第一单元表达式求导总结
第一次作业
项目度量
类方法规模
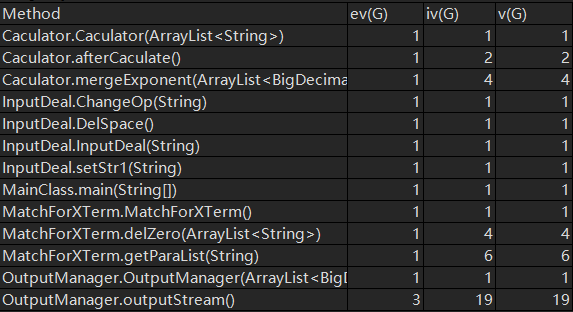
UML图(仅显示继承关系,调用说明以文字形式表述,以下同理)

本次作业的具体思路是先将输入的表达式送到InputDeal中去除空格和双符号和三符号完成化简,之后通过MatchForXTerm类的getParaList方法得到一个列表,该列表两个一组紧挨着存储,代表一个带系数的幂函数,通过delZero方法将列表中指数或者系数为0的项去除。之后通过Calculator(上图中拼写错误,捂脸)轻松得到求导后的一组数据,之后为了优化合并了同类项,再通过OutputManager将数据组合输出。
第一次作业看似简单,但是我好多地方都疏忽了,比如说其中一个bug就是由ArrayList的remove方法导致的,可变对象的一些改变自身的方法重复使用的话一定保证参数的合理性和正确性。另一个bug是由于没有判断输入全部为常数或者输入中的x项均为无效(指数或系数为0)导致的。在整个结构将要完成的时候没有将问题考虑全面,这部分功能其实应该在Calculator类中实现,判断输出的列表是否为空。
在互测阶段我先是盲放了一个我在自己写代码之前做的一个包含各种情况的用例,主要集中在0和1的不同位置上,还是发生了不少和我自己bug相似的,然后试着读了几份代码,有针对性地提交了几个测试用例。
第二次作业
项目度量
类方法规模

UML图
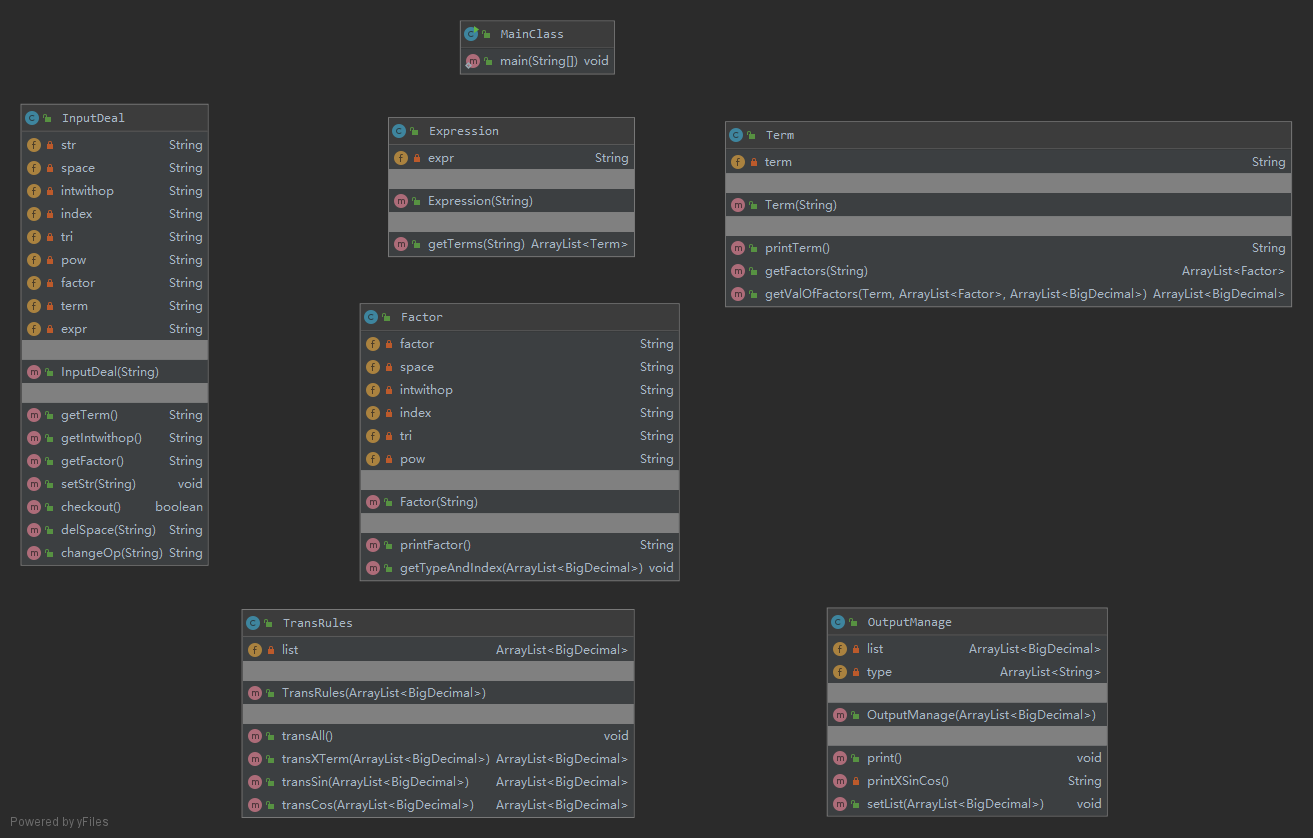
第二次作业在设计之初吸取了上次作业中的教训,绝不在程序中间对数据进行删减,但是合并之类的还是要做,主要为了方便。同样是InputDeal进行输入的处理,先判断格式上的合理性,用的是大正则。之后通过Expression类的getTerms方法得到项的列表,项再得到因子列表,因子判断自己的类型以及参数,并且对传入的四元列表进行修改,直到该项全部识别完,四元分别代表a*x**b*sin(x)**c*cos(x)**d中的a、b、c、d。然后以项作为一个求导单元,通过TransRules类进行求导,其中求导我统一采用了(FGH)' = (FG)'H+FGH'=(F'G+FG')H+FGH'=F'GH+FG'H+FGH'的规则,分别对三种因子求导并输出。没有优化化简,全部保证正确性。
