本教程概述并解释了贪婪算法,并附有易于理解的代码和信息图表。你很快就会成为专业人士!
1. 前缀树
1.1 说明
前缀树与贪心算法有关;先不谈关系。
前缀树又称Trie、词搜索树等,是一种用于存储大量字符串的树结构。
其特点是空间换时间,使用字符串的公共前缀来减少查询时间的开销,以达到提高效率的目的。
1.2 经典前缀树
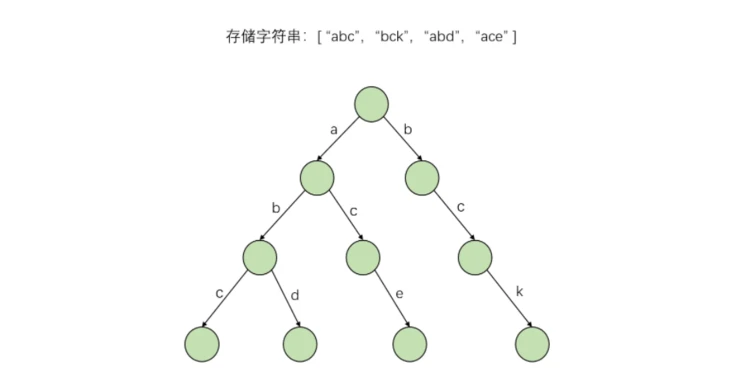
经典前缀树的字符存储在路径上,每个节点都没有数据。
1.3 代码定义
1.3.1 节点结构
为了用 Trie 实现某些功能,实际上在节点中添加了一些数据项。
public class Node { // 构建前缀树时,该节点被到达过多少次 int pass; // 该节点是否是某个字符串的结尾节点,如果是,是多少个字符串的结尾节点 int end; // 各个字符的通路 Node[] nexts; // HashMap<Char, Node> -- TreeMap<Char, Node> public Node() { this.pass = 0; this.end = 0; // 假如词典中只有'a'-'z',那么next[26],对应下标0-25 // 通过下级是否有节点判断是否有路 // nexts[0]==null表示下级没有存储'a'的路 // nexts[0]!=null表示下级有存储'a'的路 nexts = new Node[26]; } }
注意:在前缀树中,每个节点的向下路径是通过挂载从属节点来实现的。在代码的实现中,通过数组的下标对可以挂载的下级节点进行编号,这样就可以通过下标和字符的一一对应来实现每一方“承载”不同的字符信息。
如果需要存储包含多种类型字符的字符串,则不宜使用数组来存储挂载的节点。比如Java支持超过60000个字符,所以不能从一开始就打开一个容量为60000的数组。因此,当字符类型较多时,可以用哈希表代替数组来存储挂载的节点,哈希表的key也可以与字符一一对应。
用数组替换哈希表后,算法整体不会发生变化,Coding的细节会发生变化。
但是,使用哈希表存储后,路径是无序的。如果你想让路径像数组存储一样组织起来,你可以使用有序表而不是哈希表存储。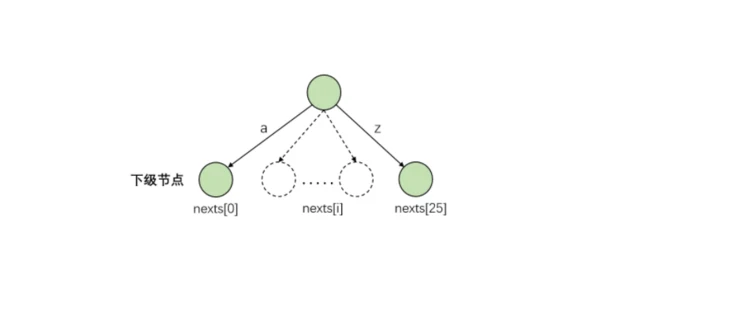
使用已添加数据项的节点再次存储上述字符串: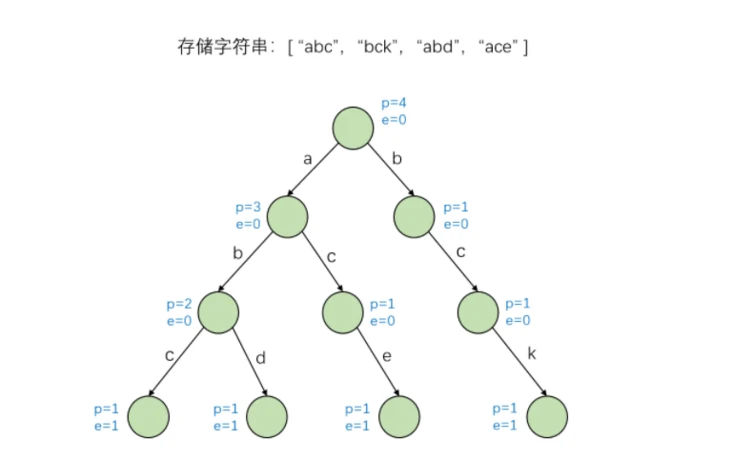
通过添加带有数据项的节点,我们可以轻松解决很多问题,例如:
我如何知道字符串“bck”是否存储在 Trie 中?
