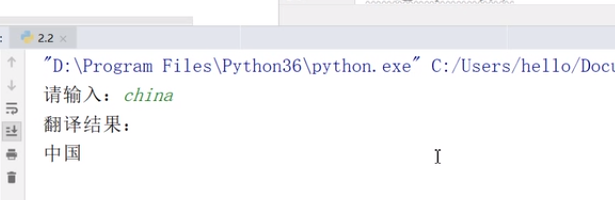
通过爬取有道词典的翻译结果连接post方法的爬虫方法
首先我们分析网页的内容
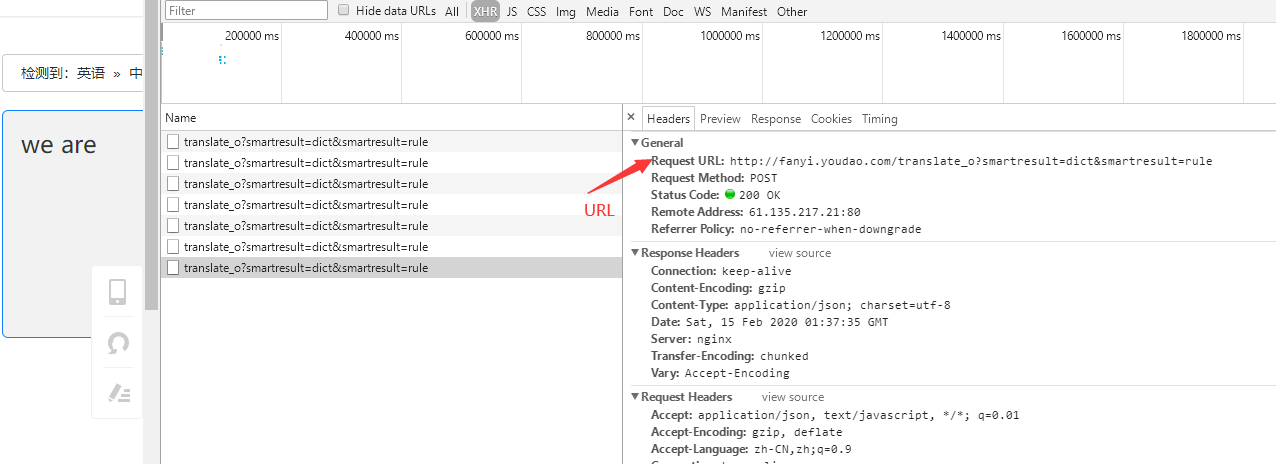
这个是需要爬取的网址,下面有post提交的表单

接下来爬取的代码实现的步骤如下:
基于控制台获取到输入的待翻译词语
设定请求的URL
这里有一个反爬的措施,translate_o?这个_o删除即刻
建立post的表单,并且将浏览器拷贝下来的表单修改成最基本的字典的格式
提交post请求
接受到相应的结果
json字符串转化成python的字典格式
打印翻译的结果
import requests import json #基于控制台获取到输入的待翻译词语 content = input("请输入:") #设定请求的URL url = 'http://fanyi.youdao.com/translate_?smartresult=dict&smartresult=rule' #这里有一个反爬的措施,translate_o?这个_o删除即刻 #url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #建立post的表单,并且将浏览器拷贝下来的表单修改成最基本的字典的格式 post_form = { 'i': content, 'from':' AUTO', 'to':' AUTO', 'smartresult':' dict', 'client':' fanyideskweb', 'salt':' 15817288178174', 'sign':' a28b6746d6d2ca8f79e0c77cf7f101f2', 'ts':' 1581728817817', 'bv':' 6275445dcf58d2f326d4a0dd44c9b352', 'doctype':' json', 'version':' 2.1', 'keyfrom':' fanyi.web', 'action':' FY_BY_REALTlME', 'typoResult' : 'false' } #提交post请求 response = requests.post(url,data=post_form) #接受到相应的结果 trans_json = response.text #json字符串转化成python的字典格式 trans_dict = json.loads(trans_json) result = trans_dict['translateResult'][0][0] #打印翻译的结果 print("翻译结果:") print(result) print()
结果如下