checkpoint原理机制
当RDD使用cache机制从内存中读取数据,如果数据没有读到,会使用checkpoint机制读取数据。此时如果没有checkpoint机制,那么就需要找到父RDD重新计算数据了,因此checkpoint是个很重要的的容错机制。checkpoint就是对于一个RDDchain(链),如果后面需要反复使用某些中间结果RDD,可能因为一些故障导致该中间数据丢失,那么就可以针对该RDD启动checkpoint机制,使用checkpoint首先需要调用sparkContext的setCheckpoint方法,设置一个容错文件系统目录,比如HDFS,然后对RDD调用checkpoint方法。之后再RDD所处的job运行结束后,会启动一个单独的job来将checkpoint过的数据写入之前设置的文件系统持久化,进行高可用。后面的计算使用该RDD时,如果数据丢了,但是还是可以从他的checkpoint中读取数据,不需要重新计算

checkpoint和持久化的区别:
- 持久化只是将数据保存在BlockManager中,而RDD的lineage是不变的。但是checkpoint执行完后,RDD已经没有之前所谓的依赖RDD了,而只有一个强行为其设置的checkpointRDD,RDD的lineage改变了。
- 持久化的数据丢失可能性更大,磁盘、内存都可能会存在数据丢失的情况,因为磁盘内存都有可能被清理。但是checkpoint的数据通常是存储在如HDFS等容错、高可用的文件系统,数据丢失可能性较小。
- 注:默认情况下,如果某个RDD没有持久化,但是设置了checkpoint,会存在问题,本来这个job都执行结束了,但是由于中间RDD没有持久化,checkpoint job想要将RDD的数据写入外部文件系统的话,需要全部重新计算一次,再将计算出来的RDD数据checkpoint到外部文件系统。所以,建议对checkpoint()的RDD使用 persist(StorageLevel.DISK_ONLY),该RDD计算之后,就直接持久化到磁盘上。后面进行checkpoint操作时就可以直接从磁盘上读取RDD的数据,并checkpoint到外部系统
checkpoint代码
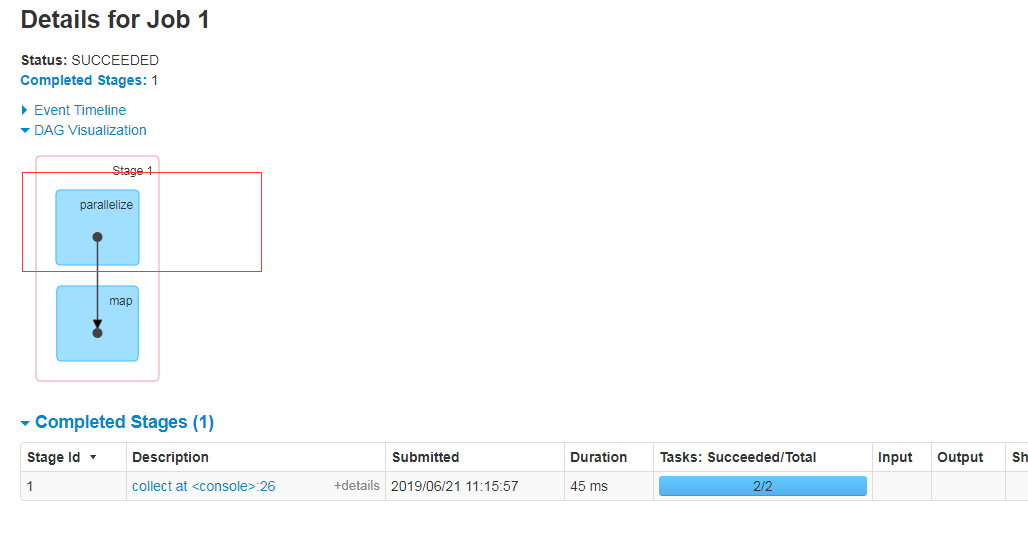
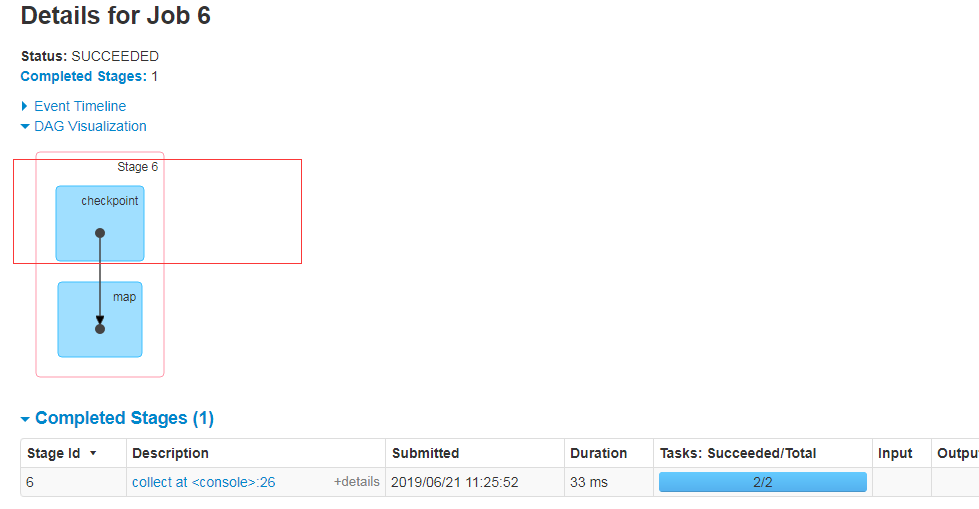
scala> sc.setCheckpointDir("hdfs://linux01:8020/checkpoint") scala> val ch1=sc.parallelize(1 to 2) ch1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at <console>:24 scala> val ch2 = ch1.map(_.toString+"["+System.currentTimeMillis+"]") ch2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at map at <console>:26 scala> val ch3 = ch1.map(_.toString+"["+System.currentTimeMillis+"]") ch3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at map at <console>:26 scala> ch3.checkpoint scala> ch2.collect res10: Array[String] = Array(1[1546695226909], 2[1546695226909]) scala> ch2.collect res11: Array[String] = Array(1[1546695231735], 2[1546695231736]) scala> ch3.collect res12: Array[String] = Array(1[1546695237730], 2[1546695237728]) scala> ch3.collect res13: Array[String] = Array(1[1546695237805], 2[1546695237800]) scala> ch3.collect res14: Array[String] = Array(1[1546695237805], 2[1546695237800]) scala> ch3.collect res15: Array[String] = Array(1[1546695237805], 2[1546695237800]) scala>
键值对RDD数据分区
Spark目前 可以 使用HashPatition和RangPatition进行 分区 ,用户也可以自定义分区方法,Hash分区为 当前 默认分区 ,Spark中分区器直接决定了RDD中分区的 个数 、RDD中 的每条 数据经过shuffle过程属于哪个分区和Reduce的个数
但是在这里,HashPatition有一个弊端,就是会导致数据倾斜,因为Hash的本质是除留取余法进行存储,所以就会产生这种偶然性,导致大量偶然的数据进来之后会让其中一个线程被挤爆,而其他线程占用的很少
所以,我们更倾向使用RangPatition,这种分区方法采用了水塘抽样随机算法进行数据的存储,可以让数据平均的存储到每一个分区中
注意:
- 只有K-V类型的RDD才有分区,非K-V类型的RDD分区的值就是None
- 每个RDD分区ID范围:0~numPatitions-1,决定这个值是属于哪个分区
- 当我们自己想制造一个分区方法的时候,只需要继承Patitioner这个抽象类就可以了
- 具体代码
import org.apache.spark.{Partitioner, SparkConf, SparkContext} class CustomerPartitioner(numPartition:Int) extends Partitioner{ // 返回分区的总数 override def numPartitions: Int = { numPartition } // 根据传入的key返回分区的索引 override def getPartition(key: Any): Int = { key.toString.toInt % numPartition } } object CustomerPartitioner{ def main(args: Array[String]): Unit = { val sparkConf=new SparkConf().setAppName("Partition").setMaster("local[*]") val sc = new SparkContext(sparkConf) val rdd = sc.makeRDD(0 to 10,1).zipWithIndex()//把下标拉到一起 print(rdd.mapPartitionsWithIndex((index,items)=>Iterator(index+":"+items.mkString(","))).collect()) val rdd2 = rdd.partitionBy(new CustomerPartitioner(5)) print(rdd2.mapPartitionsWithIndex((index,items)=>Iterator(index+":"+items.mkString(","))).collect()) sc.stop() } }
参考博客原文:
https://blog.csdn.net/qq_41936805/article/details/85527417
https://blog.csdn.net/qq_41455420/article/details/79462401
https://blog.csdn.net/ymcz1987/article/details/79564919