答:从根节点开始,检查有没有办法'b'?是的; 有没有办法'c'呢?是的; 还有另一种方法可以“k”吗?是的; 然后检查'k'路径末尾的节点的末尾,如果end != 0,则存储“bck”,如果end = 0,则不存储“bck”。
我如何知道存储在 Trie 中的所有字符串中有多少字符串以“ab”为前缀?
答:从根节点开始,检查有没有办法到'a'?是的; 有没有办法'b'呢?是的; 然后检查'b'路径末尾节点的pass。pass 的值是以“ab”为前缀的字符串数。
你怎么知道Trie中存储了多少个字符串?
答:只要检查根节点的pass即可。
如何知道 Trie 中存储了多少个空字符串?
答:只需检查根节点的末尾即可。
通过以上问题我们可以发现,利用节点类型的数据项信息,可以方便的查询Trie中存储的每个字符串,而且查询字符串的成本很低,只需要遍历其中的字符数即可要查询的字符串的次数就足够了。
1.3.2 树状结构
public class Trie { // 根节点 private Node root; public Trie() { this.root = new Node(); } // 相关操作 ... }
1.4 基本操作
1.4.1 添加字符串
思路:从根节点开始,沿途节点的pass加1,字符串末尾的节点加1。
代码:
public void insert(String word) { if (word == null) { return ; } char[] charSequence = word.toCharArray(); // 字符串起始节点为根节点 Node cur = this.root; cur.pass ++; for (int i = 0; i < charSequence.length; i ++) { int index = charSequence[i] - 'a'; // 该字符对应节点如果没有挂载就挂载上 if (cur.nexts[index] == null) { cur.nexts[index] = new Node(); } // 向下遍历 cur = cur.nexts[index]; cur.pass ++; } // 记录字符串结尾节点 cur.end ++; }
注意:添加每个字符串必须从根开始,这意味着每个字符串都以空字符串为前缀。
1.4.2 删除字符串
思路:如果字符串存在,从根节点开始,沿途节点的pass减1,字符串末尾的节点减1。
代码:
public void delete(String word) { // 判断是否存储该单词 if (word == null || search(word) == 0) { return ; } char[] charSequence = word.toCharArray(); Node cur = this.root; cur.pass --; for (int i = 0; i < charSequence.length; i ++) { int index = charSequence[i] - 'a'; // 当前节点的下级节点在更新数据后pass为0,意味这没有没有任何一个字符串还通过该节点 if (-- cur.nexts[index].pass == 0) { // 释放掉下级路径的所有节点 cur.nexts[index] = null; return ; } cur = cur.nexts[index]; } cur.end --; }
注意:如果Trie中只有一个目标字符串,修改节点数据后,需要释放所有冗余节点。由于Java中的自动垃圾回收,当我们第一次遍历一个节点的pass为0时,我们可以直接将其设置为null,然后该节点的所有下级节点都会被自动回收。如果是用C++实现,那么就需要遍历到最后,沿途回溯的时候,调用析构函数手动释放节点。
1.4.3 查询字符串
思路:如果字符串存在,则查询字符串末尾的节点。
代码:
