内包含三个元素:按顺序为高、宽、通道数
height = frame.shape[0]
weight = frame.shape[1]
channels = frame.shape[2]
print("weight : %s, height : %s, channel : %s" % (weight, height, channels))
with open("/data_1/Yang/project/myfile/blob_val/img_stand_python.txt", "w") as fw:
for row in range(height): # 遍历高
for col in range(weight): # 遍历宽
for c in range(channels): # 便利通道
pv = frame[row, col, c]
fw.write(str(int(pv)))
fw.write("\n")
def LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32):
img_h, img_w, _ = img.shape
if img_h < 2 or img_w < 2:
return
# if 32 == img_h and 320 == img_w:
# return img
ratio_now = img_w * 1.0 / img_h
if ratio_now <= ratio:
mask = np.ones((img_h, int(img_h * ratio), 3), dtype=np.uint8) * 255
mask[0:img_h,0:img_w,:] = img
else:
mask = np.ones((int(img_w*1.0/ratio), img_w, 3), dtype=np.uint8) * 255
mask[0:img_h, 0:img_w, :] = img
mask_stand = cv2.resize(mask,(stand_w, stand_h),interpolation=cv2.INTER_LINEAR)
# access_pixels(mask_stand)
return mask_stand
if __name__ == '__main__':
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
net = lstm_general()
# net.eval()
index = 0
print("*" * 50)
for name, param in list(net.named_parameters()):
print(str(index) + ':', name, param.size())
index += 1
print("*" * 50)
##搭建完网络就可以通过这里看到网络所需要的参数名字
for k, v in net.state_dict().items():
print(k)
print(v.shape)
# print(k,v)
print("@" * 50)
# aaa = np.zeros((400,1))
path_dir = "/data_1/Yang/project/OCR/3rdlib/caffe_ocr_2021/myfile/save_weight/"
weight_numpy_dict = get_weight_numpy(path_dir)
from torch import from_numpy
state_dict = {}
state_dict['data_bn.running_mean'] = from_numpy(weight_numpy_dict["data_bn"][0] / weight_numpy_dict["data_bn"][2])
state_dict['data_bn.running_var'] = from_numpy(weight_numpy_dict["data_bn"][1] / weight_numpy_dict["data_bn"][2])
state_dict['data_bn.weight'] = from_numpy(weight_numpy_dict['data_scale'][0])
state_dict['data_bn.bias'] = from_numpy(weight_numpy_dict['data_scale'][1])
state_dict['conv1.weight'] = from_numpy(weight_numpy_dict['conv1'][0])
state_dict['conv1.bias'] = from_numpy(weight_numpy_dict['conv1'][1])
state_dict['conv1_bn.running_mean'] = from_numpy(weight_numpy_dict["conv1_bn"][0] / weight_numpy_dict["conv1_bn"][2])
state_dict['conv1_bn.running_var'] = from_numpy(weight_numpy_dict["conv1_bn"][1] / weight_numpy_dict["conv1_bn"][2])
state_dict['conv1_bn.weight'] = from_numpy(weight_numpy_dict['conv1_scale'][0])
state_dict['conv1_bn.bias'] = from_numpy(weight_numpy_dict['conv1_scale'][1])
state_dict['layer_64_1_conv1.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv1'][0])
state_dict['layer_64_1_bn2.running_mean'] = from_numpy(weight_numpy_dict["layer_64_1_bn2"][0] / weight_numpy_dict["layer_64_1_bn2"][2])
state_dict['layer_64_1_bn2.running_var'] = from_numpy(weight_numpy_dict["layer_64_1_bn2"][1] / weight_numpy_dict["layer_64_1_bn2"][2])
state_dict['layer_64_1_bn2.weight'] = from_numpy(weight_numpy_dict['layer_64_1_scale2'][0])
state_dict['layer_64_1_bn2.bias'] = from_numpy(weight_numpy_dict['layer_64_1_scale2'][1])
state_dict['layer_64_1_conv2.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv2'][0])
state_dict['layer_64_1_bn3.running_mean'] = from_numpy(weight_numpy_dict["layer_64_1_bn3"][0] / weight_numpy_dict["layer_64_1_bn3"][2])
state_dict['layer_64_1_bn3.running_var'] = from_numpy(weight_numpy_dict["layer_64_1_bn3"][1] / weight_numpy_dict["layer_64_1_bn3"][2])
state_dict['layer_64_1_bn3.weight'] = from_numpy(weight_numpy_dict['layer_64_1_scale3'][0])
state_dict['layer_64_1_bn3.bias'] = from_numpy(weight_numpy_dict['layer_64_1_scale3'][1])
state_dict['layer_64_1_conv3.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv3'][0])
state_dict['layer_64_1_conv_expand.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv_expand'][0])
state_dict['layer_128_1_bn1.running_mean'] = from_numpy(weight_numpy_dict["layer_128_1_bn1"][0] / weight_numpy_dict["layer_128_1_bn1"][2])
state_dict['layer_128_1_bn1.running_var'] = from_numpy(weight_numpy_dict["layer_128_1_bn1"][1] / weight_numpy_dict["layer_128_1_bn1"][2])
state_dict['layer_128_1_bn1.weight'] = from_numpy(weight_numpy_dict['layer_128_1_scale1'][0])
state_dict['layer_128_1_bn1.bias'] = from_numpy(weight_numpy_dict['layer_128_1_scale1'][1])
state_dict['layer_128_1_conv1.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv1'][0])
state_dict['layer_128_1_bn2.running_mean'] = from_numpy(weight_numpy_dict["layer_128_1_bn2"][0] / weight_numpy_dict["layer_128_1_bn2"][2])
state_dict['layer_128_1_bn2.running_var'] = from_numpy(weight_numpy_dict["layer_128_1_bn2"][1] / weight_numpy_dict["layer_128_1_bn2"][2])
