在腾讯新闻抢金达人活动 node 同构直出渲染方案的总结文章中我们整体了解了下同构直出渲染方案在我们项目中的使用。正如我在上篇文章结尾所说的:
应用型技术的难点不是在克服技术问题,而是在于能够不断的结合自身的产品体验,发现其中存在的体验问题,不断使用更好的技术方案去优化用户的体验,为整个产品发展添砖加瓦。
我们在根据产品的体验效果选择了 react 同构直出渲染方案,必然也要保证当前方案的可用性和可靠性。例如我们的服务能同时支撑多少人访问,当用户量增大时是否可以依然保证用户的正常访问,如何保证 CPU、内存等正常运作,而不被一直占用无法释放等。因此,这里我们应当下我们项目的几项数据:
- 项目一天的访问量是多少,高峰期的访问量是多少,即并发的用户量有多少;
- 我们的单机服务最大能支持多少 QPS;
- 高并发时的服务响应时间如何,页面,接口的失败率有多少;
- CPU 和内存的使用情况,是否存在 CPU 使用不充分或者内存泄露等问题;
这些数据,都是我们上线前要知道的。压力测试的重要性就提现出来了,我们在上线前进行充分的测试,能够让我们掌握程序和服务器的运行性能,大致申请多少台机器等等。
1. 初次压力测试
我们这里使用autocannon来对项目进行压测。注意,我们现在还没有进行任何的优化措施,就是要先暴露出问题来,然后针对性的进行优化。
每秒钟 60 的并发,并持续 100 秒:
autocannon -c 60 -d 100
压测后的数据:
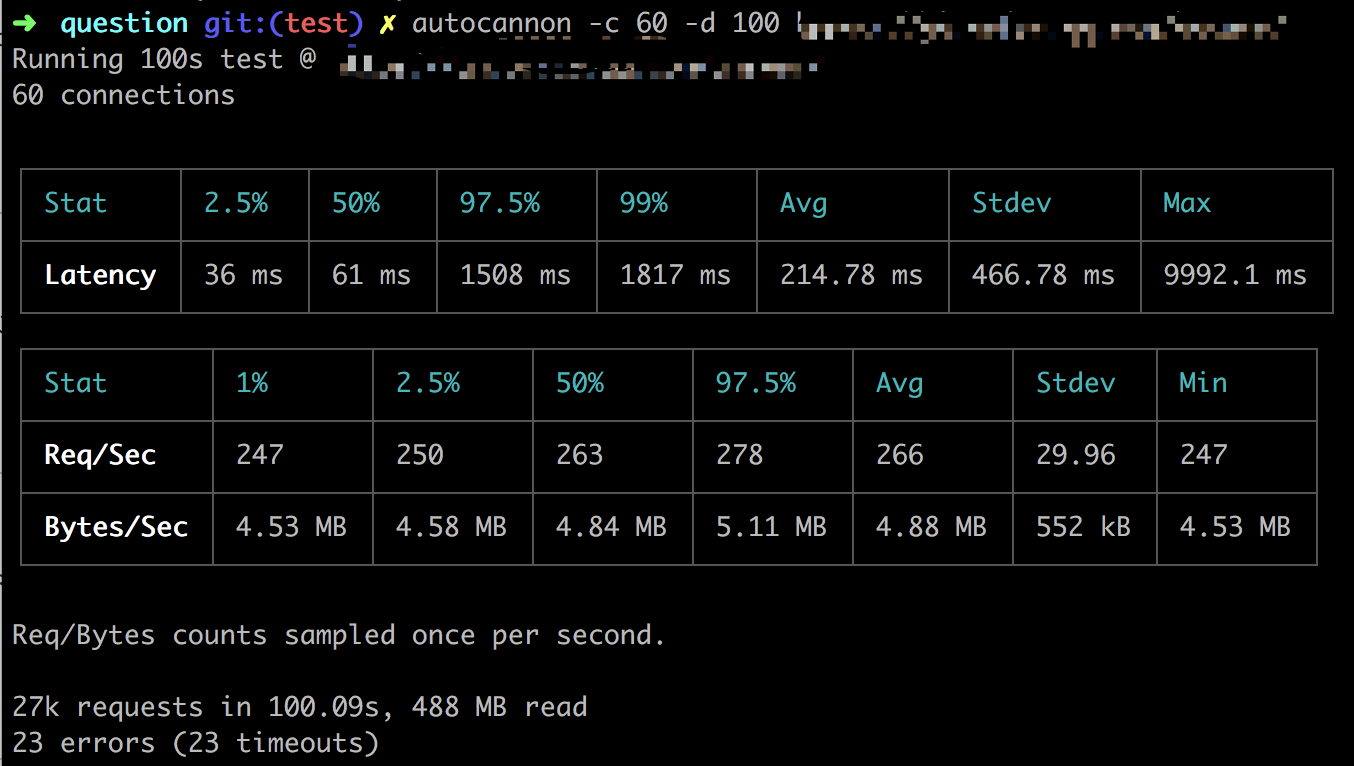
从图片中可以看到,每秒 60 的并发请求量时,QPS 平均有 266 左右,不过还有 23 个请求超时了,响应时间还可以,99%的请求在 1817ms 毫秒内完成。就目前这几项数据来看,数据处理能力并不理想,我们还有很大的提升空间。
2. 解决方案
针对上面压测出来的数据不理想,我们这里需要采取一些措施了。

2.1 内存管理