// 查询word这个单词被存储的次数 public int search(String word) { if (word == null) { return 0; } char[] charSequence = word.toCharArray(); Node cur = this.root; // 只遍历Trie,不更新数据 for (int i = 0; i < charSequence.length; i ++) { int index = charSequence[i] - 'a'; // 如果没有挂载节点,说明没有存该字符串 if (cur.nexts[index] == null) { return 0; } cur = cur.nexts[index]; } // 返回字符串末尾节点的end return cur.end; }
1.4.4 查询前缀
思路:如果字符串存在,则查询前缀字符串末尾节点的pass。
代码:
// Trie存储的字符串中,前缀是pre的字符串个数 public int preFixNumber(String pre) { if (pre == null) { return 0; } char[] charSequence = pre.toCharArray(); Node cur = this.root; // 只遍历Trie,不更新数据 for (int i = 0; i < charSequence.length; i ++) { int index = charSequence[i] - 'a'; // 如果没有挂载节点,说明没有字符串以该子串作为前缀 if (cur.nexts[index] == null) { return 0; } cur = cur.nexts[index]; } // 返回pre子串末尾节点的pass return cur.pass; }
2.贪心算法
2.1 概念
在一定的标准下,优先考虑最符合标准的样本,最后考虑不符合标准的样本并最终得到答案的算法称为贪心算法。
也就是说,不考虑整体最优性,做出的是某种意义上的局部最优解。
2.2 说明
贪心算法其实是最常用的算法,代码实现也很短。
许多贪心算法只需要找到一个好的解决方案,而不是一个最优的解决方案。换句话说,对于大多数日常贪心算法来说,从局部最优到整体最优的过程是无法证明的,或者证明是错误的,因为有时候贪心是很主观的。但是我们接触到的贪心算法题目都是确定性的,可以找到全局最优解。这时候,贪心算法的考察就需要从局部最优到整体最优的证明。
本文不会展示证明过程,因为对于每个问题,其局部最优策略如何推导出全局最优的证明是不同的。如果每个贪心算法问题都被证明,面试过程中的时间是不够的。下面将介绍一个非常有用的技巧,这个技巧的前提是准备很多模板,但只需要准备一次。做好准备,以后做贪心算法题的时候,答题会又快又准,比做证明快很多。
2.3 会议问题
标题:
有些项目需要占用一个会议室进行演示,会议室不能同时容纳两个演示。给你所有的项目和每个项目的开始时间和结束时间,你会安排演讲的日程,要求会议室有最多的演讲。回到这个最讲道的会议。
分析:
贪婪策略 A:项目越早开始,就越早安排。
无法获得全局最优解。反例如下:
贪心策略B:项目工期越短,优先安排。
无法获得全局最优解。反例如下: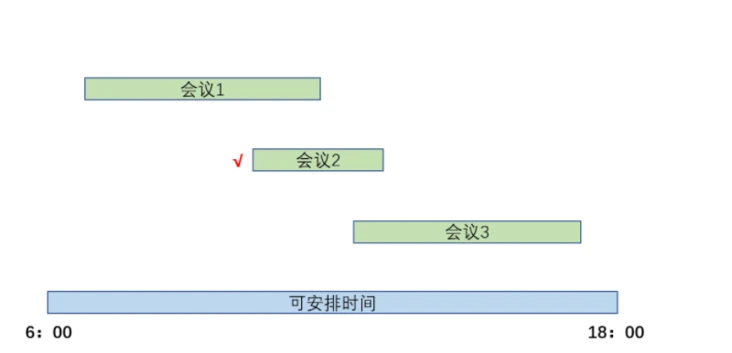
贪婪策略 C:先安排提前结束的项目。
可以得到全局最优解。
策略 A 的反例: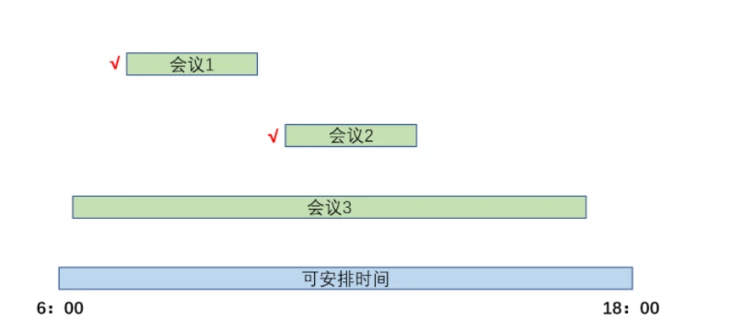
策略 B 的反例: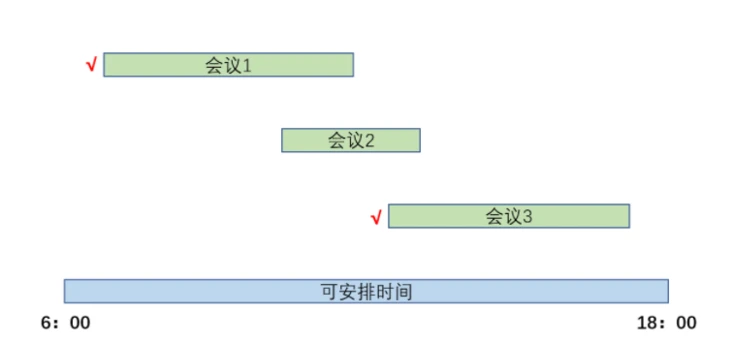
