Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口 从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map是一个接口,实例化Map可以采用下面的方式:
- HashMap //Map基于散列表的实现。插入和查询“键值对”的开销是固定的。可以通过构造器设置容量capacity和负载因子load factor,以调整容器的性能。
- hashMap的数据结构是由:数组+链表+红黑树的形式存储的如下图
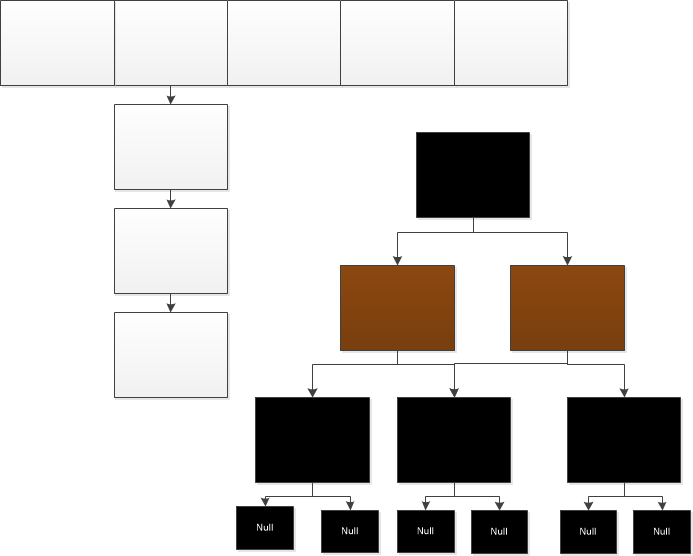
初始数组大小为16,增长因子为0.75,当数量大于n*0.75时,n*2
如果put(k,v);
1.先用key计算出hash值,在源码中使用(n-1)&hash(其相当于hash%n),前者效率更高,将node节点放入相应的数组位置
2.如果hashcode()相同,则使用链表存储
-
- 当链表长度大于8时,则将链表转为红黑树存储
- 当使用remove后,如果链表长度小于6,则将红黑树转换为链表
3.当数量达到n*0.75时,将数组进行扩容,及n=n*2;扩容则是新建一个为原来数组大小的两倍的数组,其中原来的的节点放在原位置或者原位置+16.
- LinkedHashMap //类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次序,或者是最近最少使用(LRU)的次序。只比HashMap慢一点。而在迭代访问时发而更快,因为它使用链表维护内部次序。
- TreeMap //底层是二叉树数据结构,线程不同步,可用于给Map集合中的键进行排序。
- HashTable //HashMap是Hashtable的轻量级实现,非线程安全的实现他们都实现了map接口,主要区别是HashMap键值可以为空null,效率可以高于Hashtable。
- ConcurrentHashMap //ConcurrentHashMap通常只被看做并发效率更高的Map,用来替换其他线程安全的Map容器,比如Hashtable和Collections.synchronizedMap。
- WeakHashMap //弱键(weak key)Map,Map中使用的对象也被允许释放: 这是为解决特殊问题设计的。如果没有map之外的引用指向某个“键”,则此“键”可以被垃圾收集器回收。
- IdentifyHashMap //使用==代替equals()对“键”作比较的hash map
- ArrayMap //ArrayMap是一个<key,value>映射的数据结构,它设计上更多的是考虑内存的优化,内部是使用两个数组进行数据存储,一个数组记录key的hash值,另外一个数组记录Value值,它和SparseArray一样,也会对key使用二分法进行从小到大排序,在添加、删除、查找数据的时候都是先使用二分查找法得到相应的index,然后通过index来进行添加、查找、删除等操作,所以,应用场景和SparseArray的一样,如果在数据量比较大的情况下,那么它的性能将退化至少50%。
- SparseArray //SparseArray比HashMap更省内存,在某些条件下性能更好,主要是因为它避免了对key的自动装箱(int转为Integer类型),它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间。
Map的基本操作:
- Object put(Object key, Object value): 向集合中加入元素
- Object remove(Object key): 删除与KEY相关的元素
- void putAll(Map t): 将来自特定映像的所有元素添加给该映像
- void clear():从映像中删除所有映射
-
删除:集合名.remove(键); 从映射中移除指定键的映射关系(如果存在)
判断:集合名.containsKey(键); 如果此映射包含对于指定键的映射关系,返回true
集合名.containsValue(值);如果此映射将一个或多个键映射到指定值,返回true
其它:集合名.size(); 获得集合的大小
Map使用
这里以最常用的HashMap为例
添加数据
Map<Integer, String> hashMap = new HashMap<>(); for (int i = 0; i < maxCount; i++) { hashMap.put(i, String.valueOf(i)); }
遍历entrySet方式
//用entry遍历
for (Map.Entry<String, String> entry: hashmap.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"-"+value);
}
//用Iterator遍历
Iterator<Entry<String, String>> iterator = hashmap.entrySet().iterator();
while(iterator.hasNext()){
Entry<String, String> entry = iterator.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"+"+value);
}
1、Map没有实现的超级父类接口,不是Collection的直接接口子类
2、了解HashMap类
A):定义的格式:HashMap<类型,类型>集合名 = new HashMap<类型,类型>();
B):数据的存储方法:key+value的存储方式
C):对象的类型:必须要定义集合对象类型,否则会影响后续的使用
D)集合的设计:泛型的方式进行类型的指定:HashMap<具体类型>
特点:一条数据,是由两部分组成:键和值,元素无序、不可重复,可变大小的容器
遍历:需要使用键的迭代器 Set<类型>名称1 =集合名.keySet();
Iterator<类型>名称 =名称1.iterator();