WC案例
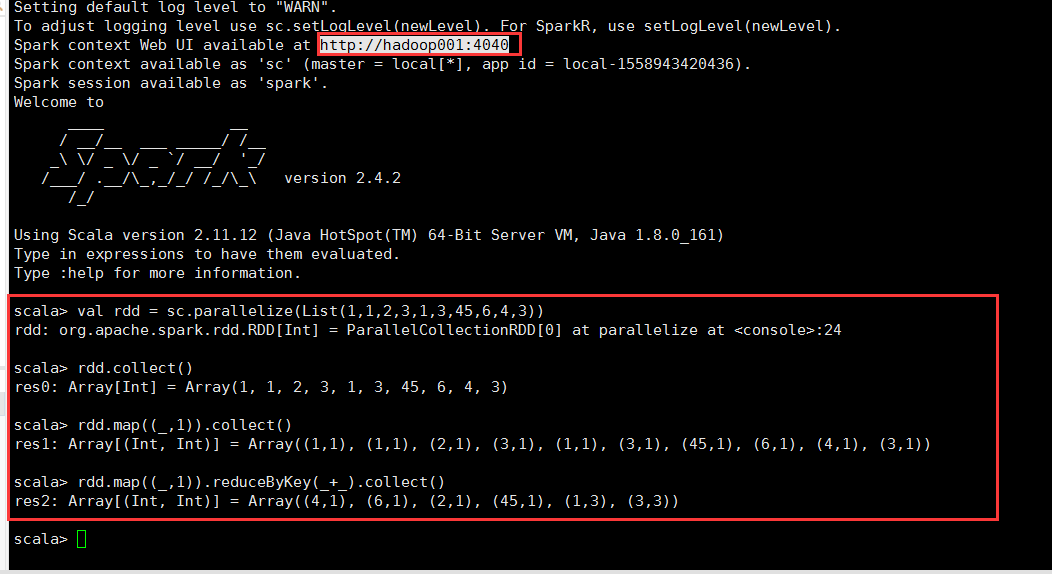
scala> val rdd = sc.parallelize(List(1,1,2,3,1,3,45,6,4,3)) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> rdd.collect() res0: Array[Int] = Array(1, 1, 2, 3, 1, 3, 45, 6, 4, 3) scala> rdd.map((_,1)).collect() res1: Array[(Int, Int)] = Array((1,1), (1,1), (2,1), (3,1), (1,1), (3,1), (45,1), (6,1), (4,1), (3,1)) scala> rdd.map((_,1)).reduceByKey(_+_).collect() res2: Array[(Int, Int)] = Array((4,1), (6,1), (2,1), (45,1), (1,3), (3,3)) scala>
-
查看http://hadoop001:4040的web界面

从Job_id 可以看出,一个WC一共有3个job发生,点击第三个job(即Job_id=2),我们可以看到job的DAG导向图
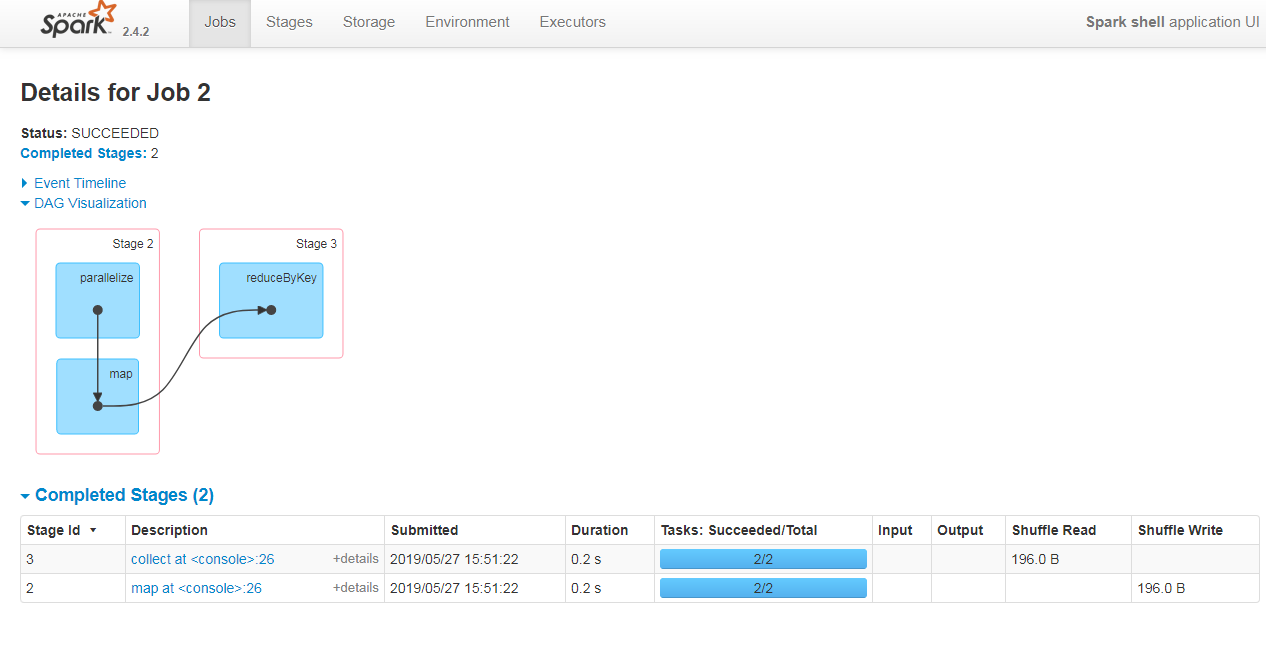
- 从DAG图中可以看出,一共有2个stage,因为reduceByKey算子会产生shuffle,所以会切割出新的stage(遇到shuffle就会切割stage),同样repatition也会产生shuffle,task数是每个stage的rdd的分区的和
持久数据(persisit/catch)
- spark core的catch()调用的是存储级别为MEMORY_ONLY的persist方法
- persisit()方法是lazy的,但是释放缓存数据的unpersisit()方法是eager的
- 详细内容请看笔者的另一篇博客:https://www.cnblogs.com/xuziyu/p/10914701.html
宽窄依赖
- 定义
宽依赖(Wide):父RDD的patition多次被子RDD的patition使用即为宽依赖
窄依赖(Narrow):父RDD的patition只能被子RDD的patition使用一次
- 产生宽窄依赖的算子
