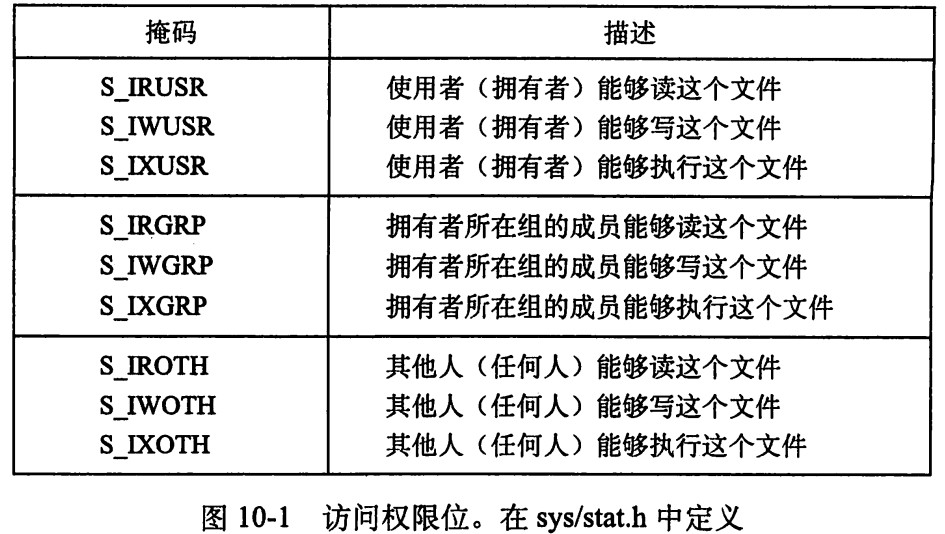
第十章 程序间的交互和通信
- 输入/输出(I/O)是在主存和外部设备之间拷贝数据的过程。输入操作是从I/O设备拷贝数据到主存,而输出操作是从主存拷贝数据到I/O设备。
- 输入:从I/O拷贝到主存,输出:从主存拷贝到I/O
- Unix IO(系统级IO)虽然是低级别的,但是了解它有助于理解其他的系统概念;而且有时候你只能使用Unix IO,比如网络编程。
Unix中所有的IO都被模型化为文件,输入输出则用读写文件来操作。
10.1 Unix I/O
- 一个Unix文件就是一个M个字节的序列:B0,B1,...B(m-1),所有的I/O设备都被模型化为文件,而所有的输入和输出都被当做对相应文件的读和写来执行。
- 这种将设备优雅的映射为稳健的方式,允许Unix内核引出一个简单、低级的应用接口,称为Unix I/O,这使得所有的输入和输出都能以一种统一且一致的方式来执行:打开文件、改变当前文件中位置、读写文件、关闭文件。
10.2 打开关闭文件
- 打开文件:文件通过要求内核打开相应文件,来宣告他想要访问一个IO设备,内核会返回一个小的非负数,描述符,后续操作中标出文件。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename, int flags,mode_t mode);
-
返回:若成功则为新文件描述符,若出错为-1。
-
返回的描述符总是在进程中当前没有打开的最小描述符。
flags参数指明了进程打算如何访问这个文件:
- O_RDONLY:只读。
- O_WRONLY:只写。
- O_RDWR:可读可写。
- O_CREAT:如果文件不存在,就创建一个截断的空文件。
- O_TRUNC:如果文件已存在,就截断他。
- O_APPEND:在每次操作前,设置文件位置到文件的结尾处。
改变当前的文件位置:内核保存文件位置k,初始值为0,字节偏移量,通过seek设置k。
读写文件:应用程序检测k是否大于m(文件大小)来决定是否到了结尾,而在文件结尾并没有明确的EOF。
关闭文件:通知内核关闭文件,内核释放打开时创建的数据结构,释放描述符,放到描述符池中。
#include<unistd.h>
int close(int fd);
- 返回:若成功则为0,若出错则为-1。
- 不足值(short count):
EOF;从终端读取文本行;读写网络套接字。
读写磁盘文件不会遇到不足值。 - Rio(Robust IO):
无缓冲的输入输出:存储器和文件之间直接传送数据,网络操作时使用。
带换红的输入函数:线程安全。 - 软件构造领域的定义在软件构造领域,元数据被定义为:在程序中不是被加工的对象,而是通过其值的改变来改变程序的行为的数据。它在运行过程中起着以解释方式控制程序行为的作用。在程序的不同位置配置不同值的元数据,就可以得到与原来等价的程序行为。
- mode参数
10.3读和写文件
ssize_t read(int fd, void *buf, size_t n);//0 EOF,-1 错误,n实际传送的字节数。
ssize_t write(int fd, const void *buf, size_t n);// size_t是unsigned ssize_t有符号
