http://www.cnblogs.com/spork/archive/2010/04/12/1710294.html
通过前面两篇文章的分析,对Hadoop的作业提交流程基本明了了,下面我们就可以开始编写代码模拟这个流程。
第一步要做的是添加Hadoop的依赖库和配置文件到classpath。最常用的方法就是用一个容器先把各个要添加到classpath的文件或文件夹存储起来,后面再作为类加载器的URL搜索路径。

/**
* Add a directory or file to classpath.
*
* @param component
*/
public static void addClasspath(String component) {
if ((component != null) && (component.length() > 0)) {
try {
File f = new File(component);
if (f.exists()) {
URL key = f.getCanonicalFile().toURL();
if (!classPath.contains(key)) {
classPath.add(key);
}
}
} catch (IOException e) {
}
}
}
上面的classPath变量就是我们声明用来装载classpath组件的容器。
private static ArrayList<URL> classPath = new ArrayList<URL>();
由于需要添加一些文件夹下的所有Jar包,所以我们还要实现一个遍历添加某文件夹下文件的方法。
/**
* Add all jars in directory to classpath, sub-directory is excluded.
*
* @param dirPath
*/
public static void addJarsInDir(String dirPath) {
File dir = new File(dirPath);
if (!dir.exists()) {
return;
}
File[] files = dir.listFiles();
if (files == null) {
return;
}
for (int i = 0; i < files.length; i++) {
if (files[i].isDirectory()) {
continue;
} else {
addClasspath(files[i].getAbsolutePath());
}
}
}
简单起见,这个方法没有使用Filter,对文件夹下的文件是通吃,也忽略掉了子文件夹,只处理根文件夹。
好了,有了基础方法,下面就是照着bin/hadoop中脚本所做的,把相应classpath添加进去。
/**
* Add default classpath listed in bin/hadoop bash.
*
* @param hadoopHome
*/
public static void addDefaultClasspath(String hadoopHome) {
// Classpath initially contains conf dir.
addClasspath(hadoopHome + "/conf");
// For developers, add Hadoop classes to classpath.
addClasspath(hadoopHome + "/build/classes");
if (new File(hadoopHome + "/build/webapps").exists()) {
addClasspath(hadoopHome + "/build");
}
addClasspath(hadoopHome + "/build/test/classes");
addClasspath(hadoopHome + "/build/tools");
// For releases, add core hadoop jar & webapps to classpath.
if (new File(hadoopHome + "/webapps").exists()) {
addClasspath(hadoopHome);
}
addJarsInDir(hadoopHome);
addJarsInDir(hadoopHome + "/build");
// Add libs to classpath.
addJarsInDir(hadoopHome + "/lib");
addJarsInDir(hadoopHome + "/lib/jsp-2.1");
addJarsInDir(hadoopHome + "/build/ivy/lib/Hadoop/common");
}
至此,该添加classpath的都已添加好了(未包括第三方库,第三方库可用Conf中的tmpjars属性添加。),下去就是调用RunJar类了。本文为了方便,把RunJar中的两个方法提取了出来,去掉了一些可不要的Hadoop库依赖,然后整合到了类EJob里。主要改变是把原来解压Jar包的“hadoop.tmp.dir”文件夹改为"java.io.tmpdir",并提取出了fullyDelete方法。
利用这个类来提交Hadoop作业很简单,下面是一个示例:
args = new String[4];
args[0] = "E:\\Research\\Hadoop\\hadoop-0.20.1+152\\hadoop-0.20.1+152-examples.jar";
args[1] = "pi";
args[2] = "2";
args[3] = "100";
// 传入Hadoop Home的地址,自动添加相应classpath。
EJob.addDefaultClasspath("E:\\Research\\Hadoop\\hadoop-0.20.1+152");
EJob.runJar(args);
上面这个示例调用了Hadoop官方例子Jar包里的pi计算例子,传递参数时同bin/hadoop jar *.jar mainclass args命令类似,但是忽略掉了bin/hadoop jar这个命令,因为我们现在不需要这个脚本来提交作业了。新建一个Project,添加一个class,在main里粘上上面的代码,然后Run as Java Application。注意看你的Console,你会发现你已经成功把作业提交到Hadoop上去了。
有图有真相,粘一下我的运行示例(在Win上开Eclipse,Hadoop Cluster在Linux,配置文件同Cluster的一样)。
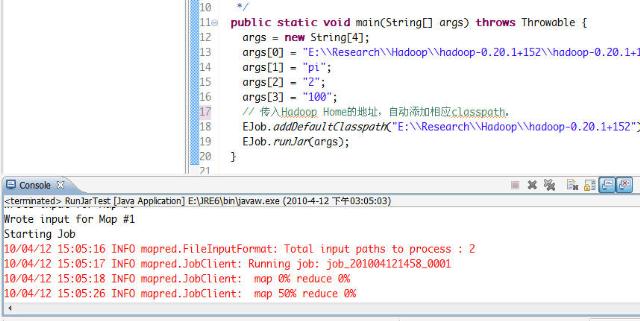
下面是在Cloudera Desktop看到的Job信息(它的时间是UTC的)。

用上述方法,我们可以做一个类似Cloudera Desktop的Web应用,接受用户提交的Jar,并在Action处理中提交到Hadoop中去运行,然后把结果返回给用户。
由于篇幅原因,加上前面介绍过RunJar类,所本文没有粘关于RunJar类的代码,不过你放心,本文提供例子工程下载。你可以在此基础上优化它,添加更多功能。由于大部分是Hadoop的代码,So,该代码基于Apache License。
到此,以Java方式提交Hadoop作业介绍完毕。但,是否还可以再进一步呢?现在还只能提交打包好的MR程序,尚不能像Hadoop Eclipse Plugin那样能直接对包含Mapper和Reducer的类Run on Hadoop。为什么直接对这些类Run as Java Application提交的作业是在Local运行的呢?这其中又包含有什么秘密呢?我们将在下面的文章中更深入的剖析Hadoop的作业提交代码,去到最底层,慢慢揭开它的黑面纱。
To be continued...