# encoding=utf-8
import json
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import pylab as pl
from numpy.distutils.system_info import agg2_info
def get_counts(sequenue):
counts = {}
for x in sequenue:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts
def TopCouns(count_dic, n = 10):
value_key_pair = [(count, tz) for tz, count in count_dic.items()]
value_key_pair.sort()
return value_key_pair[-n:]
path = 'test.text'
records = [json.loads(line) for line in open(path)]
# print(records[0])
# print(records[0]['tz'])
time_zones = [rec['tz'] for rec in records if 'tz' in rec]
# print(time_zones[0])
counts = get_counts(time_zones)
tz_sorted = TopCouns(counts)
# print(tz_sorted)
frame = DataFrame(records)
tz_countsByFrame = frame['tz'].value_counts()
# print(tz_countsByFrame[:10])
clean_tz = frame['tz'].fillna('Missing')
clean_tz[clean_tz == ''] = 'Unknown'
tz_countsByFrame = clean_tz.value_counts()
# pl.plot(tz_countsByFrame[:10] , kind = 'barh', rot = 0)
# tz_countsByFrame[:10].plot(kind = 'barh', rot = 0)
result = Series([x.split()[0] for x in frame.a.dropna()])
print(result[:5])
cframe = frame[frame.a.notnull()]
operating_system = np.where(cframe['a'].str.contains('Windows'), 'Windows', 'Not Windows')
by_tz_os = cframe.groupby(['tz', operating_system])
agg_counts = by_tz_os.size().unstack().fillna(0)
indexer = agg_counts.sum(1).argsort()
count_subset = agg_counts.take(indexer)[-10:]
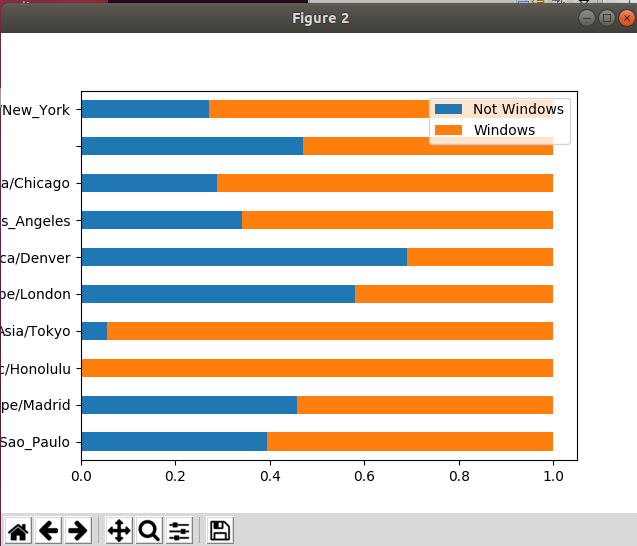
count_subset.plot(kind = 'barh', stacked = True)
normed_subset = count_subset.div(count_subset.sum(1), axis = 0)
normed_subset.plot(kind = 'barh', stacked = True)
pl.show()