/*ssize_t可以用来表示出错时必须返回的-1,但却使read值从4GB 减小到2GB*/
- read函数从描述符为fd的当前文件位置拷贝最多n个字节到存储器位置buf。返回值-1表示一个错误,而返回值0表示EOF。否则,返回值表示的是实际传送的字节数量。而write函数从存储器位置buf拷贝至多n个字节到描述符fd的当前文件位置。返回值要么为-1要么为写入的字节数目。
#include "csapp.h"
int main(void)
{
char c;
while(Read(STDIN_FILENO, &c, 1) != 0)
Write(STDOUT_FILENO, &c, 1);
exit(0);
}
- 关于在文件中定位使用的函数为lseek,在I/O库中使用的函数为fseek。(ps:size_t和ssize_t的区别,前者是unsigned int,而后者是int)
- 有些情况下,read和write传送的字节比应用程序要求的要少,出现这种情况的原因如下:
- 读时遇到EOF。此时read返回0来发出EOF信号。
- 从终端读文本行。如果打开文件是与终端相关联,那么每个read函数将以此传送一个文本行,返回的不足值等于文本行的大小。
- 读和写网络套接字。可能会出现阻塞现象。
实际上,除了EOF,在读磁盘文件时,将不会遇到不足值,而且在写磁盘文件时,也不会遇到不足值。然而,如果你想创建健壮的网络应用,就必须反复调用read和write处理不足值,直到所有需要的字节都传送完毕。
10.4用RIO包健壮地读写
- 这个包会处理上面的不足,RIO提供了方便、健壮和高效的I/O。提供了两类不同的函数:
无缓冲的输入输出函数 直接在存储器和文件之间传送数据,没有应用级缓冲,它们对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
带缓冲的输入函数
ssize_t rio_readn(int fd,void *usrbuf,size_t n);
ssize_t rio_writen(int fd,void *usrbuf,size_t n);
- 对同一个描述符,可以任意交错地调用rio_readn和rio_writen。一个问本行的末尾都有一个换行符,那么像读取一个文本中的行数怎么办,使用read读取换行符这个方法不是很妥当,可以调用一个包装函数(rio_readineb),它从一个内部读缓冲区拷贝一个文本行,当缓冲区为空时,会自动地调用read重新填满缓冲区。也就是说,这些函数都是缓冲区操作而言的。
10.5读取文件元数据(文件信息):
- 应用程序能够通过调用stat和fstat函数检索到关于文件的信息(有时也称为文件的元数据)
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *filename,struct stat *buf);
int fstat(int fd,struct stat *buf);
- 若成功,返回0,若出错则为-1.stat以一个文件名为输入,并且填充buf结构体。fstat函数只不过是以文件描述符而不是文件名作为输入。
struct stat {
#if defined(__ARMEB__)