第二次作业的bug只出现在了对指数的判断上,我把10000这个边界数据也算为WF了。
第二次作业在互测方面没有放多大的精力,只是将自己测试的时候一些比较复杂的用例以及常数项提交上去了。
第三次作业
项目度量
类方法规模

UML图
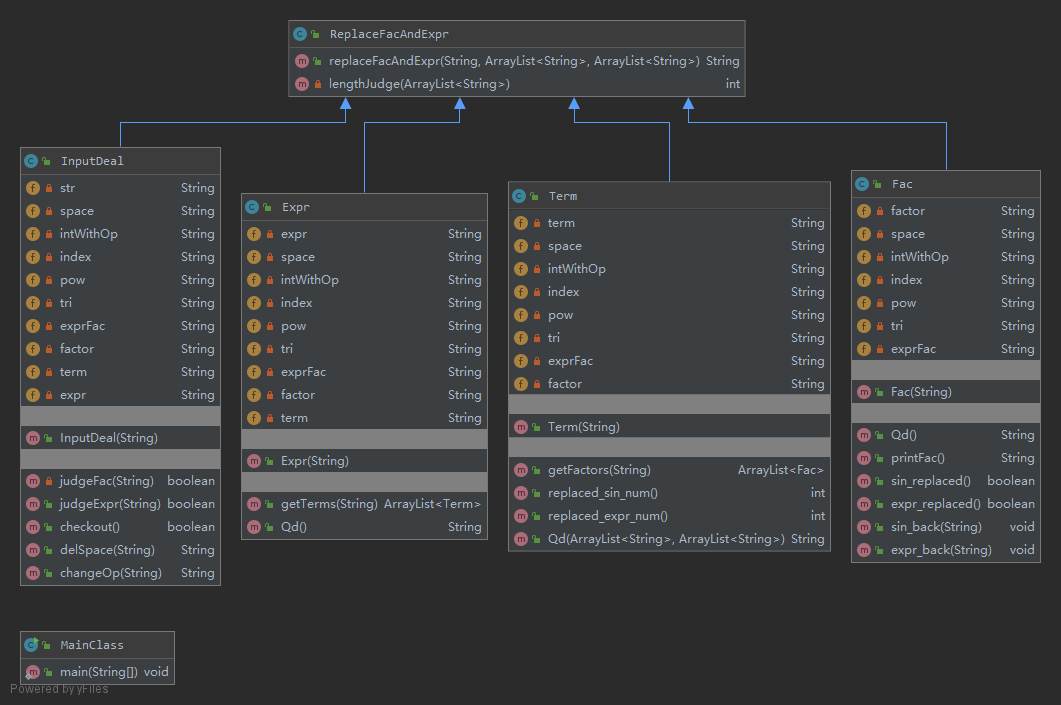
第三次作业设计的时候遇到了难题,递归是必须要实现的,但是一直局限在正则表达式中,看到了可以通过替换的方法,然后写了一个综合正则和替换的进行规则匹配验证正确性的模块,即InputDeal中的checkout函数,其主要是通过judgeExpr和judgeFac函数相互递归调用来实现的。同时也可以从上图中看出四个类都继承自ReplaceFacAndExpr类,主要是为了用替换方法,通过传入两个列表和一个字符串,可以将三角函数括号中的全部元素存入因子列表,将表达式因子括号中的全部元素存进表达式列表,并且将替换完了之后的字符串返回,输入的字符串不会发生改变。在判断格式的时候先进行替换,然后对替换完的字符串匹配正则,同时对替换产生的因子列表和表达式列表判断,如此递归下去。
在求导的时候同样需要递归,当然这一部分我主要放在了因子部分,因为因子中会包含表达式以及自身。随之而来的就是上图中因子的Qd方法过于冗杂,甚至影响了checkstyle,当时主要追求正确性了,没有考虑那么多。我同样复用了第二次作业中的一些框架,比如表达式得到项,项得到因子,因子求导返回字符串。这里之所以不设置OutputManager是因为因子的求导还是比较复杂的,不同因子求导需要的参数也不一致,而且还有递归关系,没有考虑再搬出去实现求导。再整个过程中比较花费设计的是项中的求导,bug也是产生在这里。Term类中需要实现得到项首符号的任务,同时,在下一层的因子求导中,需要将因子中被替换的元素悉数奉还,或者在此层就替换回去,为此需要在表达式Qd的方法中将得到的替换因子列表和表达式列表按照项给分开,在项这一步得到因子列表后再将因子还原。
