最简单的curl请求:
在CRM项目之中的小例子,在PHP代码之中接口数据调用,用这个是再合适不过啦。
curl之中发送cookie
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Cookie:name=mary;'));
如同PHP文件函数之中file_get_contents比fopen好用多啦的感觉。
自己写的小demo:
<?php
// 1. 初始化
$ch = curl_init();
// 2. 设置选项,包括URL
curl_setopt($ch,CURLOPT_URL,"http://localhost/curl/reg.php");
// 设置获取到内容不直接输出到页面上
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
// CURLLOPT_HEADER设置为0表示不返回HTTP头部信息
curl_setopt($ch,CURLOPT_HEADER,0);
// 3. 执行并获取HTML文档内容
$output = curl_exec($ch);
if($output === FALSE )
{
echo "CURL Error:".curl_error($ch);
}
else
{
var_dump($output);
}
// 4. 释放curl句柄
curl_close($ch);
接口:
<?php echo 'hello,i am curl';
没错就是这么简单粗暴,输出结果如下:

现在CRM之中的demo,看看他是如何封装的。
教教你写发送POST请求的function:
protected function Curl($Url, $PostData)
{
$ch = curl_init();
//设置接口地址
curl_setopt($ch, CURLOPT_URL, $Url);
//设置超时时间
curl_setopt($ch, CURLOPT_TIMEOUT, 5000);
//设置请求类型为POST
curl_setopt($ch, CURLOPT_POST, 1);
//设置post的数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $PostData);
//请求数据成功默认不输出数据到页面(这个应该每个都要吧,/苦笑)
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
//发出请求
$html = curl_exec($ch);
curl_close($ch);
//返回数据
return $html;
}
接口那里是怎样写的呢?
public function GetUser($FieldArr, $Where = '', $OneRow = false) { if(!empty($FieldArr) && is_array($FieldArr)) { $Sql = sprintf("SELECT %s FROM yp_user as u JOIN yp_us as ui ON u.u_zd=ui.ui_uid left JOIN yp_user_level ON u_ul_id=ul_id WHERE 1 %s", implode(',', $FieldArr), $Where); $ResFlag = $this->OthDb->Query($Sql); if($ResFlag) { $Arr = array(); while($Row = $this->OthDb->Fetch()) { if($OneRow) { $Arr = $Row; break; } else { $Arr[] = $Row; } } return LibFc::ReturnData(true, $Arr); } return LibFc::ReturnData(false, 'SQL语句执行失败。'); } return LibFc::ReturnData(false, 'GetUser 提供的参数不正确。'); }
就是一个returndata罢了
批处理cURL封装类:
具体自己看文档啦,文档的范例杠杠的好用,毕竟是PHP ,这种底层的扩展.dll ini设置别忘了就可以,然后函数
基类扩展基本也用不上,看例子:可以直接跑直接输出哦!
<?php /** * 多进程获取数据 By Curl */ function curlByArr($urlArr = []) { $map = []; $funcRes = []; // 默认配置 $option = [ // 头信息 CURLOPT_HEADER => false, // 超时 CURLOPT_TIMEOUT => 1000, CURLOPT_NOSIGNAL => true, // 标识返回获取的输出的文本流 CURLOPT_RETURNTRANSFER => true, CURLOPT_FOLLOWLOCATION => true, ]; // 队列 $mh = curl_multi_init(); // 循环网址 foreach ($urlArr as $k => $v) { // 执行 $handle = curl_init(); // 对每一个url建立curl句柄 curl_setopt($handle, CURLOPT_URL, $v['url']); // 设置参数 foreach ($option as $opt => $val) { curl_setopt($handle, $opt, $val); } // 向curl批处理会话中添加单独的curl句柄 curl_multi_add_handle($mh, $handle); $map[(string)$handle] = $v['id']; } // 执行 do { // curl_multi_exec(多个curl句柄,判断是否仍在执行的标志) // 返回批处理栈相关错误(即使 CURLM_OK 也不排除单个传输有问题) // CURLM_CALL_MULTI_PERFORM 并发查询一次 while (($mhRes = curl_multi_exec($mh, $still_running)) == CURLM_CALL_MULTI_PERFORM) ; // 如果批处理结果错误就中断当前批处理请求 if ($mhRes != CURLM_OK) { break; } // curl_multi_info_read — 获取当前解析的cURL的相关传输信息 while ($eachMutiRes = curl_multi_info_read($mh)) { // curl_getinfo — 