state_dict['layer_128_1_bn2.weight'] = from_numpy(weight_numpy_dict['layer_128_1_scale2'][0])
state_dict['layer_128_1_bn2.bias'] = from_numpy(weight_numpy_dict['layer_128_1_scale2'][1])
state_dict['layer_128_1_conv2.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv2'][0])
state_dict['layer_128_1_bn3.running_mean'] = from_numpy(weight_numpy_dict["layer_128_1_bn3"][0] / weight_numpy_dict["layer_128_1_bn3"][2])
state_dict['layer_128_1_bn3.running_var'] = from_numpy(weight_numpy_dict["layer_128_1_bn3"][1] / weight_numpy_dict["layer_128_1_bn3"][2])
state_dict['layer_128_1_bn3.weight'] = from_numpy(weight_numpy_dict['layer_128_1_scale3'][0])
state_dict['layer_128_1_bn3.bias'] = from_numpy(weight_numpy_dict['layer_128_1_scale3'][1])
state_dict['layer_128_1_conv3.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv3'][0])
state_dict['layer_128_1_conv_expand.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv_expand'][0])
state_dict['last_bn.running_mean'] = from_numpy(weight_numpy_dict["last_bn"][0] / weight_numpy_dict["last_bn"][2])
state_dict['last_bn.running_var'] = from_numpy(weight_numpy_dict["last_bn"][1] / weight_numpy_dict["last_bn"][2])
state_dict['last_bn.weight'] = from_numpy(weight_numpy_dict['last_scale'][0])
state_dict['last_bn.bias'] = from_numpy(weight_numpy_dict['last_scale'][1])
## caffe i f o g
## pytorch i f g o
ww = from_numpy(weight_numpy_dict['lstm1x_r2'][0]) # [400,4096]
ww_200_if = ww[:200,:] #[200,4096]
ww_100_o = ww[200:300,:] #[100,4096]
ww_100_g = ww[300:400,:]#[100,4096]
ww_cat_ifgo = torch.cat((ww_200_if,ww_100_g,ww_100_o),0)
state_dict['lstm_lr.weight_ih_l0'] = ww_cat_ifgo
bb = from_numpy(weight_numpy_dict['lstm1x_r2'][1]) # [400]
bb_200_if = bb[:200]
bb_100_o = bb[200:300]
bb_100_g = bb[300:400]
bb_cat_ifgo = torch.cat((bb_200_if, bb_100_g, bb_100_o), 0)
state_dict['lstm_lr.bias_ih_l0'] = bb_cat_ifgo
ww = from_numpy(weight_numpy_dict['lstm1x_r2'][2]) # [400,100]
ww_200_if = ww[:200, :] # [200,100]
ww_100_o = ww[200:300, :] # [100,100]
ww_100_g = ww[300:400, :] # [100,100]
ww_cat_ifgo = torch.cat((ww_200_if, ww_100_g, ww_100_o), 0)
state_dict['lstm_lr.weight_hh_l0'] = ww_cat_ifgo
state_dict['lstm_lr.bias_hh_l0'] = from_numpy(np.zeros((400)))
##########################################
ww = from_numpy(weight_numpy_dict['lstm2x_r2'][0]) # [400,4096]
ww_200_if = ww[:200, :] # [200,4096]
ww_100_o = ww[200:300, :] # [100,4096]
ww_100_g = ww[300:400, :] # [100,4096]
ww_cat_ifgo = torch.cat((ww_200_if, ww_100_g, ww_100_o), 0)
state_dict['lstm_lr.weight_ih_l0_reverse'] = ww_cat_ifgo
bb = from_numpy(weight_numpy_dict['lstm2x_r2'][1]) # [400]
bb_200_if = bb[:200]
bb_100_o = bb[200:300]
bb_100_g = bb[300:400]
bb_cat_ifgo = torch.cat((bb_200_if, bb_100_g, bb_100_o), 0)
state_dict['lstm_lr.bias_ih_l0_reverse'] = bb_cat_ifgo
ww = from_numpy(weight_numpy_dict['lstm2x_r2'][2]) # [400,100]
ww_200_if = ww[:200, :] # [200,100]
ww_100_o = ww[200:300, :] # [100,100]
ww_100_g = ww[300:400, :] # [100,100]
ww_cat_ifgo = torch.cat((ww_200_if, ww_100_g, ww_100_o), 0)
state_dict['lstm_lr.weight_hh_l0_reverse'] = ww_cat_ifgo
state_dict['lstm_lr.bias_hh_l0_reverse'] = from_numpy(np.zeros((400)))
state_dict['fc1x1_r2_v2_a.weight'] = from_numpy(weight_numpy_dict['fc1x1_r2_v2_a'][0])
state_dict['fc1x1_r2_v2_a.bias'] = from_numpy(weight_numpy_dict['fc1x1_r2_v2_a'][1])
####input########################################
path_img = "/data_2/project/1.jpg"
img = cv2.imread(path_img)
# access_pixels(img)
img_stand = LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32)
img_stand = img_stand.astype(np.float32)
# img = (img / 255. - config.DATASET.MEAN) / config.DATASET.STD
img_stand = img_stand.transpose([2, 0, 1])
img_stand = img_stand[None,:,:,:]
img_stand = torch.from_numpy(img_stand)
img_stand = img_stand.type(torch.FloatTensor)
img_stand = img_stand.to(device)
# img_stand = img_stand.view(1, *img.size())
#######net##########################
net.load_state_dict(state_dict)
net.cuda()
net.eval()
preds = net(img_stand)
print("out shape=",preds.shape)
torch.save(net.state_dict(), './lstm_model.pth')
# name_top_caffe_layer = "fc1x_a" #"merge_lstm_rlstmx" #"#"data_bn"
# path_save = "/data_1/Yang/project/myfile/blob_val/" + name_top_caffe_layer + "_torch.txt"
# save_tensor(preds, path_save)
aaa = 0
这里需要注意一下caffe里面的bn层有三个参数,前面两个是均值和方差,第三个参数是一个系数,均值和方差都需要除以这个系数,这个系数是一个固定值999.982
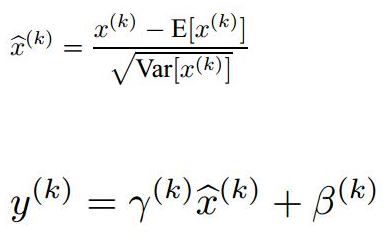
caffe中的scale层就是图中下面这个公式系数。
这里还需要讲下lstm这个算法。在caffe中设定的time_step为80,设定的hidden为100,输入到lstm之前的feature map大小是80,1,512,8.