unsigned short st_dev;
unsigned short __pad1;
#else
unsigned long st_dev;
#endif
unsigned long st_ino;
unsigned short st_mode;
unsigned short st_nlink;
unsigned short st_uid;
unsigned short st_gid;
#if defined(__ARMEB__)
unsigned short st_rdev;
unsigned short __pad2;
#else
unsigned long st_rdev;
#endif
unsigned long st_size;
unsigned long st_blksize;
unsigned long st_blocks;
unsigned long st_atime;
unsigned long st_atime_nsec;
unsigned long st_mtime;
unsigned long st_mtime_nsec;
unsigned long st_ctime;
unsigned long st_ctime_nsec;
unsigned long __unused4;
unsigned long __unused5;
};
- 其中st_size成员包含了文件的字节大小。st_mode为文件访问许可位。UNIX提供的宏指令根据st_mode成员来确定文件的类型:S_ISREG(),这是一个普通文件么;S_ISDIR(),这是一个目录文件么;S_ISSOCK()这是一个网络套接字么。使用一下这个函数
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int fd,size;
struct stat buf_stat;
memset(&buf_stat,0x00,sizeof(buf_stat));
fd=stat("stat.c",&buf_stat);
printf("%d
",(int)buf_stat.st_size);
return 0;
}
- Unix识别大量文件:普通文件(二进制或者文本);目录文件爱你(包含其他文件的信息);套接字(网络和其他进程通信)。
10.6共享文件
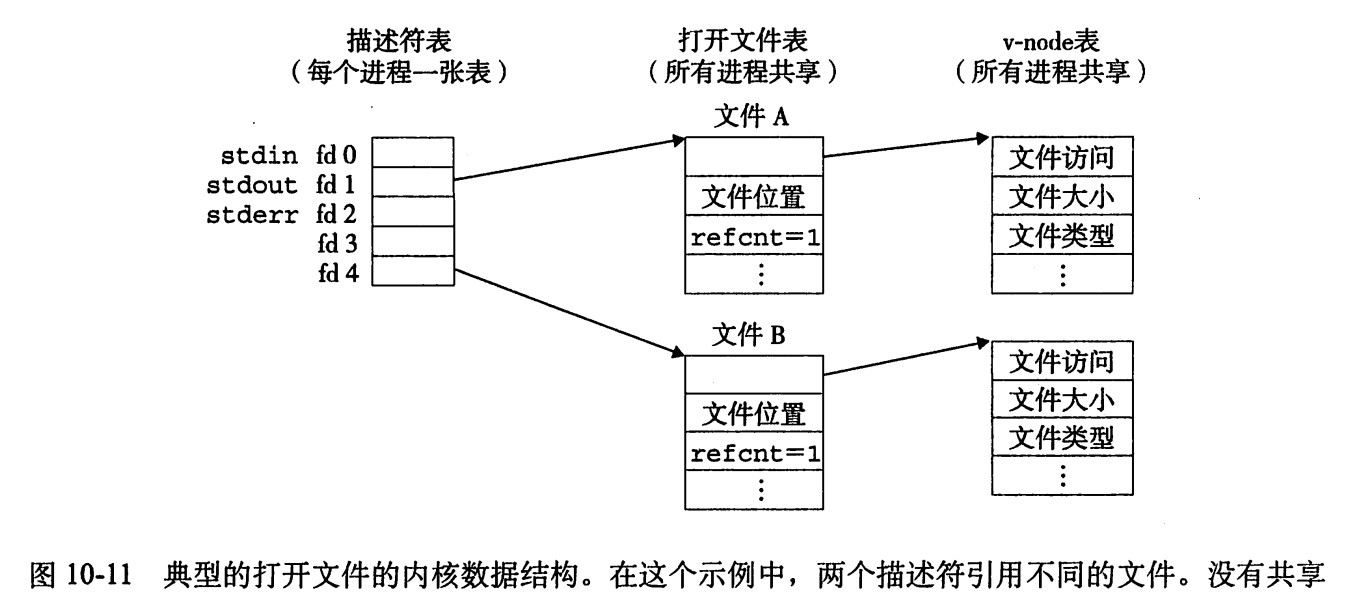
- 内核用三个相关的数据结构来表示打开的文件:
描述符表(descriptor table)每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个表项。 - 文件表(file table) 打开文件的描述符表项指向问价表中的一个表项。所有的进程共享这张表。每个文件表的表项组成包括由当前的文件位置、引用计数(既当前指向该表项的描述符表项数),以及一个指向v-node表中对应表项的指针。关闭一个描述符会减少相应的文件表表项中的应用计数。内核不会删除这个文件表表项,直到它的引用计数为零。
v-node表(v-node table)同文件表一样,所有的进程共享这张v-node表,每个表项包含stat结构中的大多数信息,包括st_mode和st_size成员。 - 描述符1和4通过不同的打开文件表表项来引用两个不同的文件。这是典型的情况,没有共享文件,并且每个描述符对应一个不同的文件。