public class Solution { static class Program { // 项目开始时间 public int begin; // 项目结束时间 public int end; public Program(int begin, int end) { this.begin = begin; this.end = end; } } // 定义Program比较器,按照Program的结束时间来比较 static class ProgramComparator implements Comparator<Program> { @Override public int compare(Program program1, Program program2) { return program1.end - program2.end; } } public int arrangeProgram(Program[] programs, int currentTime) { if (programs == null || programs.length == 0) { return 0; } // 可以安排项目的场数 int number = 0; // 将Program数组按照结束时间早晚来排序,结束早的排前面 Arrays.sort(programs, new ProgramComparator()); for (int i = 0; i < programs.length; i ++) { // 如果当前时间还没到会议开始时间,安排会议 if (currentTime < programs[i].begin) { number ++; } // 当前时间来到会议结束 currentTime = programs[i].end; } return number; } }
2.4 问题解决程序
看完2.3,肯定会有问题。为什么贪心策略C能找到最优解?不用担心为什么贪心策略C是对的,就是靠瞎眼和熟练瞎眼。
在与贪心算法相关的问题中,你总会有几种贪心策略。如果能用反例来推翻一些贪婪的策略,那就再好不过了。但是如果有几个你觉得比较靠谱的贪心策略,又不能举反例,那你需要用严格的数学证明吗?你可以私下做问题,但不能在面试中!
贪心策略的数学证明每道题都不一样,因为每道题都有自己的事,证明的方法也是不可思议的,考验的是数学能力。
那么,你如何验证你的贪婪策略是正确的呢?对数。
解决问题的套路:
要实现不依赖贪婪策略的解决方案X,可以使用最暴力的尝试。
大脑弥补了贪婪策略A,贪婪策略B,贪婪策略C......
用解X和对数来验证每个贪心策略,并用实验来知道哪个贪心策略是正确的。
不要担心贪婪策略的证明。
准备:
为蛮力尝试或完整的代码模板阵列做好准备。
准备对数代码模板。
2.5 面试情况
贪心算法题不灵活,面试比例相对较低。大约有五个问题,最多一个问题。
首先,贪心算法的问题无法考验Coding的功力,因为代码极其简单。
其次,贪心算法的问题没有判别度。只要找到贪心策略,都是一样的,只有0和1的区别。
3. 对数
3.1 说明
对数非常好用,可以帮你解决很多问题。
假设要测试方法A,但是同样的问题可以用很多策略来实现。如果不考虑事件的复杂性,我可以写一个暴力尝试的解决方案(例如,列出所有排列组合)。我们称这种方法不追求时间复杂度的优劣,但非常周到且易于编写。方法 B. 为什么要测试方法 A?因为可能很难想到方法A或者时间复杂度比较低。
以前,每次考试都需要依赖在线OJ吗?如果每个话题都必须依赖OJ,那么遇到陌生的话题还需要在OJ上找吗?如果你找不到它,你不练习一下吗?其次,网上的测试数据是人所想的,所以他在准备测试用例的时候,会不会让你的代码跑错了,反而不让你通过的情况?你已经通过了,但是你能保证你的代码是正确的吗?不一定,这时候需要对数法,对数法万无一失。
3.2 实施
实现一个随机样本生成器,可以控制样本大小,可以控制测试次数,可以生成随机数据。生成的数据在方法A中运行得到res1,然后在方法B中运行得到res2。检查 res1 和 res2 是否一致。您测量数以万计的组,然后更改样本大小。当发现 res1 和 res2 不一致时,要么方法 A 错误,要么方法 B 错误,或者两者都错误。