然后我通过层的权重看到lstm有3个权重,大小分别是[400,4096] [400] [400,100]
lstm通过查看源码发现有参数的就是2个全连接层,[400,4096] [400] 这两个是对输入进行inner所需要的参数,400是100*4得到的,至于为什么是4,这个需要看lstm原理,这里简单说下就是用h,x有4组相乘。
[400,100]是隐含h进行inner所需要的权重。
查看pytorch手册关于lstm介绍。
https://pytorch.org/docs/1.0.1/nn.html?highlight=lstm#torch.nn.LSTM。输入参数介绍。


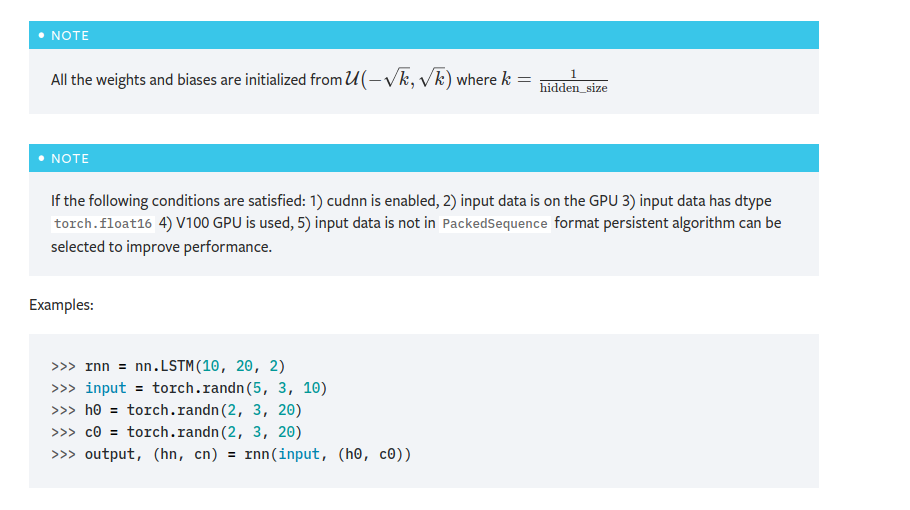
然后根据输入参数,单独写了一个lstm算子测试看看:
import torch
import torch.nn as nn
# rnn = nn.LSTM(512*8, 100, 1, False)
# input = torch.randn(80, 1, 512*8)
#
# output, (hn, cn) = rnn(input)
#
#
# for name,parameters in rnn.named_parameters():
# print(name,':',parameters.size())
# # parm[name]=parameters.detach().numpy()
#
# aa = 0
rnn = nn.LSTM(512*8, 100, 1, bidirectional=True)
input = torch.randn(80, 1, 512*8)
output, (hn, cn) = rnn(input)
print("out shape=",output.shape)
for name,parameters in rnn.named_parameters():
print(name,':',parameters.size())
# parm[name]=parameters.detach().numpy()
aa = 0
输出如下:
('out shape=', (80, 1, 200))
('weight_ih_l0', ':', (400, 4096))
('weight_hh_l0', ':', (400, 100))
('bias_ih_l0', ':', (400,))
('bias_hh_l0', ':', (400,))
('weight_ih_l0_reverse', ':', (400, 4096))
('weight_hh_l0_reverse', ':', (400, 100))
('bias_ih_l0_reverse', ':', (400,))
('bias_hh_l0_reverse', ':', (400,))
Process finished with exit code 0
可以看到pytorch的lstm所需要的参数基本与caffe一致,不过caffe的一个lstm参数是3个,pytorch的lstm参数是4个,显然是因为caffe隐含层的inner没用偏置,到时候直接把一个pytorch的偏置放为0就可以!
然而事情并不是一帆风顺的,上面给出的代码是成功的,但是在此之前我把所有的参数都怼上,但是精度是不对的。后面仔细看lstm源码,发现caffe的计算顺序:
lstm_unit_layer.cpp
template <typename Dtype>
void LSTMUnitLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num = bottom[0]->shape(1);//1
const int x_dim = hidden_dim_ * 4;
const Dtype* C_prev = bottom[0]->cpu_data();
const Dtype* X = bottom[1]->cpu_data();
const Dtype* cont = bottom[2]->cpu_data();
Dtype* C = top[0]->mutable_cpu_data();
Dtype* H = top[1]->mutable_cpu_data();
for (int n = 0; n < num; ++n) { //1
for (int d = 0; d < hidden_dim_; ++d) {//100
const Dtype i = sigmoid(X[d]);
const Dtype f = (*cont == 0) ? 0 :
(*cont * sigmoid(X[1 * hidden_dim_ + d]));weight_ih_l[k] – the learnable input-hidden weights of the \text{k}^{th}k
th
layer (W_ii|W_if|W_ig|W_io), of shape (4*hidden_size x input_size)
weight_hh_l[k] – the learnable hidden-hidden weights of the \text{k}^{th}k
th
layer (W_hi|W_hf|W_hg|W_ho), of shape (4*hidden_size x hidden_size)
bias_ih_l[k] – the learnable input-hidden bias of the \text{k}^{th}k
th
layer (b_ii|b_if|b_ig|b_io), of shape (4*hidden_size)
bias_hh_l[k] – the learnable hidden-hidden bias of the \text{k}^{th}k
th
layer (b_hi|b_hf|b_hg|b_ho), of shape (4*hidden_size)
const Dtype o = sigmoid(X[2 * hidden_dim_ + d]);
const Dtype g = tanh(X[3 * hidden_dim_ + d]);
const Dtype c_prev = C_prev[d];
const Dtype c = f * c_prev + i * g;
C[d] = c;
const Dtype tanh_c = tanh(c);
H[d] = o * tanh_c;
}
C_prev += hidden_dim_;
X += x_dim;
C += hidden_dim_;
H += hidden_dim_;
++cont;
}
}
发现caffe的计算顺序是ifog。
看pytorch说明文档介绍权重的顺序是
weight_ih_l[k] – the learnable input-hidden weights of the \text{k}^{th}k
th
layer (W_ii|W_if|W_ig|W_io), of shape (4*hidden_size x input_size)
weight_hh_l[k] – the learnable hidden-hidden weights of the \text{k}^{th}k
th
layer (W_hi|W_hf|W_hg|W_ho), of shape (4*hidden_size x hidden_size)
bias_ih_l[k] – the learnable input-hidden bias of the \text{k}^{th}k
th
layer (b_ii|b_if|b_ig|b_io), of shape (4*hidden_size)
bias_hh_l[k] – the learnable hidden-hidden bias of the \text{k}^{th}k
th
layer (b_hi|b_hf|b_hg|b_ho), of shape (4*hidden_size)
有点儿不一样,那么我只需要把caffe的权重顺序改下和pytorch一致试试。所有就有了上面的代码:
## caffe i f o g
## pytorch i f g o
ww = from_numpy(weight_numpy_dict['lstm1x_r2'][0]) # [400,4096]
ww_200_if = ww[:200,:] #[200,4096]
ww_100_o = ww[200:300,:] #[100,4096]
ww_100_g = ww[300:400,:]#[100,4096]
ww_cat_ifgo = torch.cat((ww_200_if,ww_100_g,ww_100_o),0)
state_dict['lstm_lr.weight_ih_l0'] = ww_cat_ifgo
这样一整,成功了,精度一致!! 给出测试精度的代码。
不同框架下验证精度 https://www.cnblogs.com/yanghailin/p/15593614.html
给出我跑出结果的代码:
# -*- coding: utf-8
import torch
from torch import nn
import torch.nn.functional as F
import cv2
import numpy as np
import os
from chn_tab import chn_tab
class lstm_general(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
super(lstm_general, self).__init__()
# self.conv1_1 = nn.Conv2d(3, 64, 3, 1, 1)
self.data_bn = nn.BatchNorm2d(3)
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3)
self.conv1_bn = nn.BatchNorm2d(64)
self.conv1_pool = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.layer_64_1_conv1 = nn.Conv2d(64, 64, 1, 1, 0, bias = False)
