这篇随笔并非全文照着翻译,如果需要看原版,请自行使用浏览器自带翻译,我这边只是截取一些个人关注点,截取部分图片。
浏览器主要组件:
1,用户界面
2,浏览器引擎:查询和操作渲染引擎的界面
3,渲染引擎:负责显示请求的内容。这里主要是负责解析和显示。
4,网络:如HTTP请求
5,UI后端:绘制组合框和窗口等部件
6,JavaScript解释器:解析和执行JavaScript代码
7,数据存储:保存硬盘上的数据,包括cookie,storage,indexDB等
渲染引擎
Firefox使用的Gecko,Safari和Chrome使用的Webkit。webkit是Linux平台的引擎启动,由Apple修改以支持Mac和Windows。
基本流程:
1,解析HTML文档,并将标签转换成content tree“内容树”中的DOM节点
2,解析外部css文件和样式元素,创建render tree“渲染树”
3,给渲染树进行layout布局,给每个节点一个确切的坐标
4,painting“绘画”渲染树,并且将每个节点用UI后端图层进行绘制。
这里截一张原版图:

但是Webkit和Gecko的渲染引擎流程有部分不同,先放图:
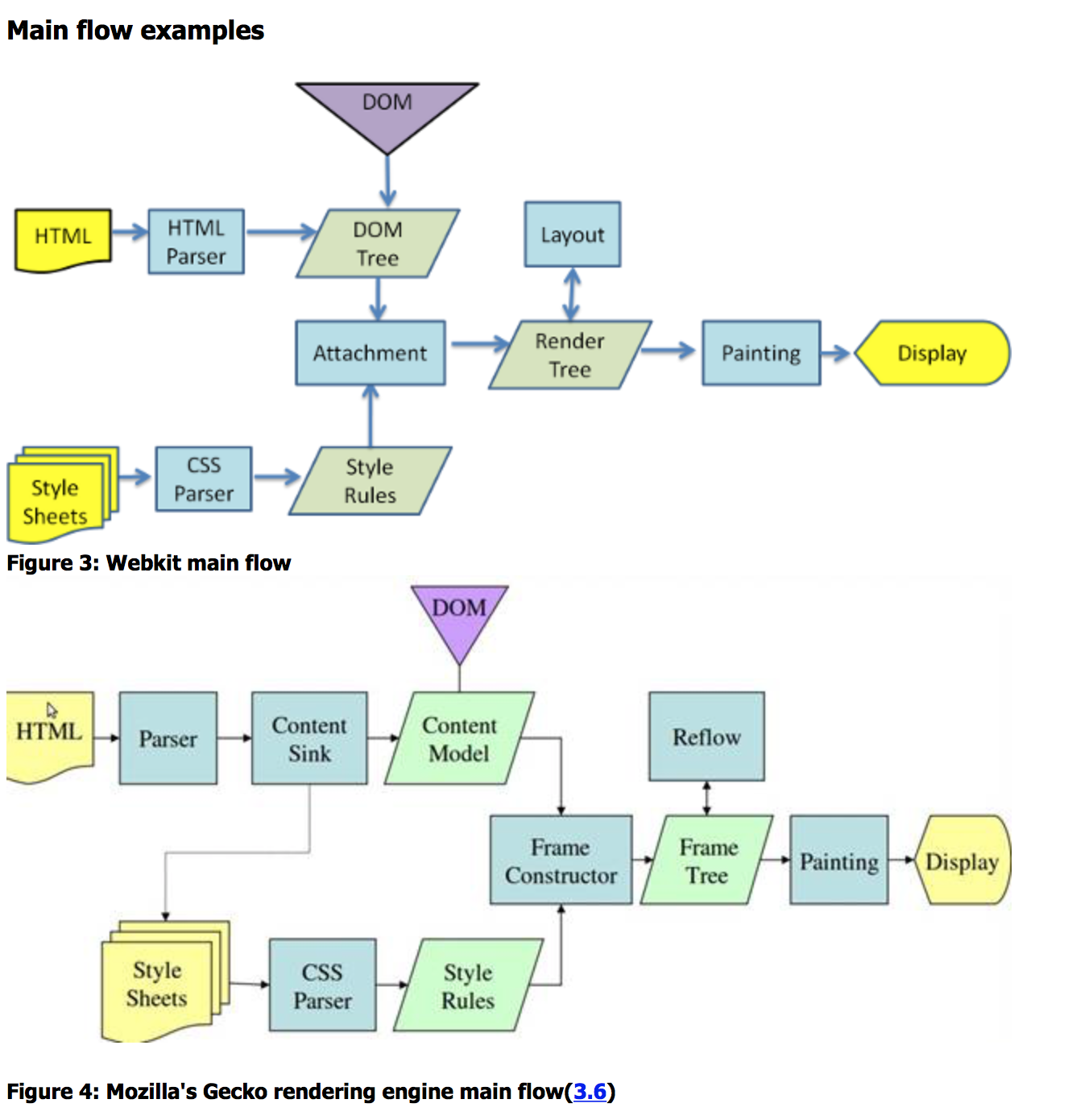
其实大部分都差不多,两个最大的不同点是:
1,Gecko在HTML和DOM树之间有一个Content Sink,是用来制作DOM元素的工厂
2,Gecko里的layout布局被叫做Reflow回流
解析器-Lexer组合(我也不懂这啥意思,还是名字就叫这个)
解析分为两个子过程:
1,词法分析:将输入内容分解为大量标记的过程。标记是语言中的词汇,也就是构成内容的单位,也就是我们普通话对应的字典里面所有的单词。
2,语法分析:应用语言语法规则。
解析器通常先让词法分析器(标记器)将输入的内容分解为有效标记,然后解析器根据语言规则进行语法分析文档结构,从而构建解析树。这里词法分析器的作用是知道如何去除不相关的字符,如空格和换行符。

解析的过程是不断重复的,因为它是一个标记一个标记解析的,解析器每次从词法分析器处取一个标记,然后尝试用这个标记去匹配一条语法规则,如果匹配了,就把这个标记对应的节点添加到解析树上,然后继续去取。如果没有匹配到,就先将这个标记保存在内部,然后先去取下一个,直到所有保存的标记能够匹配一条语法规则。如果解析结束时都没有匹配到规则,那么解析器就抛出异常,意味着语法错误或者文档无效。
end