窄依赖的算子有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的算子有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
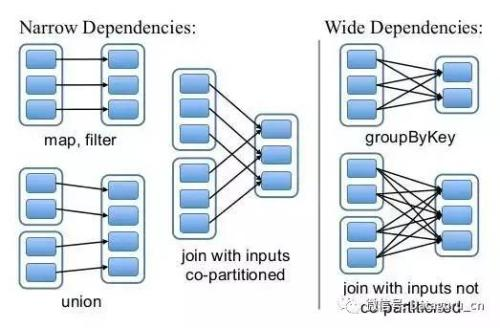

从shuffle角度来讲,有shuffle发生,才会有宽依赖产生,所以宽依赖必然有shuffle过程,而shuffle是新stage产生的标志,因此可以说spark是根据宽窄依赖来划分stage的。
但是并不是所有的shuffle都会有宽依赖产生,比如join算子(右图)
宽窄依赖的优化特点
- 宽依赖往往对应着shuffle操作,需要在运行的过程中将同一个父RDD的分区传入不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个字RDD分区中,通常可以在一个节点内完成转换。
- 当RDD分区数据丢失的时候(某个节点故障),spark会对数据进行重新计算。(1)重算的过程中,对于窄依赖来说,由于父RDD的一个分区只对应一个子RDD的分区,这样只需要重新计算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的(2)而对于宽依赖来说,重新计算的父RDD分区对应着多个子RDD分区,这样实际上父RDD中只有一部分的数据是被用于回复丢失数据的,另一部分对应子RDD的其他未丢分区,这就造就了多余计算,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
eg:
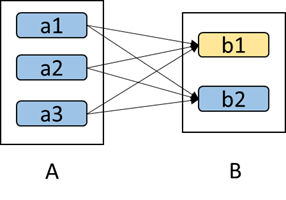
如上图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
容错性
- 宽依赖:如果一个RDD出错,那么可以从它的所有父RDD重新计算所得
- 窄依赖:如果一个RDD仅有一个父RDD(即窄依赖),那么这种重新计算的代价会非常小。
为了减小重新计算的代价,一般在产生宽依赖的位置,且分区被多次使用的情况下,会考虑缓存,物化到磁盘上,以备后边使用
键值对(key-value pairs)
RDD中数据结构可以是各种各样的,但是最常用的是kv结构,如groupByKey、reduceByKey等操作都是要求RDD的数据是KV结构,故scala中若元素的结构为Tuplue2,则RDD会隐式转换为PairRDDFunctions,非常方便。即groupByKey、reduceByKey等是PairRDDFunctions的方法,而不是RDD类的方法