self.layer_64_1_bn2 = nn.BatchNorm2d(64)
self.layer_64_1_conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer_64_1_bn3 = nn.BatchNorm2d(64)
self.layer_64_1_conv3 = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_64_1_conv_expand = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_128_1_bn1 = nn.BatchNorm2d(256)
self.layer_128_1_conv1 = nn.Conv2d(256, 128, 1, 1, 0, bias=False)
self.layer_128_1_bn2 = nn.BatchNorm2d(128)
self.layer_128_1_conv2 = nn.Conv2d(128, 128, 3, 1, 1, bias=False)
self.layer_128_1_bn3 = nn.BatchNorm2d(128)
self.layer_128_1_conv3 = nn.Conv2d(128, 512, 1, 1, 0, bias=False)
self.layer_128_1_conv_expand = nn.Conv2d(256, 512, 1, 1, 0, bias=False)
self.last_bn = nn.BatchNorm2d(512)
# self.lstm_1 = nn.LSTM(512 * 8, 100, 1, bidirectional=False)
self.lstm_lr = nn.LSTM(512 * 8, 100, 1, bidirectional=True)
self.fc1x1_r2_v2_a = nn.Linear(200,7118)
def forward(self, inputs):
# x = F.relu(self.bn1_1(self.conv1_1(inputs)))
x = self.data_bn(inputs)
x = F.relu(self.conv1_bn(self.conv1(x)))
x = self.conv1_pool(x) #[1,64,8,80]
x = F.relu(self.layer_64_1_bn2(self.layer_64_1_conv1(x))) # 1 64 8 80
layer_64_1_conv1 = x
x = F.relu(self.layer_64_1_bn3(self.layer_64_1_conv2(x)))
x = self.layer_64_1_conv3(x)
layer_64_1_conv_expand = self.layer_64_1_conv_expand(layer_64_1_conv1)
layer_64_3_sum = x + layer_64_1_conv_expand #1 256 8 80
x = F.relu(self.layer_128_1_bn1(layer_64_3_sum))
layer_128_1_bn1 = x
x = F.relu(self.layer_128_1_bn2(self.layer_128_1_conv1(x)))
x = F.relu(self.layer_128_1_bn3(self.layer_128_1_conv2(x)))
x = self.layer_128_1_conv3(x) #1, 512, 8, 80
layer_128_1_conv_expand = self.layer_128_1_conv_expand(layer_128_1_bn1) #1, 512, 8, 80
layer_128_4_sum = x + layer_128_1_conv_expand
x = F.relu(self.last_bn(layer_128_4_sum))###acc ok
x = F.dropout(x, p=0.7, training=False) #1 512 8 80
x = x.permute(3,0,1,2) # 80 1 512 8
x = x.reshape(80,1,512*8)###acc ok
#
# merge_lstm_rlstmx, (hn, cn) = self.lstm_r(x)
lstm_out,(_,_) = self.lstm_lr(x) #(80,1,200)
return lstm_out
out = self.fc1x1_r2_v2_a(lstm_out) #(80,1,7118)
return out
def LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32):
img_h, img_w, _ = img.shape
if img_h < 2 or img_w < 2:
return
# if 32 == img_h and 320 == img_w:
# return img
ratio_now = img_w * 1.0 / img_h
if ratio_now <= ratio:
mask = np.ones((img_h, int(img_h * ratio), 3), dtype=np.uint8) * 255
mask[0:img_h,0:img_w,:] = img
else:
mask = np.ones((int(img_w*1.0/ratio), img_w, 3), dtype=np.uint8) * 255
mask[0:img_h, 0:img_w, :] = img
mask_stand = cv2.resize(mask,(stand_w, stand_h),interpolation=cv2.INTER_LINEAR)
# access_pixels(mask_stand)
return mask_stand
if __name__ == '__main__':
path_model = "/data_1/everyday/1118/pytorch_lstm_test/lstm_model.pth"
path_img = "/data_2/project_202009/chejian/test_data/model_test/rec_general/1.jpg"
blank_label = 7117
prev_label = blank_label
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
img = cv2.imread(path_img)
img_stand = LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32)
img_stand = img_stand.astype(np.float32)
img_stand = img_stand.transpose([2, 0, 1])
img_stand = img_stand[None, :, :, :]
img_stand = torch.from_numpy(img_stand)
img_stand = img_stand.type(torch.FloatTensor)
img_stand = img_stand.to(device)
net = lstm_general()
checkpoint = torch.load(path_model)
net.load_state_dict(checkpoint)
net.cuda()
net.eval()
# traced_script_module = torch.jit.trace(net, img_stand)
# traced_script_module.save("./lstm.pt")
preds = net(img_stand)
# print("out shape=", preds.shape)
preds_1 = preds.squeeze()
# print("preds_1 out shape=", preds_1.shape)
val, pos = torch.max(preds_1,1)
pos = pos.cpu().numpy()
rec = ""
for predict_label in pos:
if predict_label != blank_label and predict_label != prev_label:
# print("predict_label=",predict_label)
print(chn_tab[predict_label])
rec += chn_tab[predict_label]
prev_label = predict_label
# print("rec=",rec)
print(rec)
弄成功了,但是只高兴了一天。
我最终目的是能在c++下面跑,于是转libtorch,本来我以为这是轻而易举的事情,但是事情并没有那么简单。
我发现我的libtorch代码经过lstm这层之后精度就对不上了,在此之前都是可以对上的。!!!无解。
可能和版本有关系,因为我用高版本的libtorch之前是转成功一个crnn的,是没有问题的。
https://github.com/wuzuowuyou/crnn_libtorch
这个是pytorch1.7版本的,而我现在是用的1.0版本的。我试了很久发现还是精度不对,这就无法解决了,也不知道从何下手去解决这个问题。翻遍了pytorch github上面的issue,没人遇到和我一样的问题。。。除非看pytorch源码去找问题,这太难了。
在pytorch的github提了issue
https://github.com/pytorch/pytorch/issues/68864
我知道这也会石沉大海的。
以下是我凌乱的,未完工的代码:
#include <torch/script.h> // One-stop header.
