Flume NG高可用集群搭建:
架构总图:
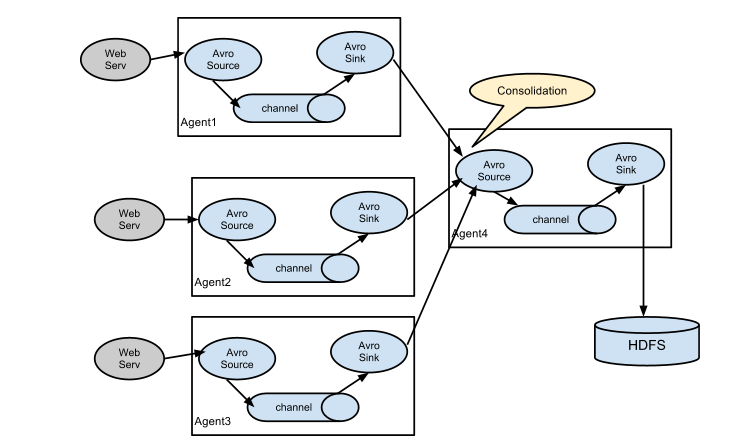
架构分配:
|
角色 |
Host |
端口 |
|
agent1 |
hadoop3 |
52020 |
|
collector1 |
hadoop1 |
52020 |
|
collector2 |
hadoop2 |
52020 |
agent1配置(flume-client.conf):
#agent1 name agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2 #set gruop agent1.sinkgroups = g1 #set channel agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /home/sky/flume/log_exec_tail agent1.sources.r1.interceptors = i1 i2 agent1.sources.r1.interceptors.i1.type = static agent1.sources.r1.interceptors.i1.key = Type agent1.sources.r1.interceptors.i1.value = LOGIN agent1.sources.r1.interceptors.i2.type = timestamp # set sink1 agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = hadoop1 agent1.sinks.k1.port = 52020 # set sink2 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = hadoop2 agent1.sinks.k2.port = 52020 #set sink group agent1.sinkgroups.g1.sinks = k1 k2 #set failover agent1.sinkgroups.g1.processor.type = failover agent1.sinkgroups.g1.processor.priority.k1 = 10 agent1.sinkgroups.g1.processor.priority.k2 = 1 agent1.sinkgroups.g1.processor.maxpenalty = 10000
collector1配置(flume-server.conf):
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1 #set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = hadoop1 a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = hadoop1 a1.sources.r1.channels = c1 #set sink to hdfs a1.sinks.k1.type=logger a1.sinks.k1.channel=c1
collector2配置(flume-server.conf):
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1 #set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = hadoop2 a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = hadoop2 a1.sources.r1.channels = c1 #set sink to hdfs a1.sinks.k1.type=logger a1.sinks.k1.channel=c1
先启动server,在启动client:
flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-server.conf --name a1 -Dflume.root.logger=INFO,console
flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-client.conf --name agent1 -Dflume.root.logger=INFO,console
测试验证:
hadoop1收到了hadoop3的消息了,哈哈。hadoop2没有收到消息,那是因为hadoop1的priority高。
hadoop3:

hadoop1:

hadoop2:

再次测试Failover:
停掉hadoop1的Flume,再次在hadoop3发送数据。可见hadoop3的Flume报错重连了,并且hadoop2收到了数据。如果再次启动hadoop1的Flume,一切又会恢复到hadoop1接收。
hadoop3:


hadoop2:

这样测试就完毕了。Flume高可用集群就搭建好了!