Java中随机数的实现:
// [0,1)上所有小数,等概率返回一个,double类型 random = Math.random(); // [0,N)上所有小数,等概率返回一个,double类型 random = N * Math.random(); // [0,N-1]上所有整数,等概率返回一个,int类型 random = (int) (N * Math.random());
通过生成随机数,可以使测试样本的任何部分随机化,例如:样本大小、测试次数、测试数据。
每个topic的业务逻辑不同,对数的实现也不同。您需要根据实际情况来实施。
4. 面试问题
4.1 求中位数
标题:
用户使用一个结构体将N个数字一一存储,并要求随时可以找到当前存储在该结构体中的所有数字的中位数。
规则:奇数位的中位数为中间位,偶数位的中位数为中间两位数的平均值。
分析:
本课题与贪心算法无关,是研究反应堆应用的经典课题。
因为在贪心算法中广泛使用了堆,所以可以通过本专题熟悉堆的操作。
该算法的时间复杂度非常低,因为堆上的所有操作都是 O(logN)。
过程是:
准备一个大根桩和一个小根桩。
第一个数字进入大根桩。
进入固定迭代过程:
当前输入的数字cur <=大根桩的顶号,如果是,则cur进入大根桩;如果没有,则cur进入小根桩。
观察大根桩和小根桩的大小。如果较大的比较小的多 2 个,则较大的顶部会弹出另一个。
存储所有数字后停止迭代。
较小的 N/2 数在大根桩中,较大的 N/2 数在小根桩中。可以通过使用两堆的最高数字找到中位数。
代码:
public class Solution { // 大根堆比较器 static class BigComparator implements Comparator<Integer> { @Override public int compare(Integer num1, Integer num2) { return num2 - num1; } } public static int findMedian(int[] input) { if (input == null || input.length == 0) { return 0; } PriorityQueue<Integer> bigRootHeap = new PriorityQueue<>(new BigComparator()); PriorityQueue<Integer> smallRootHeap = new PriorityQueue<>(); // 第一个数先入大根堆 bigRootHeap.add(input[0]); for (int i = 1; i < input.length; i ++) { if (input[i] <= bigRootHeap.peek()) { bigRootHeap.add(input[i]); } else { smallRootHeap.add(input[i]); } if (Math.abs(bigRootHeap.size() - smallRootHeap.size()) == 2) { if (bigRootHeap.size() > smallRootHeap.size()) { smallRootHeap.add(bigRootHeap.poll()); } else { bigRootHeap.add(smallRootHeap.poll()); } } } // 判断输入数字个数是奇数还是偶数 if (input.length % 2 != 0) { return smallRootHeap.peek(); } return (bigRootHeap.peek() + smallRootHeap.peek()) / 2; } }
4.2 金条问题
标题:
将金条切成两半需要与长度相同的铜板。例如,一条长度为 20 的条带无论切成两半要花费 20 块铜板。
一群人要分整条金条,怎么分最经济的铜板?