#include "torch/torch.h"
#include "torch/jit.h"
#include <memory>
#include "opencv2/opencv.hpp"
#include <queue>
#include <dirent.h>
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
using namespace cv;
using namespace std;
// cv::Mat m_stand;
#define TABLE_SIZE 7117
static string chn_tab[TABLE_SIZE+1] = {"啊","阿","埃"
。。。
。。。
。。。
"0","1","2","3","4","5","6","7","8","9",
":",";","<","=",">","?","@",
"A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z",
"[","\\","]","^","_","`",
"a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z",
"{","|","}","~",
" "};
bool LstmImgStandardization_src_1(const cv::Mat &src, const float &ratio, int standard_w, int standard_h, cv::Mat &dst)
{
if(src.empty())return false;
float width=src.cols;
float height=src.rows;
float a=width/ height;
if(a <=ratio)
{
Mat mask(height, ratio*height, CV_8UC3, cv::Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
else
{
Mat mask(width/ratio, width, CV_8UC3, cv::Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
//cv::resize(dst, dst, cv::Size(standard_w,standard_h));
cv::resize(dst, dst, cv::Size(standard_w,standard_h),0,0,cv::INTER_AREA);
return true;
}
bool lstm_img_standardization(cv::Mat src, cv::Mat &dst,float ratio)
{
if(src.empty())return false;
double width=src.cols;
double height=src.rows;
double a=width/height;
if(a <=ratio)//6
{
Mat mask(height, ratio*height, CV_8UC3, Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
else
{
Mat mask(width/ratio, width, CV_8UC3, Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
// cv::resize(dst, dst, cv::Size(360,60));
cv::resize(dst, dst, cv::Size(320,32));
return true;
}
//torch::Tensor pre_img(cv::Mat &img)
//{
// cv::Mat m_stand;
// float ratio = 10.0;
// if(1 == img.channels()) { cv::cvtColor(img,img,CV_GRAY2BGR); }
// lstm_img_standardization(img, m_stand, ratio);
//
// std::vector<int64_t> sizes = {m_stand.rows, m_stand.cols, m_stand.channels()};
// torch::TensorOptions options = torch::TensorOptions().dtype(torch::kByte);
// torch::Tensor tensor_image = torch::from_blob(m_stand.data, torch::IntList(sizes), options);
// // Permute tensor, shape is (C, H, W)
// tensor_image = tensor_image.permute({2, 0, 1});
//
//
// // Convert tensor dtype to float32, and range from [0, 255] to [0, 1]
// tensor_image = tensor_image.toType(torch::ScalarType::Float);
//
//
//// tensor_image = tensor_image.div_(255.0);
//// // Subtract mean value
//// for (int i = 0; i < std::min<int64_t>(v_mean.size(), tensor_image.size(0)); i++) {
//// tensor_image[i] = tensor_image[i].sub_(v_mean[i]);
//// }
//// // Divide by std value
//// for (int i = 0; i < std::min<int64_t>(v_std.size(), tensor_image.size(0)); i++) {
//// tensor_image[i] = tensor_image[i].div_(v_std[i]);
//// }
// //[c,h,w] --> [1,c,h,w]
// tensor_image.unsqueeze_(0);
// std::cout<<tensor_image;
// return tensor_image;
//}
bool pre_img(cv::Mat &img, torch::Tensor &input_tensor)
{
static cv::Mat m_stand;
float ratio = 10.0;
// if(1 == img.channels()) { cv::cvtColor(img,img,CV_GRAY2BGR); }
lstm_img_standardization(img, m_stand, ratio);
m_stand.convertTo(m_stand, CV_32FC3);
// imshow("m_stand",m_stand);
// waitKey(0);
// Mat m_stand_new;
// m_stand.convertTo(m_stand_new, CV_32FC3);
// int rowNumber = m_stand_new.rows; //行数
// int colNumber = m_stand_new.cols*m_stand_new.channels(); //列数 x 通道数=每一行元素的个数
// std::ofstream out_file("/data_1/everyday/1123/img_acc/after_CV_32FC3-float-111.txt");
// //双重循环,遍历所有的像素值
// for (int i = 0; i < rowNumber; i++) //行循环
// {
// uchar *data = m_stand_new.ptr<uchar>(i); //获取第i行的首地址
// for (int j = 0; j < colNumber; j++) //列循环
// {
// // ---------【开始处理每个像素】-------------
// int pix = int(data[j]);
// out_file << pix << std::endl;
// }
// }
//
// out_file.close();
// std::cout<<"==m_stand.convertTo(m_stand, CV_32FC3);=="<<std::endl;
// while(1);
int stand_row = m_stand.rows;
int stand_cols = m_stand.cols;
input_tensor = torch::from_blob(
m_stand.data, {stand_row, stand_cols, 3}).toType(torch::kFloat);
input_tensor = input_tensor.permute({2,0,1});
input_tensor = input_tensor.unsqueeze(0);//.to(torch::kFloat);
// std::cout<<input_tensor;
return true;
}
void GetFileInDir(string dirName, vector<string> &v_path)
{
DIR* Dir = NULL;
struct dirent* file = NULL;
if (dirName[dirName.size()-1] != '/')
{
dirName += "/";
}
if ((Dir = opendir(dirName.c_str())) == NULL)
{
cerr << "Can't open Directory" << endl;
exit(1);
}
while (file = readdir(Dir))
{
//if the file is a normal file
if (file->d_type == DT_REG)
{
v_path.push_back(dirName + file->d_name);
}
//if the file is a directory
else if (file->d_type == DT_DIR && strcmp(file->d_name, ".") != 0 && strcmp(file->d_name, "..") != 0)
{
GetFileInDir(dirName + file->d_name,v_path);
}
}
}
string str_replace(const string &str,const string &str_find,const string &str_replacee)
{
string str_tmp=str;
size_t pos = str_tmp.find(str_find);
while (pos != string::npos)
{
str_tmp.replace(pos, str_find.length(), str_replacee);
size_t pos_t=pos+str_replacee.length();
string str_sub=str_tmp.substr(pos_t,str_tmp.length()-pos_t);
size_t pos_tt=str_sub.find(str_find);
if(string::npos != pos_tt)
{
pos =pos_t + str_sub.find(str_find);
}else
{
pos=string::npos;
}
}
return str_tmp;
}
string get_ans(const string path)
{
int pos_1 = path.find_last_of("_");
int pos_2 = path.find_last_of(".");
string ans = path.substr(pos_1+1,pos_2-pos_1-1);
ans = str_replace(ans,"@","/");
return ans;
}
bool save_tensor_txt(torch::Tensor tensor_in_,string path_txt)
{
#include "fstream"
ofstream outfile(path_txt);
torch::Tensor tensor_in = tensor_in_.clone();
tensor_in = tensor_in.view({-1,1});
tensor_in = tensor_in.to(torch::kCPU);
auto result_data = tensor_in.accessor<float, 2>();
for(int i=0;i<result_data.size(0);i++)
{
float val = result_data[i][0];
// std::cout<<"val="<<val<<std::endl;
outfile<<val<<std::endl;
}
return true;
}
int main()
{