获取一个cURL连接资源句柄的信息 // 参数:由 curl_init() 返回的 cURL 句柄,opt;opt决定具体返回数值,不传就返回all $info = curl_getinfo($eachMutiRes['handle']); // curl_error — 返回当前会话最后一次错误的字符串,未发生error则返回""空字符串 $error = curl_error($eachMutiRes['handle']); // 获取的输出的文本流 $html = curl_multi_getcontent($eachMutiRes['handle']); // compact 创建一个包含变量名和它们的值的数组; // 赋值到一个方法返回值 $funcRes[$map[(string) $eachMutiRes['handle']]] = compact('info', 'error', 'html'); // curl_multi_remove_handle — 移除cURL批处理句柄资源中的某个句柄资源 curl_multi_remove_handle($mh, $eachMutiRes['handle']); // curl_close — 关闭 cURL 会话 curl_close($eachMutiRes['handle']); } if ($still_running > 0) { // curl_multi_select — 等待所有cURL批处理中的活动连接 curl_multi_select($mh, 0.1); } } while ($still_running); // curl_multi_close — 关闭一组cURL句柄 curl_multi_close($mh); // 返回批处理执行结果 return $funcRes; } $arr = array( ['id'=>1,'url'=>'www.cn357.com/notice_302'], ['id'=>2,'url'=>'www.cn357.com/notice_301'] ); $res = curlByArr($arr); // 返回值: // $res = array( // 1 => [ // 'html' => , // 'error' => , // 'info' => // ], // 2 => [ // ] // ); // 校验单个curl是否success可以用info的CURLINFO_HTTP_CODE是否200以及strpos
cURL与HTTPS:
PHP的cURL选项CURLOPT_SSL_VERIFYPEER详解:
http://www.3mu.me/php%E7%9A%84curl%E9%80%89%E9%A1%B9curlopt_ssl_verifypeer%E8%AF%A6%E8%A7%A3/
一些参数:
// 是否exec结果作变量存储 curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); // 成功连接服务器前最长等待时长(单位秒数) curl_setopt($curl, CURLOPT_CONNECTTIMEOUT , 500); // 连接服务器后,接收缓冲完成前需要等待最大时长限定,目标文件巨大是否会非常需要(单位秒数) curl_setopt($curl, CURLOPT_TIMEOUT, 500);
请求HTTPS网页的时候记得关掉证书校验哦,如果开启记得告诉curl验证证书存储路径也是可以的。
// 跳过证书检查 curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); // 从证书中检查SSL加密算法是否存在 curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); // 实例化url句柄 curl_setopt($ch, CURLOPT_URL, $url); // 传递头信息 curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
cURL参数:
http://blog.csdn.net/linglongwunv/article/details/8020845
http://www.jb51.net/article/41831.htm
多线程发送http请求:
这是一个非常简单的多线程小李子,仅作笔记使用,而且用这个下载是非常快的,
<?php // 多线程爬取数据 class downPage extends Thread { private $url = ''; public function __construct($url){ $this->url = $url; } public function run() { $ch = curl_init(); // 取消证书检查 curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); // 从证书中检查SSL加密算法是否存在 curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); // 实例化url句柄 curl_setopt($ch, CURLOPT_URL, $this->url); // 是否将输出流变量形式存储 curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); // 成功连接服务器前最长等待时长(单位秒数) curl_setopt($ch, CURLOPT_CONNECTTIMEOUT , 30); // 连接服务器后,接收缓冲完成前需要等待最大时长限定,目标文件巨大是否会非常需要(单位秒数) curl_setopt($ch, CURLOPT_TIMEOUT, 300); // 执行结果 $html = curl_exec($ch); // 返回头信息 $info = curl_getinfo($ch); // 返回报错信息 $error = curl_error($ch); // 关闭资源句柄 curl_close($ch); // 写入文件 file_put_contents(md5($this->url).'.html',$html); } } $urls = array(); $startime = time(); for ($i=55; $i <100 ; $i++) { // 一个url创建一个线程(也就是一个) $urls[] = new downPage('http://www.cn357.com/notice_'.$i); } // 开始线程(调用start就会运行run方法) foreach($urls as $url) { $url->start(); } //各个线程相对于主线程都是异步执行,调用此方法会等待线程执行结束之后才会继续往下执行(下面的echo会在所有线程执行完了输出) foreach($urls as $url) { $url->join(); } $time = time() - $startime; echo " every thread is completed!\r\n"; echo $time.' second.'; ?>
