一、概述
XML全称为可扩展的标记语言。主要用于描述数据和用作配置文件。
XML文档在逻辑上主要由一下5个部分组成:
- XML声明:指明所用XML的版本、文档的编码、文档的独立性信息
- 文档类型声明:指出XML文档所用的DTD
- 元素:由开始标签、元素内容和结束标签构成
- 注释:以<!--开始,以-->结束,用于对文档中的内容起一个说明作用
- 处理指令:通过处理指令来通知其他应用程序来处理非XML格式的数据,格式为<?xml-stylesheet href="hello.css" type="text/css"?>
XML文档的根元素被称为文档元素,它和在其外部出现的处理指令、注释等作为文档实体的子节点,根元素本身和其内部的子元素也是一棵树。
二、XML文档解析
在解析XML文档时,通常是利用现有的XML解析器对XML文档进行分析,应用程序通过解析器提供的API接口得到XML数据。

XML解析方式分为两种:DOM和SAX:
DOM:用来解析相对较小的XML文件,容易增删改查。DOM的核心是节点,DOM在解析XML文档时,将组成文档的各个部分映射为一个对象,这个对象就叫做节点。使用DOM解析XML文档,需要将读入整个XML文档,然后在内存中创建DOM树,生成DOM树上的每个节点对象。
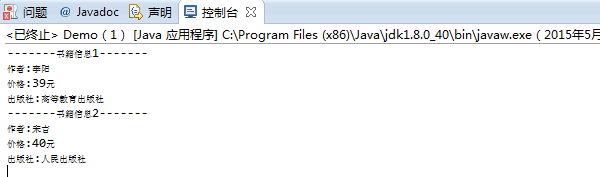
<?xml version="1.0" encoding="UTF-8"?> <书架> <书> <作者>李阳</作者> <价格>39元</价格> <出版社>高等教育出版社</出版社> </书> <书> <作者>宋吉</作者> <价格>40元</价格> <出版社>人民出版社</出版社> </书> </书架>
使用DOM解析上述XML文档,代码如下:
package com.test.xml; import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class Demo { public static void main(String args[]) { //得到DOM解析器工厂类的实例 DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance(); try { //得到dom的解析器对象 DocumentBuilder db=dbf.newDocumentBuilder(); //解析XML文档,得到代表文档的document对象 File file=new File("D:\Eclipse\workSpace\day_050401\src\book.xml"); Document doc=db.parse(file); //以文档顺序返回标签名字为书的所有后代元素 NodeList nl=doc.getElementsByTagName("书"); for(int i=0;i<nl.getLength();i++) { Element elt=(Element) nl.item(i); Node eltAuthor=elt.getElementsByTagName("作者").item(0); Node eltPricer=elt.getElementsByTagName("价格").item(0); Node eltPublish=elt.getElementsByTagName("出版社").item(0); String Author=eltAuthor.getFirstChild().getNodeValue(); String Pricer=eltPricer.getFirstChild().getNodeValue(); String Publish=eltPublish.getFirstChild().getNodeValue(); System.out.println("-------书籍信息"+(i+1)+"-------"); System.out.println("作者:"+Author); System.out.println("价格:"+Pricer); System.out.println("出版社:"+Publish); } } catch (ParserConfigurationException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } catch (SAXException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } catch (IOException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } } }
执行结果如下:
SAX:内存消耗较小,适合读取操作。SAX是一种基于事件驱动的API,利用SAX解析XML文档涉及解析器和事件处理器两个部分。解析器负责读取XML文档,并向事件处理器发送事件,事件处理器则负责对事件作出相应,对传递的XML数据进行处理。
使用SAX解析XML文档,代码如下:
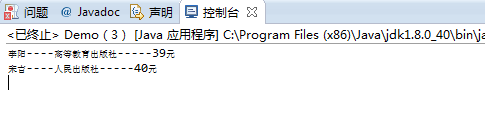
import java.io.File; import java.io.IOException; import java.util.ArrayList; import java.util.List; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.XMLReader; import org.xml.sax.helpers.DefaultHandler; class Book { private String name; private String author; private String price; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } public String getPrice() { return price; } public void setPrice(String price) { this.price = price; } } public class Demo extends DefaultHandler { private List list=new ArrayList(); private String currentTag; private Book book; @Override public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException { currentTag=name; if("书".equals(currentTag)) { book=new Book(); } } @Override public void characters(char[] ch, int start, int length) throws SAXException { if("出版社".equals(currentTag)) { String name=new String(ch,start,length); book.setName(name); } if("作者".equals(currentTag)) { String author=new String(ch,start,length); book.setAuthor(author); } if("价格".equals(currentTag)) { String price=new String(ch,start,length); book.setPrice(price); } } @Override public void endElement(String uri, String localName, String name) throws SAXException { if(name.equals("书")) { list.add(book); book=null; } currentTag=null; } public List getBooks() { return list; } public static void main(String []args) { //1.创建解析工厂 SAXParserFactory factory=SAXParserFactory.newInstance(); SAXParser sp=null; try { //2.得到解析器 sp=factory.newSAXParser(); //3、得到读取器 XMLReader reader=sp.getXMLReader(); File file=new File("D:\Eclipse\workSpace\day_050401\src\book.xml"); //4.设置内容处理器 Demo handle=new Demo(); //reader.setContentHandler(handle); sp.parse(file,handle); //5.读取xml文档内容 List<Book> list=handle.getBooks(); for(int i=0;i<list.size();i++) System.out.println(list.get(i).getAuthor()+"----"+list.get(i).getName()+"-----"+list.get(i).getPrice()); } catch (ParserConfigurationException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } catch (SAXException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } catch (IOException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } } }
运行结果如下:
三、dom4j解析XML文档
dom4j也是一种用于解析XML文档的开放源代码的Java库。下载地址http://sourceforge.net/projects/dom4j/。
使用dom4j进行读取XMl文档操作,代码如下:
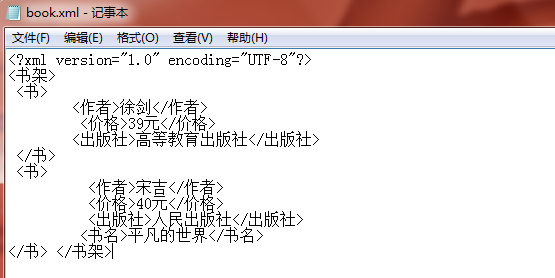
import java.io.FileOutputStream; import java.io.FileWriter; import java.io.IOException; import java.io.OutputStreamWriter; import java.security.KeyStore.Entry.Attribute; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; import org.junit.Test; public class Demo { //读取xml文件第二本书的出版社 @Test public void read() { SAXReader reader = new SAXReader(); try { Document document = reader.read("C:\Users\Administrator\Desktop\book.xml"); Element root =document.getRootElement(); Element book=(Element)root.elements("书").get(1); String value=book.element("出版社").getText(); System.out.println(value); } catch (DocumentException e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } } //在第二本书上添加一个书名:<书名>平凡的世界</书名> @Test public void add() throws DocumentException, IOException { SAXReader reader = new SAXReader(); Document document = reader.read("C:\Users\Administrator\Desktop\book.xml"); Element book=(Element) document.getRootElement().elements("书").get(1); book.addElement("书名").setText("平凡的世界"); //更新内存 XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream("C:\Users\Administrator\Desktop\book.xml"),"UTF-8")); writer.write(document); writer.close(); } }
运行结果:
PS:如果你的项目经常需要更换解析器,建议使用DOM和SAX,这样当更换解析器时不需要更改任何代码,如果没有这样的需求,建议使用dom4j,简单而又强大。