std::string path_pt = "/data_1/everyday/1118/pytorch_lstm_test/lstmunidirectional20211124.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm20211124.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm10000.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm.pt";
std::string path_img_dir = "/data_1/2020biaozhushuju/2021_rec/general/test";//"/data_1/everyday/1118/pytorch_lstm_test/test_data";
int blank_label = 7117;
std::ifstream list("/data_1/everyday/1123/list.txt");
int standard_w = 320;
int standard_h = 32;
// vector<string> v_path;
// GetFileInDir(path_img_dir, v_path);
// for(int i=0;i<v_path.size();i++)
// {
// std::cout<<i<<" "<<v_path[i]<<std::endl;
// }
torch::Device m_device(torch::kCUDA);
// torch::Device m_device(torch::kCPU);
std::shared_ptr<torch::jit::script::Module> m_model = torch::jit::load(path_pt);
torch::NoGradGuard no_grad;
m_model->to(m_device);
std::cout<<"success load model"<<std::endl;
int cnt_all = 0;
int cnt_right = 0;
double start = getTickCount();
string file;
while(list >> file)
{
file = "/data_1/everyday/1123/img/bxd_39_发动机号码.jpg";
cout<<cnt_all++<<" :: "<<file<<endl;
string jpg=".jpg";
string::size_type idx = file.find( jpg );
if ( idx == string::npos )
continue;
int pos_1 = file.find_last_of("_");
int pos_2 = file.find_last_of(".");
string answer = file.substr(pos_1+1,pos_2-pos_1-1);
cv::Mat img = cv::imread(file);
// int rowNumber = img.rows; //行数
// int colNumber = img.cols*img.channels(); //列数 x 通道数=每一行元素的个数
// std::ofstream out_file("/data_1/everyday/1123/img_acc/libtorch_img.txt");
// //双重循环,遍历所有的像素值
// for (int i = 0; i < rowNumber; i++) //行循环
// {
// uchar *data = img.ptr<uchar>(i); //获取第i行的首地址
// for (int j = 0; j < colNumber; j++) //列循环
// {
// // ---------【开始处理每个像素】-------------
// int pix = int(data[j]);
// out_file << pix << std::endl;
// }
// }
//
// out_file.close();
// while(1);
torch::Tensor tensor_input;
pre_img(img, tensor_input);
tensor_input = tensor_input.to(m_device);
tensor_input.print();
std::cout<<tensor_input[0][2][12][25]<<std::endl;
std::cout<<tensor_input[0][1][15][100]<<std::endl;
std::cout<<tensor_input[0][0][16][132]<<std::endl;
std::cout<<tensor_input[0][1][17][156]<<std::endl;
std::cout<<tensor_input[0][2][5][256]<<std::endl;
std::cout<<tensor_input[0][0][14][205]<<std::endl;
save_tensor_txt(tensor_input, "/data_1/everyday/1124/acc/libtorch_input-100.txt");
torch::Tensor output = m_model->forward({tensor_input}).toTensor();
output.print();
// output = output.squeeze();//80,7118
// output.print();
save_tensor_txt(output, "/data_1/everyday/1124/acc/libtorch-out-100.txt");
//// std::cout<<output<<std::endl;
while(1);
//
torch::Tensor index = torch::argmax(output,1).cpu();//.to(torch::kInt);
index.print();
// std::cout<<index<<std::endl;
// while(1);
int prev_label = blank_label;
string result;
auto result_data = index.accessor<long, 1>();
for(int i=0;i<result_data.size(0);i++)
{
// std::cout<<result_data[i]<<std::endl;
int predict_label = result_data[i];
if (predict_label != blank_label && predict_label != prev_label )
{
{
result = result + chn_tab[predict_label];
}
}
prev_label = predict_label;
}
cout << "answer: " << answer << endl;
cout << "result : " << result << endl;
imshow("src",img);
waitKey(0);
// while(1);
}
// for(int i=0;i<v_path.size();i++)
// {
// cnt_all += 1;
// std::string path_img = v_path[i];
// string ans = get_ans(path_img);
// std::cout<<i<<" path="<<path_img<<" ans="<<ans<<std::endl;
// cv::Mat img = cv::imread(path_img);
// torch::Tensor input = pre_img(img, v_mean, v_std, standard_w, standard_h);
// input = input.to(m_device);
// torch::Tensor output = m_module.forward({input}).toTensor();
//
// std::string rec = get_label(output);
//#if 1 //for show
// std::cout<<"rec="<<rec<<std::endl;
// std::cout<<"ans="<<ans<<std::endl;
// cv::imshow("img",img);
// cv::waitKey(0);
//#endif
//
//#if 0 //In order to test the accuracy
// std::cout<<"rec="<<rec<<std::endl;
// std::cout<<"ans="<<ans<<std::endl;
// if(ans == rec)
// {
// cnt_right += 1;
// }
// std::cout<<"cnt_right="<<cnt_right<<std::endl;
// std::cout<<"cnt_all="<<cnt_all<<std::endl;
// std::cout<<"ratio="<<cnt_right * 1.0 / cnt_all<<std::endl;
//#endif
// }
// double time_cunsume = ((double)getTickCount() - start) / getTickFrequency();
// std::cout<<"ave time="<< time_cunsume * 1.0 / cnt_all * 1000 <<"ms"<<std::endl;
return 0;
}
------------------2021年11月25日10:18:54
早上来看到github有人回复建议我升级到最新版本看看。
没办法,我本地有pytorch1.1.0, cuda10.0, libtorch1.1.0的环境,我就直接用这个环境再来一遍,先生成pth,看模型输出是正确的,然后再生成pt,然后配置libtorch的cmakelist,然后再跑,发现没问题!!!
也就是说确实是libtorch1.0的问题了。无解。
这里再配上我cmakelist
cmake_minimum_required(VERSION 2.6)
project(libtorch_lstm_1.1.0)
set(CMAKE_BUILD_TYPE Debug)
set(CMAKE_BUILD_TYPE Debug CACHE STRING "set build type to debug")
#add_definitions(-std=c++11)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
#set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
# cuda10
include_directories(${CMAKE_SOURCE_DIR}/3rdparty/cuda/include)
link_directories(${CMAKE_SOURCE_DIR}/3rdparty/cuda/lib64)
###libtorch1.1.0
set(TORCH_ROOT ${CMAKE_SOURCE_DIR}/3rdparty/libtorch)
set(CMAKE_PREFIX_PATH ${CMAKE_SOURCE_DIR}/3rdparty/libtorch)
include_directories(${TORCH_ROOT}/include)
include_directories(${TORCH_ROOT}/include/torch/csrc/api/include)
link_directories(${TORCH_ROOT}/lib)
#OpenCv3.4.10
set(OPENCV_ROOT ${CMAKE_SOURCE_DIR}/3rdparty/opencv-3.4.10)
include_directories(${OPENCV_ROOT}/include)
link_directories(${OPENCV_ROOT}/lib)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -Wfatal-errors -D_MWAITXINTRIN_H_INCLUDED")
add_executable(libtorch_lstm ${PROJECT_SOURCE_DIR}/lstm.cpp)
target_link_libraries(libtorch_lstm opencv_calib3d opencv_core opencv_imgproc opencv_highgui opencv_imgcodecs)
target_link_libraries(libtorch_lstm torch c10 caffe2)
target_link_libraries(libtorch_lstm nvrtc cuda)
#target_link_libraries(crnn c10 c10_cuda torch torch_cuda torch_cpu "-Wl,--no-as-needed -ltorch_cuda")
add_definitions(-O2 -pthread)
#include <torch/script.h> // One-stop header.