例如,给定一个数组[10, 20, 30],共代表三个人,整个金条的长度为10 + 20 + 30 = 60。金条分为三部分:10、20、和30.如果把60长的金条分成10和50,成本是60;然后将50根长的金条分成20根和30根,花费50;一共需要110块铜板。
但是如果把60长的金条分成30和30,就要60;然后将30根长的金条分成10根和20根,花费30;总共花费了90块铜板。
输入一个数组并返回拆分的最小成本。
分析:
这个问题是经典的霍夫曼编码问题。
过程是:
将数组中的所有元素放入小根堆
迭代固定过程:
从小根桩的顶部弹出两个节点并将它们组合成新节点以构建霍夫曼树。
新节点被放回小根堆中。
停止迭代,直到小根堆中只有一个节点。
代码:
public int leastMoney(int[] parts) { PriorityQueue<Integer> smallRootHeap = new PriorityQueue<>(); // 需要花费的最少钱数 int money = 0; // 将节点全部放入小根堆 for (int i = 0; i < parts.length; i ++) { smallRootHeap.add(parts[i]); } // 直到堆中只有一个节点时停止 while (smallRootHeap.size() != 1) { // 每次堆顶弹两个算累加和 int cur = smallRootHeap.poll() + smallRootHeap.poll(); money += cur; // 累加和的新节点入堆 smallRootHeap.add(cur); } return money; }
4.3 项目规划问题
标题:
你的团队收到了一些项目,每个项目都会有成本和利润。由于你的团队人很少,你只能按顺序做项目。假设您团队目前的可支配资金为M个,最多只能做K个项目,那么最终最大的可支配资金是多少?
注意:casts[i]、progress[i]、M 和 K 都是正数。
分析:
过程是:
建立一个小根桩和一个大根桩。小根桩的分类标准是成本,大根桩的分类标准是利润。
将所有物品放入小根堆中。
进入固定迭代过程:
小根堆将所有成本小于或等于 M 的物品弹出到大根堆中。
最赚钱的项目出现了。
M加上刚刚完成的项目的利润。
停止迭代,直到完成的项目数为 K。
代码:
public class Solution { static class Project { int cost; int profit; public Project(int cost, int profit) { this.cost = cost; this.profit = profit; } } static class minCostComparator implements Comparator<Project> { @Override public int compare(Project p1, Project p2) { return p1.cost - p2.cost; } } static class maxProfitComparator implements Comparator<Project> { @Override public int compare(Project p1, Project p2) { return p2.profit - p1.profit; } } public static int findMaximumFund(int M, int K, int[] costs, int[] profits) { if (M == 0 || K == 0) { return 0; } // 通过花费构建小根堆 PriorityQueue<Project> costSmallRootHeap = new PriorityQueue<>(new minCostComparator()); // 通过利润构建大根堆 PriorityQueue<Project> profitBigRootHeap = new PriorityQueue<>(new maxProfitComparator()); // 将所有项目全部放入小根堆 for (int i = 0; i < costs.length; i ++) { costSmallRootHeap.add(new Project(costs[i], profits[i])); } // 一共只能做K个项目 for (int i = 0; i < K; i ++) { // 将小根堆中当前可以做的项目放入大根堆 while (!costSmallRootHeap.isEmpty() && costSmallRootHeap.peek().cost <= M) { profitBigRootHeap.add(costSmallRootHeap.poll()); } // 没有可以做的项目 if (profitBigRootHeap.isEmpty()) { return M; } // 从大根堆中选选取利润最大的做 Project cur = profitBigRootHeap.poll(); M += cur.profit; } return M; } }
4.4 N皇后问题
标题:
N皇后问题是指在N*N棋盘上放置N个皇后,要求任意两个皇后在不同的行、不同的列,并且不在同一对角线上。
给定一个整数 n,返回皇后 n 有多少种方式。
例如:
n=1,返回 1。