相关资料:
https://www.cnblogs.com/zhenbianshu/p/7978835.html
https://www.cnblogs.com/jkko123/p/6351604.html
https://kb.cnblogs.com/page/542462/
https://kb.cnblogs.com/page/531409/
提醒一下:
http://php.net/manual/zh/book.pthreads.php
在安装那个文件章节下面的范例会告诉你怎么选择扩展还有下载链接。版本的话、注意线程是否安全版、32还是64、PHP版本就可以了,还有要多建立一个php.ini哦,web模式是不支持多线程的,所以你的apache会启动不了的、
https://segmentfault.com/q/1010000008101102
推荐:guzzle客户端 - 使用异步多线程可以快速爬取网页并且保证页面完整性。
’
复杂一点的请求:
还是交给guzzle处理吧,使用composer安装guzzle然后
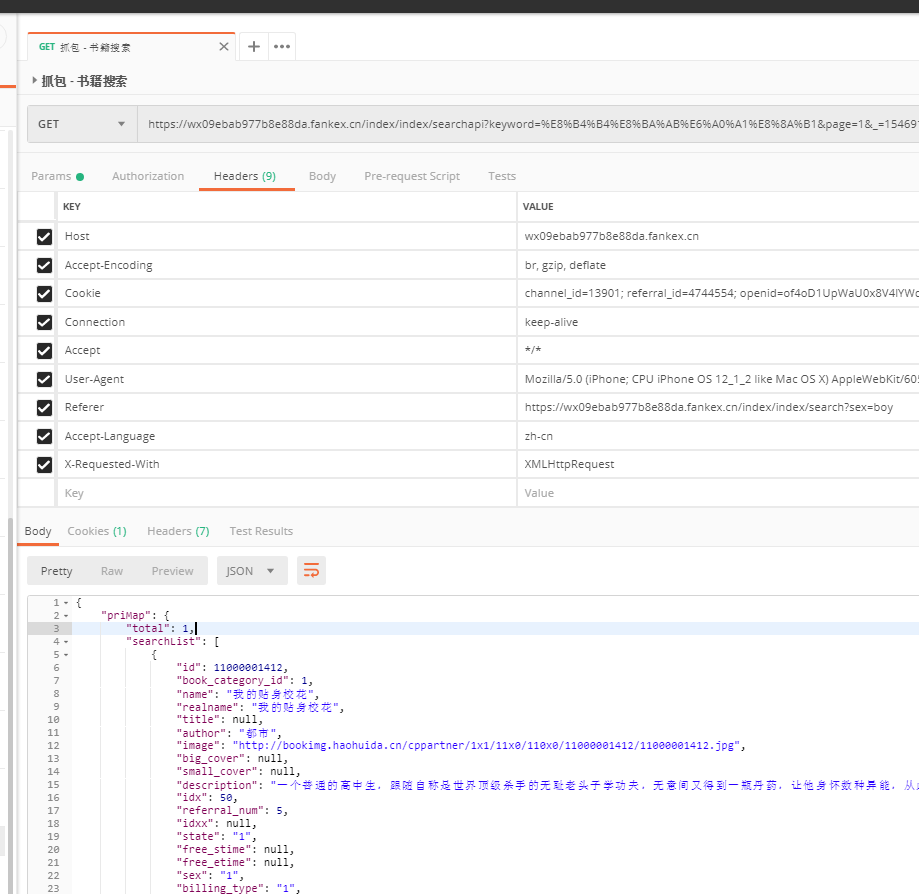
像这个请求
有cookie和user-agen浏览器标识等,需要加入header和关闭ssl验证,如果自己curl写的话,还是有点儿、累的,嘿嘿,有开源工具自然用这个好,除非你不会用:
<?php require('./vendor/autoload.php'); $client = new GuzzleHttp\Client(); $res = $client->request('GET', 'https://wx09ebab977b8e88da.fankex.cn/index/index/searchapi?keyword=%E8%B4%B4%E8%BA%AB%E6%A0%A1%E8%8A%B1&page=1&_=1546916156580', [ 'verify' => false, 'headers' => [ 'Accept-Encoding'=>'br,gzip,deflate', 'User-Agent'=>'Mozilla/5.0 (iPhone; CPU iPhone OS 12_1_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/16C101 MicroMessenger/7.0.1(0x17000120) NetType/WIFI:Language/zh_CN', 'Accept'=>'*/*', 'Connection'=>'keep-alive', 'Referer'=>'https://wx09ebab977b8e88da.fankex.cn/index/index/search?sex=boy', 'Accept-Language'=>'zh-cn', 'X-Requested-With'=>'XMLHttpRequest', 'Cookie'=>'channel_id=13901; referral_id=4744554; openid=of4oD1UpWaU0x8V4lYWdPmycsA9o; user_id=526543460' ] ]); // 'application/json; charset=utf8' $a = $res->getBody(); echo $a;
在这里顺便推荐一下,花瓶charles抓包工具,可以抓到你的iphone的数据包哦!嘿嘿
https://www.jianshu.com/p/5539599c7a25?tdsourcetag=s_pcqq_aiomsg (十分钟学会Charles抓包(iOS的http/https请求)
curl发送post请求获取cookie
/** * 发送post请求 * @param [string] $source_url 文件远程地址 * @param [string] $save_file 文件本地存储路径 * @author xu * @copyright 2018-11-14 */ function curl_post($url, $post_data,$reture_cookie = false) { $ch = curl_init(); //设置接口地址 curl_setopt($ch, CURLOPT_URL, $url); //设置超时时间 curl_setopt($ch, CURLOPT_TIMEOUT, 5000); //关闭https验证 curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //设置请求类型为POST curl_setopt($ch, CURLOPT_POST, 1); //设置post的数据 curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); //请求数据成功默认不输出数据到页面(这个应该每个都要吧,/苦笑) curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //至关重要,CURLINFO_HEADER_OUT选项可以拿到请求头信息 curl_setopt($ch, CURLINFO_HEADER_OUT, TRUE); // 获取头部信息 if($reture_cookie){ curl_setopt($ch, CURLOPT_HEADER, 1); //发出请求 $html = curl_exec($ch); curl_close($ch); // 解析http数据流 list($header, $body) = explode("\r\n\r\n", $html); // 解析cookie preg_match("/set\-cookie:([^\r\n]*)/i", $header, $matches); $cookie = $matches[1]; return $cookie; } //发出请求 $html = curl_exec($ch); curl_close($ch); //返回数据 return $html; }