我们现在写纯前端时,几乎已经很少关注内存的使用了,毕竟在前端发展的过程中,内存的垃圾回收机制相对来说比较完善,而且前端页面的生存周期比较短。如果真是要特别注意的话,也是早期在 IE 浏览器中,js 与 dom 的交互过程中可能会产生内存的泄露。而且如果真会真要是泄露的话,也只会影响当前终端的用户,其他的用户暂时不会受到影响。
而服务端则不同,所有用户都会访问当前运行的代码,只要程序有一丁点的内存泄露,在成千上万的访问量下,都会造成内存的堆积,垃圾无法回收,最终造成严重的内存泄露,并导致程序崩溃。为了预防内存泄露,我们在内存管理方面,主要三方面的内容:
- V8 引擎的垃圾回收机制;
- 造成内存泄露的原因;
- 如何检测内存泄露;
Node 将 JavaScript 的主要应用场景扩展到了服务器端,相应要考虑的细节也与浏览器端不同, 需要更严谨地为每一份资源作出安排。总的来说,内存在 Node 中不能随心所欲地使用,但也不是完全不擅长。
2.1.1 V8 引擎的垃圾回收机制
在 V8 中,主要将内存分为新生代和老生代两代。新生代的对象为存活时间比较短的对象,老生代中的对象为存活时间较长的或常驻内存的对象。
默认情况下,新生代的内存最大值在 64 位系统和 32 位系统上分别为 32 MB 和 16 MB。V8 对内存的最大值在 64 位系统和 32 位系统上分别为 1464 MB 和 732 MB。
为什么这样分两代呢?是为了最优的 GC 算法。新生代的 GC 算法 Scavenge 速度快,但是不合适大数据量;老生代针使用 Mark-Sweep(标记清除) & Mark-Compact(标记整理) 算法,合适大数据量,但是速度较慢。分别对新旧两代使用更适合他们的算法来优化 GC 速度。
2.1.2 内存泄露的原因
内存泄露的情况有很多,例如内存当缓存、队列、重复的事件监听等。
内存当缓存这种情况中,通常有用一个变量来缓存数据,然后没有过期时间,一直填充数据,例如下面一个简单的例子:
let cached = new Map();
server.get('*', (req, res) => {
if (cached.has(req.url)) {