- 多个描述符也可以通过不同的文件表表项来应用同一个文件。如果同一个文件被open两次,就会发生上面的情况。关键思想是每个描述符都有它自己的文件位置,所以对不同描述符的读操作可以从文件的不同位置获取数据。
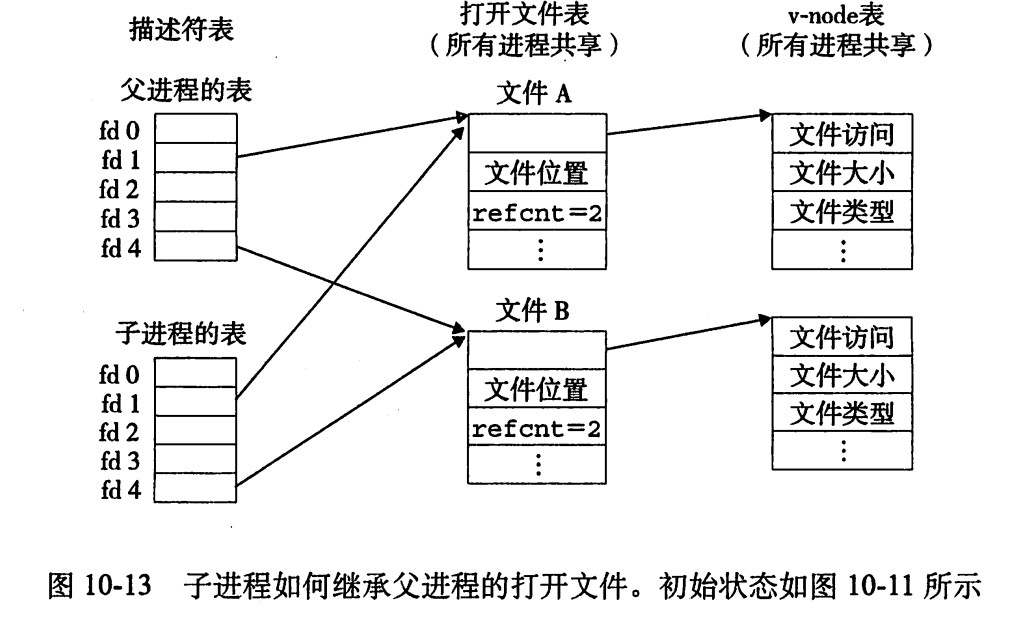
- 父子进程也是可以共享文件的,在调用fork()之前,父进程如第一张图,然后调用fork()之后,子进程有一个父进程描述符表的副本。父子进程共享相同的打开文件表集合,因此共享相同的文件位置。一个很重要的结果就是,在内核删除相应文件表表项之前,父子进程必须都关闭了他们的描述符。
10.7 I/O重定向
- I/O重定向:使用dup2函数
#include <unistd.h>
int dup2(int oidfd,int newfd);
-
返回:若成功则为非负的描述符,若出错则为-1
-
dup2函数拷贝描述符表表项oldfd到newfd,覆盖newfd以前的内容,如果newfd已经打开了,dup2会在拷贝之前关闭newfd。
10.8 标准I/O
- 标准I/O库(libc):高级输入输出函数
fopen/fclose:打开和关闭文件
fread/fwrite:读和写字节
fgets/fputs:读和写字符串
scanf/printf:复杂格式化的I/O函数
-
标准I/O库将一个打开的文件模型化为一个流,一个流就是一个指向FILE类型的结构指针。
-
每个程序开始时都有三个打开的流:
stdin:标准输入
stdout:标准输出
stderr:标准错误
- 类型为FILE的流是对文件描述符和流缓冲区的抽象,流缓冲区的目的:使开销较高的Unix I/O系统调用的数量尽可能的小。
代码托管情况
收获与思考
- 本周的学习内容比较少,但却并不简单,比较抽象,还是需要花费一定的时间去弄懂。通过近十周的学习,我们越来越接近于计算机系统的深层,因为哪怕是程序员都不见得能透彻理解这个系统,所以围绕这门课的学习还是有一点自豪的。以前总想,我编不出什么有价值的程序,我没有办法成为一个优秀的程序员,我不能靠这个吃饭,我的这个专业就白学了。现在想想,通过学习这门课,对计算机科学有了更深层次的了解,说大点,这直接影响到世界观构造。大多数人根本不会知道他们日常生活离不开的计算机如何工作,一部分程序员不知道他们简单的printf和scanf操作,系统I/O在后台到底怎么工作,而我们知道,有一种万物运行的智慧掌握在自己手中的快乐。好像扯远了。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/2 | 15/30 | |
| 第二周 | 56 /56 | 2/3 | 15/45 | |
| 第三周 | 89/145 | 1/4 | 20/65 | |
| 第五周 | 500/645 | 1/5 | 20/85 | |
| 第六周 | 150/795 | 1/6 | 20/105 | |
| 第七周 | 124/919 | 1/7 | 20/125 | |
| 第八周 | 0/919 | 1/8 | 15/140 | |
| 第九周 | 98/1017 | 1/9 | 15/155 |