n=2或3,返回0。(2皇后和3皇后的问题不管怎么放都行不通)
n=8,返回 92。
分析:
这个问题是一个经典问题,最优解非常复杂,是一个有后遗症的动态规划问题。
如果你不是在写论文,面试过程中最好的解决办法就是采用深度优先的思路,把皇后依次放在每一行,用暴力递归去尝试每一列的每一种可能。
这个方案的时间复杂度指数还是很高的。
因为第一行有N个选择,第二行有N个选择,第三行有N个选择,...,总共有N行,所以时间复杂度是O(N^N)。
假设,record[0] = 2,record[1] = 4,当深度优先遍历达到i = 2时,图中第三行有3个合理的Queen放置位置,然后这三个位置依次depthwise优先遍历,并一次又一次地开始。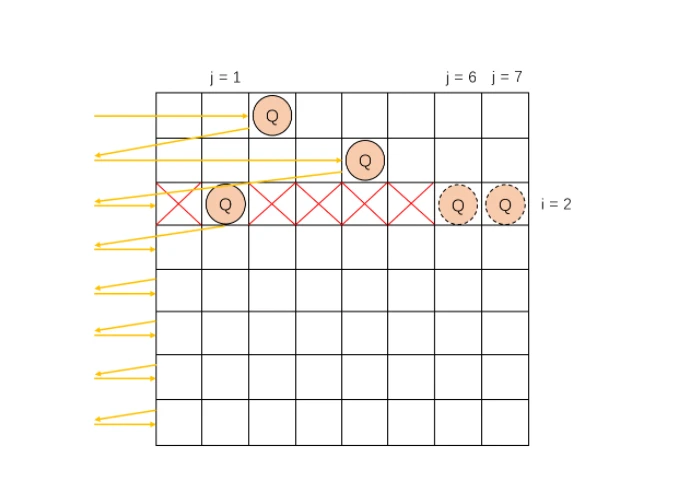
代码:
public static int nQueen(int n) { if (n < 1) { return 0; } int[] record = new int[n]; // 从第0行开始 return process(0, n, record); } /** * @param i 当前遍历第几行 * @param n 一共多少行 * @param record [0,i-1]行已经摆放的Queen的位置,record[1]=2表示第1行第2列已摆放一个Queen * @return n行n列棋盘中摆n个Queen的合理的摆法总数 */ public static int process(int i, int n, int[] record) { // 遍历到最后一行的下一行结束递归,说明这条摆放方案合理 if (i == n) { return 1; } // 记录[i,n-1]行合理的摆法总数 int result = 0; // 尝试第i行的[0,n-1]列进行深度优先遍历 for (int j = 0; j < n; j ++) { // 判断在第i行第j列的位置上是否能放Queen if (isValid(i, j, record)) { record[i] = j; // 遍历下一行 result += process(i + 1, n, record); } } return result; } // 检查第i行第j列能不能放Queen public static boolean isValid(int i, int j, int[] record) { // 遍历[0,i-1]行放过的所有Queen,检查是否和当前位置有冲突 for (int k = 0; k < i; k ++) { // 判断是否是同一列或者是否共斜线(不可能共行) if (record[k] == j || Math.abs(k - i) == Math.abs(record[k] - j)) { return false; } } return true; }
4.5 N皇后问题(优化)
N-queen问题虽然不能从时间复杂度上优化,但是可以从常数上优化,而且还有很多优化。
可以说时间复杂度还是这样的时间复杂度,但是我在实现过程中可以在恒定时间内把它弄的很低。
它有多低?例如,对于14皇后问题,4.4的解将运行5s,4.5优化的解将运行0.2s。对于15皇后问题,4.4解运行1分钟,4.5优化解运行1.5s。
分析:
使用位操作来加速。位算术加速是一种非常常用的技术,建议掌握它。
由于使用了按位运算,所以与代码中变量的存储形式有关。这段代码中变量的类型是一个32位的int,所以不能解决32个皇后或更多的问题。
如果要解决超过32个皇后的问题,可以将参数类型改为long。
代码:
public static int nQueen(int n) { if (n < 1 || n > 32) { return 0; } int limit = n == 32 ? -1 : (1 << n) - 1; return process(limit, 0, 0, 0); } /** * @param n 一共多少行 * @param colLim 列的限制,1的位置不能放皇后,0的位置可以 * @param leftDiaLim 左斜线的限制,1的位置不能放皇后,0的位置可以 * @param rightDiaLim 右斜线的限制,1的位置不能放皇后,0的位置可以 * @return n行n列棋盘中摆n个Queen的合理的摆法总数 */ public static int process(int n, int colLim, int leftDiaLim, int rightDiaLim) { // 皇后是否填满 if (colLim == n) { return 1; } int mostRightOne = 0; // 所有后选皇后的列都在pos的位信息上 int pos = n & (~ (colLim | leftDiaLim | rightDiaLim)); int res = 0; while (pos != 0) { // 提取出候选皇后中最右侧的1 mostRightOne = pos & (~ pos + 1); pos = pos - mostRightOne; // 更新限制,进入递归 res += process(n, colLim | mostRightOne, (leftDiaLim | mostRightOne) << 1, (rightDiaLim | mostRightOne) >>> 1); } return res; }
获取更多免费资料加群:3907814