return cached.get(req.url);
}
const html = app.render(req, res);
cached.set(req.url, html);
res.send(html);
});
除此之外,还有闭包也是其中的一种情况。这种使用内存的不好的地方是,它没有可用的过期策略,只会让数据越来越多,最终造成内存泄露。更好的方式使用第三方的缓存机制,例如 redis、memcached 等,这些都有良好的过期和淘汰策略。
同时,也有一些队列方面的处理,例如有些日志的写入操作,当海量的数据需要写入时,就会造成队列的堆积。这时,我们设置队列的超时策略和拒绝策略,让一些操作尽快地释放掉。
再一个就是事件的重复监听。例如对同一个事件重复监听,忘记移除(removeListener),将造成内存泄漏。这种情况很容易在复用对象上添加事件时出现,所以事件重复监听可能收到如下警告:

Warning: Possible EventEmitter memory leak detected. 11 /question listeners added。Use emitter。setMaxListeners() to increase limit
2.1.3 排查的手段
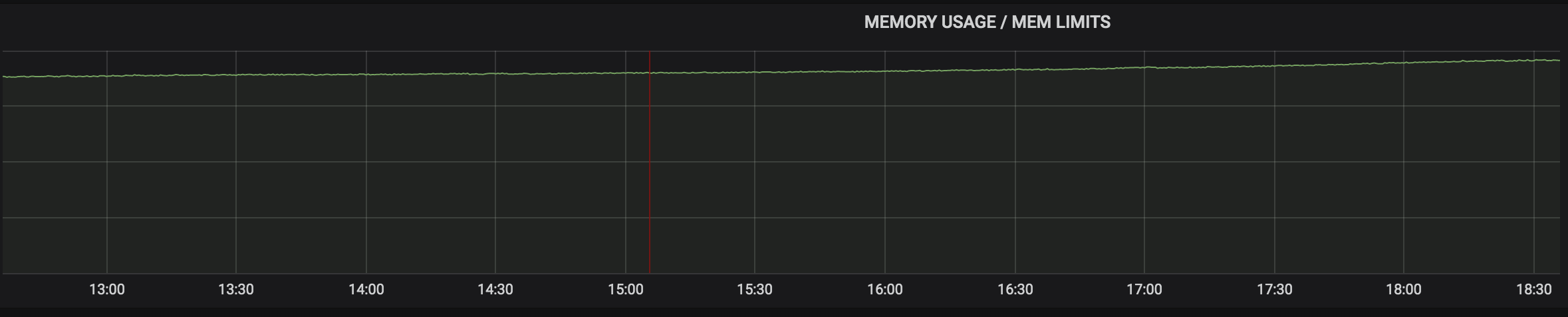
我们从内存的监控图中可以看到,在用户量基本保持不变的情况下,内存是一直在缓慢上涨,说明我们产生了内存泄露,使用的内存并没有被释放掉。
这里我们可以通过node-heapdump等工具来进行判断,或者稍微简单点,使用--inspect命令实现:
node --inspect server.js
然后打开 chrome 链接chrome://inspect来查看内存的使用情况。
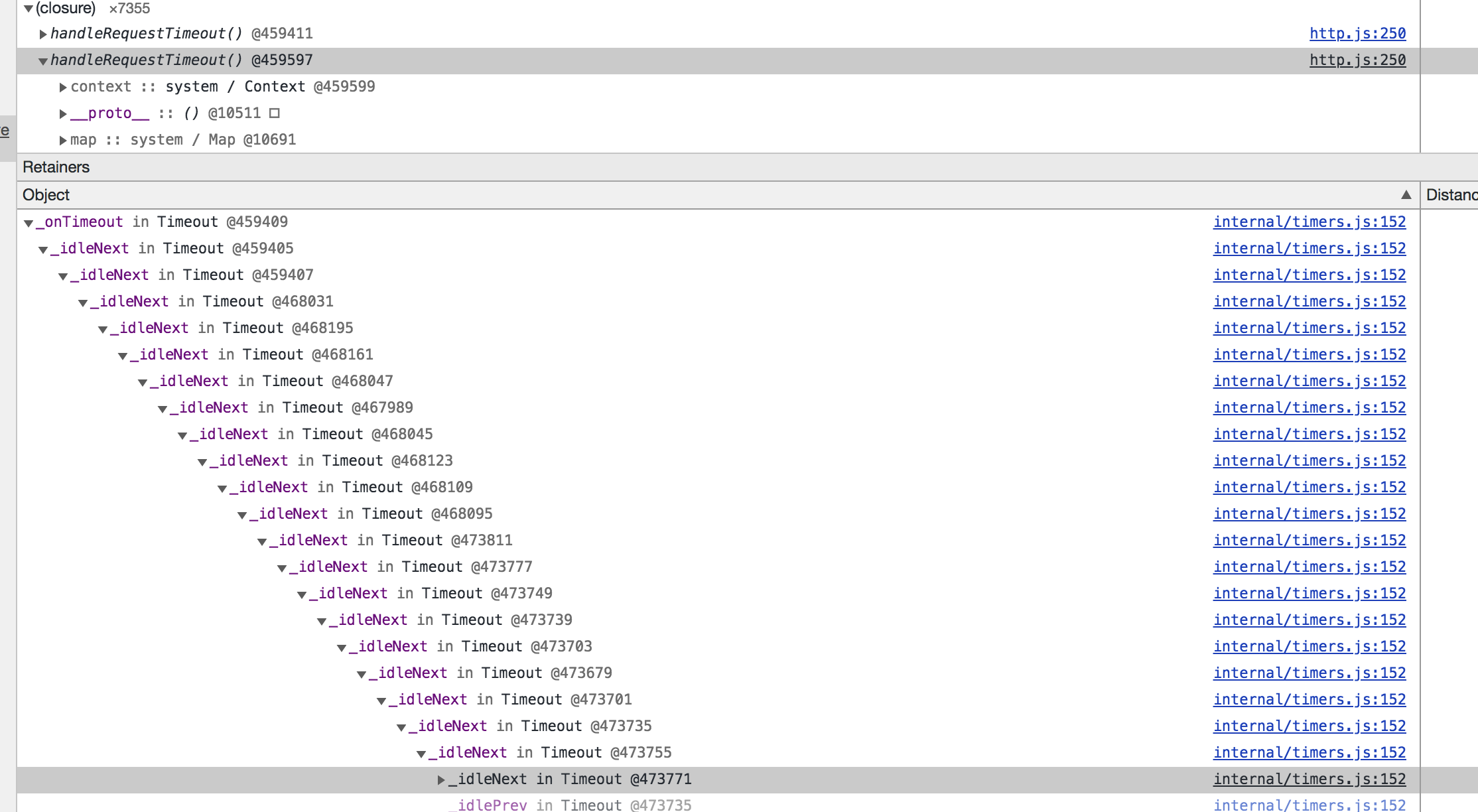
通过两次的内存抓取对比发现,handleRequestTimeout()方法一直在产生,且每个 handle 方法中有无数个回调,资源无法被释放。
通过定位查看使用的 axios 代码是:
if (config.timeout) {
timer = setTimeout(function handleRequestTimeout() {
req.abort();
reject(createError('timeout of ' + config.timeout + 'ms exceeded', config, 'ECONNABORTED', req));
}
}
这里代码看起来是没任何问题的,这是在前端处理中一个很典型的超时处理解决方式。
由于 Nodejs 中,io 的链接会阻塞 timer 处理,因此这个 setTimeout 并不会按时触发,也就有了 10s 以上才返回的情况。
貌似问题解决了,巨大的流量和阻塞的 connection 导致请求堆积,服务器处理不过来,CPU 也就下不来了。
通过定位并查看axios 的源码:
if (config.timeout) {
// Sometime, the response will be very slow, and does not respond, the connect event will be block by event loop system.
// And timer callback will be fired, and abort() will be invoked before connection, then get "socket hang up" and code ECONNRESET.
// At this time, if we have a large number of request, nodejs will hang up some socket on background. and the number will up and up.
// And then these socket which be hang up will devoring CPU little by little.