第三次作业同样保证在正确性,bug只出现在了判断符号的部分,缺少了对于新增的括号类型因子的判断。
互测就将几个比较考验递归的数据提交上去了,没有针对代码提出相应的样例。
三次作业对比分析
本次三次作业,我只在第一次作业中用了优化,之后两次作业都只保证了正确性。现在回头看看,觉得自己的选择还是比较正确的,虽说后两次作业依旧有bug,但是在不考虑优化的情况下,目的性就会比较明确,代码中不会出现会混淆试听的对字符串或者元素的修改,就比较好保证全部代码沿着设计路线走。第二次作业相比第一次作业算是一次重构,增加了因子类型后,第一次作业中的很大部分功能都需要重写,MatchForXTerm类和Calculator类都不再适用。第三次作业相比第二次作业我可能对于面向对象的理解深了一层,老师在讲课的过程中经常提起封闭性,为了安全也为了使程序简单。本次第三次作业的方法数比第二次作业还要少,而且单独在设计ReplaceFacAndExpr的时候尤其小心,对传入的数据进行复制保护,同时对输入的列表一定要做清理,而且还做了模块测试。第三次作业在第二次作业的基础上增加了替换这一个步骤,同时削减了输出控制(总之就是非常后悔),在套用的时候一定要小心,虽然大体上的功能都是可以使用的,但是还是针对增加的特定情况做特定处理,这次bug出现在照抄照搬第二次作业上。
心得体会
面向对象的核心思想应该是在于封装和继承,通过将解决问题中产生的零碎问题实例化,并且调用自己内部的行为来完成自身问题的转化移交给下一步或者下一个模块或者分解为更多的小问题,这种思想是比较符合人的思考方式的,同时也更加的抽象。虽说只在第三次作业的时候才体会到继承功能的强大,但是前两次作业也慢慢的对于面向对象有了自己的一些想法,因为在解决整个问题的过程中,一步步通过分解问题,在小问题中封闭式的思考会更便于解决问题。同时在设计程序的时候还是需要遵守一定的规范,将自己的类的属性保护好,在需要改变的时候需要想清楚改变的元素是哪些,同时在改变前后会不会对别的方法产生影响。类之间公共的行为可以封起来作为一个接口,类通过继承并实现相应方法会更加便于管理,不会太过于复杂。最后,希望这此可以度过OO难关。