架构图
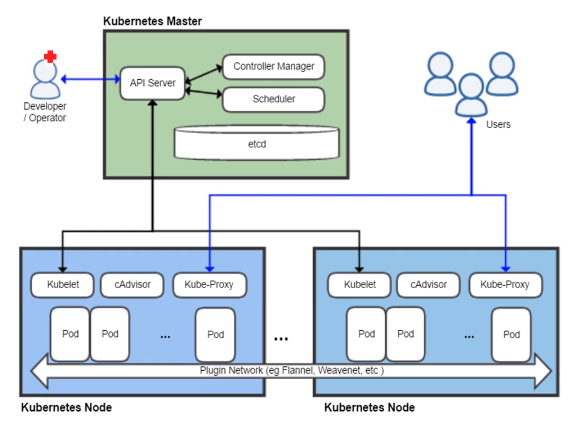
核心组件
| 组件名称 | 说明 |
| apiserver | 提供了资源操作的唯一入口,并提供了认证、授权、访问控制、API注册和发现等机制 |
|
cAdvisor |
|
| container runtime | 容器运行时。默认为Docker |
| controller manager | 负责维护集群的状态。比如故障检测、自动弹性伸缩、滚动更新等 |
| etcd | 保存了整个集群的信息(状态) |
| kube-proxy | 负责为Service提供集群内部的服务发现和负载均衡 |
| kubectl | 管理k8s的命令行工具。负责维护容器的生命周期,同时也负责Volume和网络的管理 |
| Scheduler | 负责资源的调度。按照预定的调度策略将Pod调度到相应的机器上 |
附加组件
| 名称 | 说明 |
| Dashboard | 是Kubernetes集群通用的Web管理界面。通过调用api-server中的rest接口 |
| DNS | 创建一个DNS服务器,用于Service的VIP域名解析(不然每次启动Service,都会重新生成一个新的VIP,这样又得改RC或者Deployment的配置文件)。 |
| Heapster | 提供资源监控,包括内存、CPU等使用情况。数据来源是cAdvisor,一般是配合Dashboard使用 |
| PersistentVolume(PV) | 持久卷。由管理员添加的一个存储的描述,是一个全局资源(不受Namespace限制),包含存储类型、存储大小和访问模式等。它的生命周期独立于pod(pod销毁时对PV没有影响) |
| PersistentVolumeClaim(PVC) | 表达的是用户对存储(请求信息包含存储大小、访问模式等)的请求。它类似于pod,pod消耗节点资源:PVC消耗PV资源。PVC会绑定到大于等于且最接近自己存储请求的PV上 |
| Service(SVC) |
|
资源控制器
| 名称 | 说明 |
| Replication Controller(RC) |
|
| Deployment(推荐) |
|
| Job | 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束 |
| CronJob | 周期性的执行任务 |
| Horizontal Pod Autoscaler(HPA) |
|
集群调度
调度过程
调度分为一下几步:
- 首先过滤掉不满足条件的节点,这个过程是 predicate。在 predicate 过程中没有合适的节点,Pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件
- 然后对通过的节点按照优先级排序,这个过程是 priority
- 最后从中选择优先级最高的节点
如果中间任务一步有错误,就直接返回错误。
predicate有一系列的算法:
- PodFitsResources:节点上剩余的资源是否大于 Pod 请求的资源
- PodFitsHost:如果 Pod 指定了NodeName,检查节点名称是否和 NodeName 匹配。
- PodFitsHostPorts:节点上已经使用的 port 是否和 Pod 申请的 port 冲突
- PodSelectorMatched:过滤掉和 Pod 指定的 label 不匹配的节点
- NoDiskConflict:已经 mount 的 volume 和 Pod 指定的 volume 不冲突,除非他们都是只读
调度策略
| 名称 | 说明 |
| 亲和性 | Node亲和性、Pod亲和性。尽量分配到自己想去的那个 Node 或者 Pod |
| 污点/容忍 |
避免 Pod 被分配到不合适的节点。每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,是不会 被该节点接受的。如果能容忍,则表示这些 Pod 可以被调度到这些污点上 |
| 固定节点 | 将 Pod 直接调度到指定的节点上 |
其它
| 名称 | 说明 |
| Pod | pod容器 + 若干普通的业务容器 |
| 健康检查(探测器) |
|
| Namespace |
|