// ClientRequest.setTimeout will be fired on the specify milliseconds, and can make sure that abort() will be fired after connect.
req.setTimeout(config.timeout, function handleRequestTimeout() {
req.abort();
reject(
createError(
'timeout of ' + config.timeout + 'ms exceeded',
config,
'ECONNABORTED',
req
)
);
});
}
额,我之前使用的版本比较早,跟我本地使用的代码不一样,说明是更新过了,再查看这个文件的9 月 16 日的改动历史:
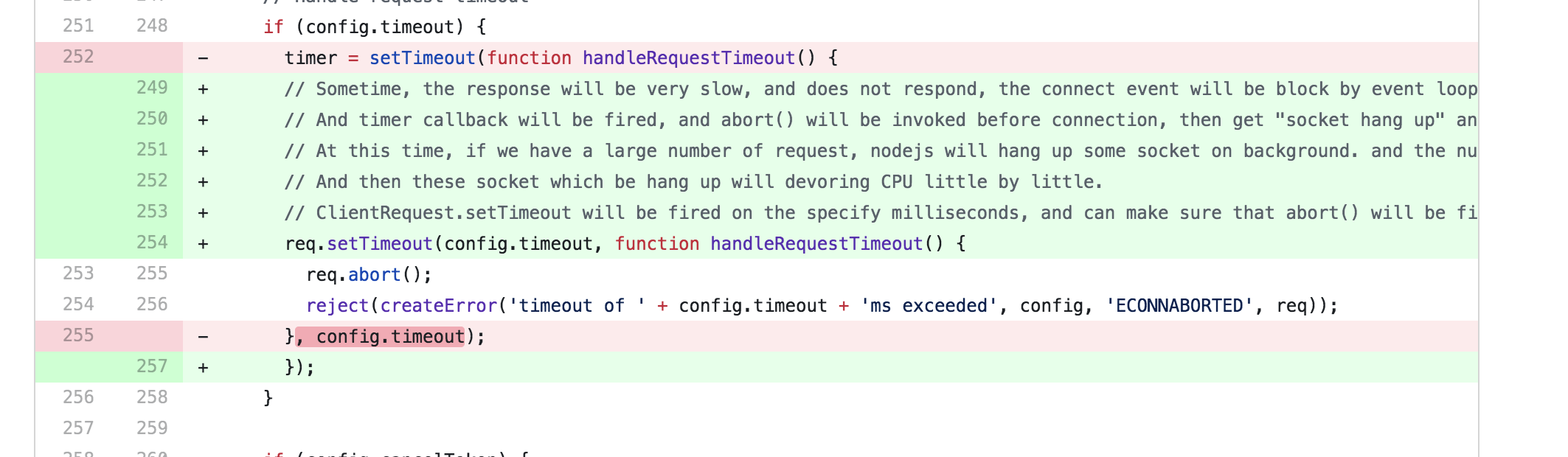
这里我们就需要把 axios 更新到最新的版本了。而且经过本地大量测试,发现在高负载下 CPU 和内存都在正常范围内了。
2.2 缓存
缓存真是性能优化的一把好手,服务不够,缓存来凑。不过缓存的类型有很多种,我们应当根据项目的实际情况,合理地选择使用缓存的策略。这里我们使用了 3 层的缓存策略。
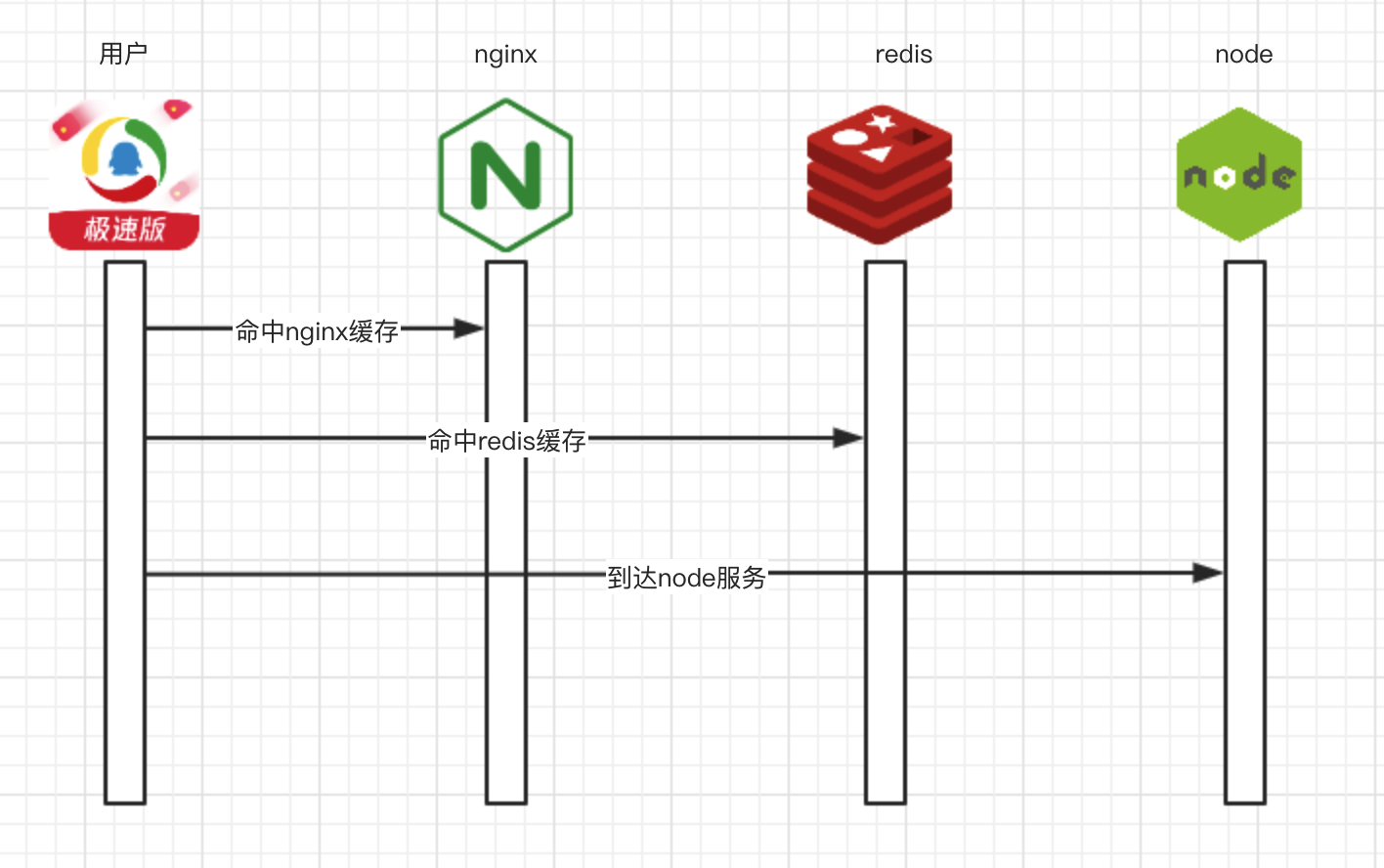