#include "torch/torch.h"
#include "torch/jit.h"
#include <memory>
#include "opencv2/opencv.hpp"
#include <queue>
#include <dirent.h>
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
using namespace cv;
using namespace std;
// cv::Mat m_stand;
#define TABLE_SIZE 7117
static string chn_tab[TABLE_SIZE+1] = {"啊","阿","埃","挨","哎","唉",
。。。
。。。
。。。
"∴","♂","♀","°","′","″","℃","$","¤","¢","£","‰","§","№","☆","★",
"○","●","◎","◇","◆","□","■","△","▲","※","→","←","↑","↓","〓",
"⒈","⒉","⒊","⒋","⒌","⒍","⒎","⒏","⒐","⒑","⒒","⒓","⒔","⒕","⒖",
"⒗","⒘","⒙","⒚","⒛","⑴","⑵","⑶","⑷","⑸","⑹","⑺","⑻","⑼","⑽","⑾",
"⑿","⒀","⒁","⒂","⒃","⒄","⒅","⒆","⒇","①","②","③","④","⑤","⑥","⑦",
"⑧","⑨","⑩","㈠","㈡","㈢","㈣","㈤","㈥","㈦","㈧","㈨","㈩",
"Ⅰ","Ⅱ","Ⅲ","Ⅳ","Ⅴ","Ⅵ","Ⅶ","Ⅷ","Ⅸ","Ⅹ","Ⅺ","Ⅻ",
"!",""","#","¥","%","&","'","(",")","*","+",",","-",".","/",
"0","1","2","3","4","5","6","7","8","9",":",";","<","=",">","?",
"@","A","B","C","D","E","F","G","H","I","J","K","L","M","N","O",
"P","Q","R","S","T","U","V","W","X","Y","Z","[","\","]","^","_",
"`","a","b","c","d","e","f","g","h","i","j","k","l","m","n","o",
"p","q","r","s","t","u","v","w","x","y","z","{","|","}"," ̄",
"!","\"","#","$","%","&","'","(",")","*","+",",","-",".","/", //========ascii========//
"0","1","2","3","4","5","6","7","8","9",
":",";","<","=",">","?","@",
"A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z",
"[","\\","]","^","_","`",
"a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z",
"{","|","}","~",
" "};
bool LstmImgStandardization_src_1(const cv::Mat &src, const float &ratio, int standard_w, int standard_h, cv::Mat &dst)
{
if(src.empty())return false;
float width=src.cols;
float height=src.rows;
float a=width/ height;
if(a <=ratio)
{
Mat mask(height, ratio*height, CV_8UC3, cv::Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
else
{
Mat mask(width/ratio, width, CV_8UC3, cv::Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
//cv::resize(dst, dst, cv::Size(standard_w,standard_h));
cv::resize(dst, dst, cv::Size(standard_w,standard_h),0,0,cv::INTER_AREA);
return true;
}
bool lstm_img_standardization(cv::Mat src, cv::Mat &dst,float ratio)
{
if(src.empty())return false;
double width=src.cols;
double height=src.rows;
double a=width/height;
if(a <=ratio)//6
{
Mat mask(height, ratio*height, CV_8UC3, Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
else
{
Mat mask(width/ratio, width, CV_8UC3, Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
// cv::resize(dst, dst, cv::Size(360,60));
cv::resize(dst, dst, cv::Size(320,32));
return true;
}
//torch::Tensor pre_img(cv::Mat &img)
//{
// cv::Mat m_stand;
// float ratio = 10.0;
// if(1 == img.channels()) { cv::cvtColor(img,img,CV_GRAY2BGR); }
// lstm_img_standardization(img, m_stand, ratio);
//
// std::vector<int64_t> sizes = {m_stand.rows, m_stand.cols, m_stand.channels()};
// torch::TensorOptions options = torch::TensorOptions().dtype(torch::kByte);
// torch::Tensor tensor_image = torch::from_blob(m_stand.data, torch::IntList(sizes), options);
// // Permute tensor, shape is (C, H, W)
// tensor_image = tensor_image.permute({2, 0, 1});
//
//
// // Convert tensor dtype to float32, and range from [0, 255] to [0, 1]
// tensor_image = tensor_image.toType(torch::ScalarType::Float);
//
//
//// tensor_image = tensor_image.div_(255.0);
//// // Subtract mean value
//// for (int i = 0; i < std::min<int64_t>(v_mean.size(), tensor_image.size(0)); i++) {
//// tensor_image[i] = tensor_image[i].sub_(v_mean[i]);
//// }
//// // Divide by std value
//// for (int i = 0; i < std::min<int64_t>(v_std.size(), tensor_image.size(0)); i++) {
//// tensor_image[i] = tensor_image[i].div_(v_std[i]);
//// }
// //[c,h,w] --> [1,c,h,w]
// tensor_image.unsqueeze_(0);
// std::cout<<tensor_image;
// return tensor_image;
//}
bool pre_img(cv::Mat &img, torch::Tensor &input_tensor)
{
static cv::Mat m_stand;
float ratio = 10.0;
// if(1 == img.channels()) { cv::cvtColor(img,img,CV_GRAY2BGR); }
lstm_img_standardization(img, m_stand, ratio);
m_stand.convertTo(m_stand, CV_32FC3);
// imshow("m_stand",m_stand);
// waitKey(0);
// Mat m_stand_new;
// m_stand.convertTo(m_stand_new, CV_32FC3);
// int rowNumber = m_stand_new.rows; //行数
// int colNumber = m_stand_new.cols*m_stand_new.channels(); //列数 x 通道数=每一行元素的个数
// std::ofstream out_file("/data_1/everyday/1123/img_acc/after_CV_32FC3-float-111.txt");
// //双重循环,遍历所有的像素值
// for (int i = 0; i < rowNumber; i++) //行循环
// {
// uchar *data = m_stand_new.ptr<uchar>(i); //获取第i行的首地址
// for (int j = 0; j < colNumber; j++) //列循环
// {
// // ---------【开始处理每个像素】-------------
// int pix = int(data[j]);
// out_file << pix << std::endl;
// }
// }
//
// out_file.close();
// std::cout<<"==m_stand.convertTo(m_stand, CV_32FC3);=="<<std::endl;
// while(1);
int stand_row = m_stand.rows;
int stand_cols = m_stand.cols;
input_tensor = torch::from_blob(
m_stand.data, {stand_row, stand_cols, 3}).toType(torch::kFloat);
input_tensor = input_tensor.permute({2,0,1});
input_tensor = input_tensor.unsqueeze(0);//.to(torch::kFloat);
// std::cout<<input_tensor;
return true;
}
void GetFileInDir(string dirName, vector<string> &v_path)
{
DIR* Dir = NULL;
struct dirent* file = NULL;
if (dirName[dirName.size()-1] != '/')
{
dirName += "/";
}
if ((Dir = opendir(dirName.c_str())) == NULL)
{
cerr << "Can't open Directory" << endl;
exit(1);
}
while (file = readdir(Dir))
{
//if the file is a normal file
if (file->d_type == DT_REG)
{
v_path.push_back(dirName + file->d_name);
}
//if the file is a directory
else if (file->d_type == DT_DIR && strcmp(file->d_name, ".") != 0 && strcmp(file->d_name, "..") != 0)
{
GetFileInDir(dirName + file->d_name,v_path);
}
}
}
string str_replace(const string &str,const string &str_find,const string &str_replacee)
