背景
在推荐系统中存在用户行为稀疏的问题,特别是在召回阶段,用户有过交互的item只占非常少的一部分,只有这部分数据我们能用来训练,但是serving时要serving全库item,这可能会导致倾向热门的item,特别是对冷启动非常不友好。这篇论文引入来在CV、NLU中取得成功的对比学习方法,通过一个辅助任务来帮助主任务模型和底层embedding得到更充分的训练。
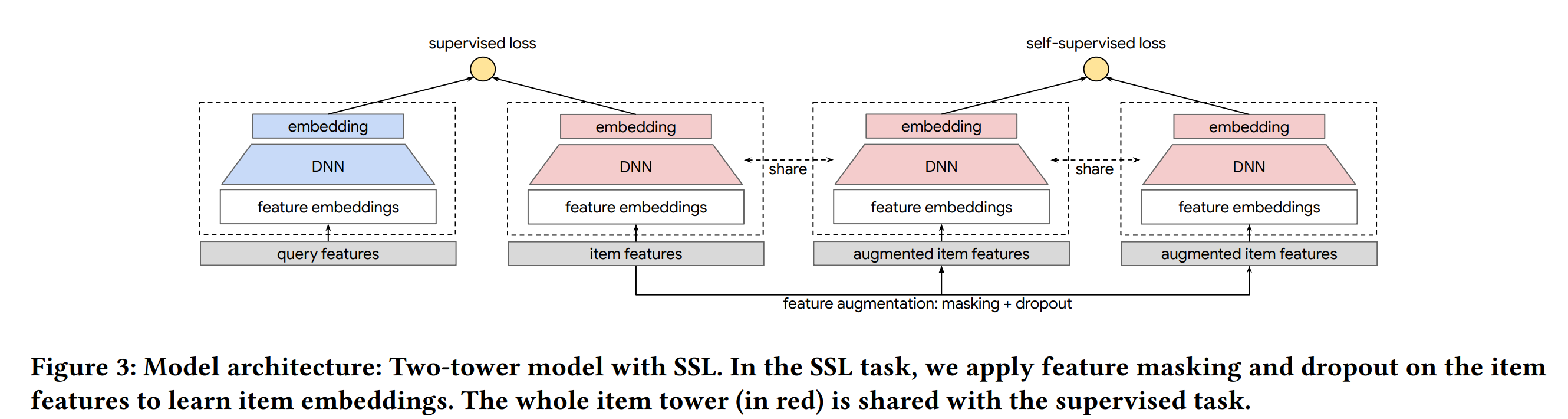
方法
这篇论文的重点就在于辅助任务的样本是如何构造的?损失函数是如何设计的?
辅助任务样本的构造方法(论文中也被称为数据增强)
主要的步骤就是 mask + dropout
对于一个样本我们会mask掉它的部分embedding,然后随机dropout掉部分embedding,这两步操作可以看作样本的一次变换
同个样本经过不同变换得到的两个样本构成正例
不同样本经过不同变换得到的两个样本构成负例
在这里有两种mask方法:
1. 随机mask
2. 线随机选取一个feature,然后选取和它互信息最大的一半feature一起mask
损失函数设计方法
我们会在一个batch内计算损失,最大化同个样本经过不同变换后得到的两个样本之间的余弦距离,最小化不同样本经过不同变换后得到的两个样本之间的余弦距离

联合训练
论文中会把这个主任务和辅助任务一块训练,损失函数是:

主任务和辅助任务可以共享部分/全部 embedding 和 nn 参数