在 nginx 中,可以使用 proxy_cache 设置要缓存的路径和缓存的时间,同时可以启用proxy_cache_lock。
当 proxy_cache_lock 被启用时,当多个客户端请求一个缓存中不存在的文件(或称之为一个 MISS),只有这些请求中的第一个被允许发送至服务器。其他请求在第一个请求得到满意结果之后在缓存中得到文件。如果不启用 proxy_cache_lock,则所有在缓存中找不到文件的请求都会直接与服务器通信。
不过这个字段的启用也要非常慎重,当访问量过大时,会造成请求的堆积,必须等待第一个请求返回完成后,才能处理后面的请求。
proxy_cache_path /data/cached keys_zone=answer:16m levels=1:2 inactive=60m;
server {
location / {
proxy_cache answer;
proxy_cache_valid 1m;
}
}
在业务层面,我们可以启用 redis 缓存,来缓存整个页面、页面的某个部分或者接口等等,当穿透 nginx 缓存时,可以启用 redis 缓存。使用第三方缓存的特点我们在之前的文章也说了:多个进程之间可以共享,同时减少项目本身对缓存淘汰算法的处理。
当前面的两层缓存失效时,进入到我们的 node 服务层。二层的缓存机制,能实现不同的缓存策略和缓存粒度,业务需要根据自身场景, 选用适合自己业务的缓存即可。
3. 效果
这时我们项目的性能怎样了呢?