{
string str_tmp=str;
size_t pos = str_tmp.find(str_find);
while (pos != string::npos)
{
str_tmp.replace(pos, str_find.length(), str_replacee);
size_t pos_t=pos+str_replacee.length();
string str_sub=str_tmp.substr(pos_t,str_tmp.length()-pos_t);
size_t pos_tt=str_sub.find(str_find);
if(string::npos != pos_tt)
{
pos =pos_t + str_sub.find(str_find);
}else
{
pos=string::npos;
}
}
return str_tmp;
}
string get_ans(const string path)
{
int pos_1 = path.find_last_of("_");
int pos_2 = path.find_last_of(".");
string ans = path.substr(pos_1+1,pos_2-pos_1-1);
ans = str_replace(ans,"@","/");
return ans;
}
bool save_tensor_txt(torch::Tensor tensor_in_,string path_txt)
{
#include "fstream"
ofstream outfile(path_txt);
torch::Tensor tensor_in = tensor_in_.clone();
tensor_in = tensor_in.view({-1,1});
tensor_in = tensor_in.to(torch::kCPU);
auto result_data = tensor_in.accessor<float, 2>();
for(int i=0;i<result_data.size(0);i++)
{
float val = result_data[i][0];
// std::cout<<"val="<<val<<std::endl;
outfile<<val<<std::endl;
}
return true;
}
int main()
{
std::string path_pt = "/data_1/everyday/1125/lstm/lstm20211125.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstmunidirectional20211124.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm20211124.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm10000.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm.pt";
std::string path_img_dir = "/data_1/2020biaozhushuju/2021_rec/general/test";//"/data_1/everyday/1118/pytorch_lstm_test/test_data";
int blank_label = 7117;
std::ifstream list("/data_1/everyday/1123/list.txt");
int standard_w = 320;
int standard_h = 32;
// vector<string> v_path;
// GetFileInDir(path_img_dir, v_path);
// for(int i=0;i<v_path.size();i++)
// {
// std::cout<<i<<" "<<v_path[i]<<std::endl;
// }
torch::Device m_device(torch::kCUDA);
// torch::Device m_device(torch::kCPU);
std::shared_ptr<torch::jit::script::Module> m_model = torch::jit::load(path_pt);
torch::NoGradGuard no_grad;
m_model->to(m_device);
std::cout<<"success load model"<<std::endl;
int cnt_all = 0;
int cnt_right = 0;
double start = getTickCount();
string file;
while(list >> file)
{
file = "/data_2/project_202009/chejian/test_data/model_test/rec_general/1.jpg";
cout<<cnt_all++<<" :: "<<file<<endl;
string jpg=".jpg";
string::size_type idx = file.find( jpg );
if ( idx == string::npos )
continue;
int pos_1 = file.find_last_of("_");
int pos_2 = file.find_last_of(".");
string answer = file.substr(pos_1+1,pos_2-pos_1-1);
cv::Mat img = cv::imread(file);
// int rowNumber = img.rows; //行数
// int colNumber = img.cols*img.channels(); //列数 x 通道数=每一行元素的个数
// std::ofstream out_file("/data_1/everyday/1123/img_acc/libtorch_img.txt");
// //双重循环,遍历所有的像素值
// for (int i = 0; i < rowNumber; i++) //行循环
// {
// uchar *data = img.ptr<uchar>(i); //获取第i行的首地址
// for (int j = 0; j < colNumber; j++) //列循环
// {
// // ---------【开始处理每个像素】-------------
// int pix = int(data[j]);
// out_file << pix << std::endl;
// }
// }
//
// out_file.close();
// while(1);
torch::Tensor tensor_input;
pre_img(img, tensor_input);
tensor_input = tensor_input.to(m_device);
tensor_input.print();
std::cout<<tensor_input[0][2][12][25]<<std::endl;
std::cout<<tensor_input[0][1][15][100]<<std::endl;
std::cout<<tensor_input[0][0][16][132]<<std::endl;
std::cout<<tensor_input[0][1][17][156]<<std::endl;
std::cout<<tensor_input[0][2][5][256]<<std::endl;
std::cout<<tensor_input[0][0][14][205]<<std::endl;
save_tensor_txt(tensor_input, "/data_1/everyday/1124/acc/libtorch_input-100.txt");
torch::Tensor output = m_model->forward({tensor_input}).toTensor();
output.print();
output = output.squeeze();//80,7118
output.print();
// save_tensor_txt(output, "/data_1/everyday/1124/acc/libtorch-out-100.txt");
////// std::cout<<output<<std::endl;
// while(1);
//
torch::Tensor index = torch::argmax(output,1).cpu();//.to(torch::kInt);
index.print();
// std::cout<<index<<std::endl;
// while(1);
int prev_label = blank_label;
string result;
auto result_data = index.accessor<long, 1>();
for(int i=0;i<result_data.size(0);i++)
{
// std::cout<<result_data[i]<<std::endl;
int predict_label = result_data[i];
if (predict_label != blank_label && predict_label != prev_label )
{
{
result = result + chn_tab[predict_label];
}
}
prev_label = predict_label;
}
cout << "answer: " << answer << endl;
cout << "result : " << result << endl;
imshow("src",img);
waitKey(0);
// while(1);
}
// for(int i=0;i<v_path.size();i++)
// {
// cnt_all += 1;
// std::string path_img = v_path[i];
// string ans = get_ans(path_img);
// std::cout<<i<<" path="<<path_img<<" ans="<<ans<<std::endl;
// cv::Mat img = cv::imread(path_img);
// torch::Tensor input = pre_img(img, v_mean, v_std, standard_w, standard_h);
// input = input.to(m_device);
// torch::Tensor output = m_module.forward({input}).toTensor();
//
// std::string rec = get_label(output);
//#if 1 //for show
// std::cout<<"rec="<<rec<<std::endl;
// std::cout<<"ans="<<ans<<std::endl;
// cv::imshow("img",img);
// cv::waitKey(0);
//#endif
//
//#if 0 //In order to test the accuracy
// std::cout<<"rec="<<rec<<std::endl;
// std::cout<<"ans="<<ans<<std::endl;
// if(ans == rec)
// {
// cnt_right += 1;
// }
// std::cout<<"cnt_right="<<cnt_right<<std::endl;
// std::cout<<"cnt_all="<<cnt_all<<std::endl;
// std::cout<<"ratio="<<cnt_right * 1.0 / cnt_all<<std::endl;
//#endif
// }
// double time_cunsume = ((double)getTickCount() - start) / getTickFrequency();
// std::cout<<"ave time="<< time_cunsume * 1.0 / cnt_all * 1000 <<"ms"<<std::endl;
return 0;
}
这里再说下遇到的一些坑,因为不同框架之间做转移,就是需要对比每一个环节的精度,一开始遇到一个问题精度对不上,然后一步步找问题,看哪一个环节精度开始不对的,最终定位在两边opencv imread之后的图像像素就开始不一样了!
原来是opencv版本不一样,一个版本是opencv3.3的,一个是opencv3.4.10的。所以做这些还需要版本严格一致,要不然会带来意想不到的问题。