autocanon -c 1000 -d 100
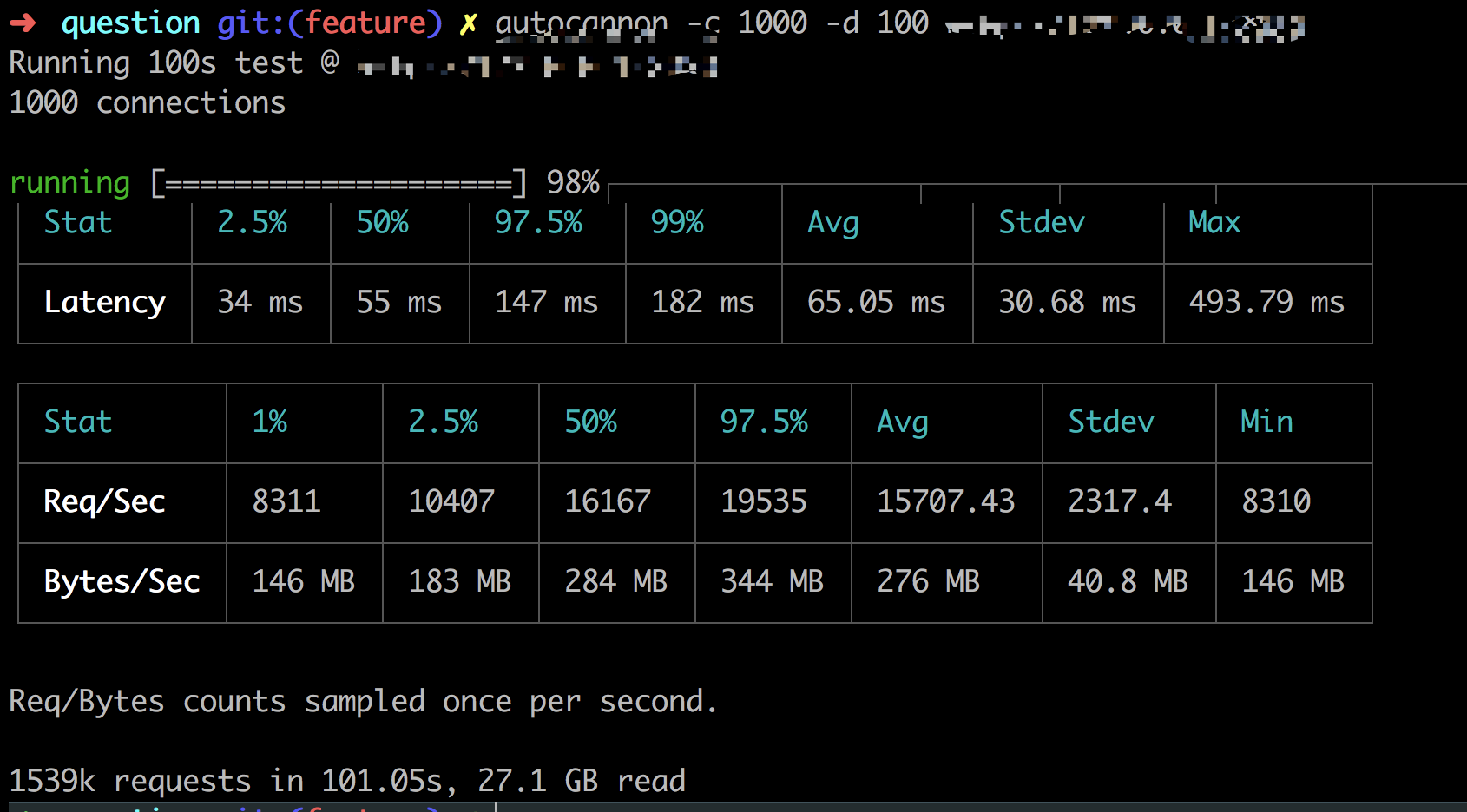
从图片里可以看到,99%的请求在182ms内完成,每秒平均处理的请求有15707左右,相比我们最开始只能处理200多个请求,性能足足提升了60倍多。
相关阅读:
我的博客原文地址:https://www.xiabingbao.com/post/node/node-high-performance.html
来自腾讯的前端开发工程师,与你分享前端快乐:wenzichel
