No.1. 数据归一化的目的
数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用。
No.2. 数据归一化的方法
数据归一化的方法主要有两种:最值归一化和均值方差归一化。
最值归一化的计算公式如下:

最值归一化的特点是,可以将所有数据都映射到0-1之间,它适用于数据分布有明显边界的情况,容易受到异常值(outlier)的影响,异常值会造成数据的整体偏斜。
均值方差归一化的计算公式如下:
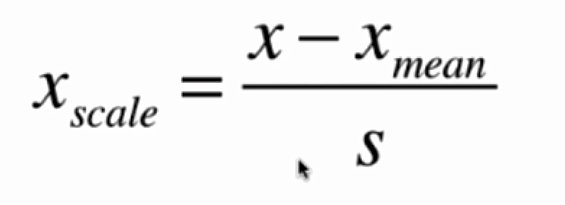
均值方差归一化的特点是,可以将数据归一化到均值为0方差为1的分布中,不容易受到异常值(outlier)影响。
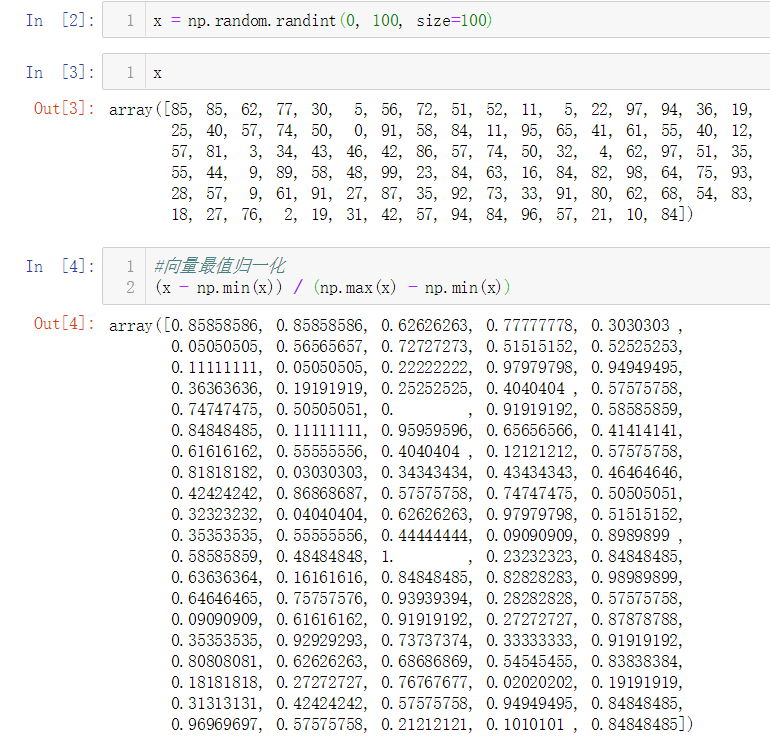
No.3. 向量和矩阵的最值归一化
向量的最值归一化
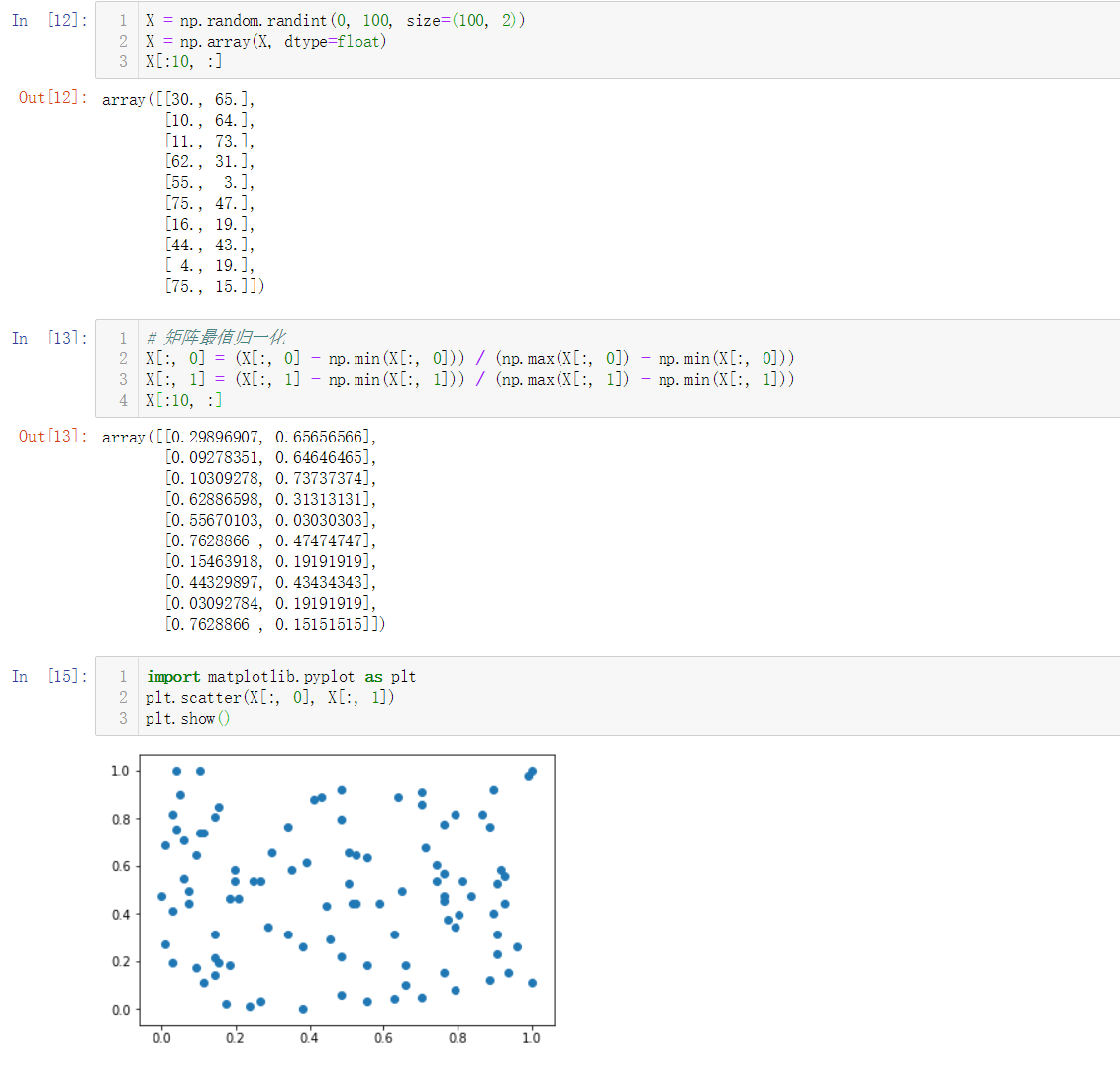
矩阵的最值归一化
No.4. 向量和矩阵的均值方差归一化
向量的均值方差归一化
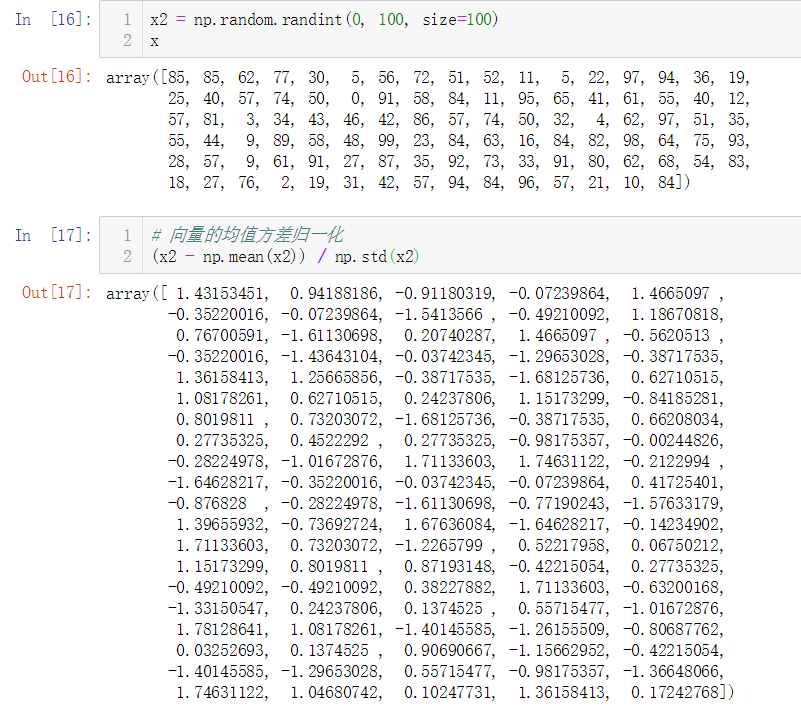
矩阵的均值方差归一化
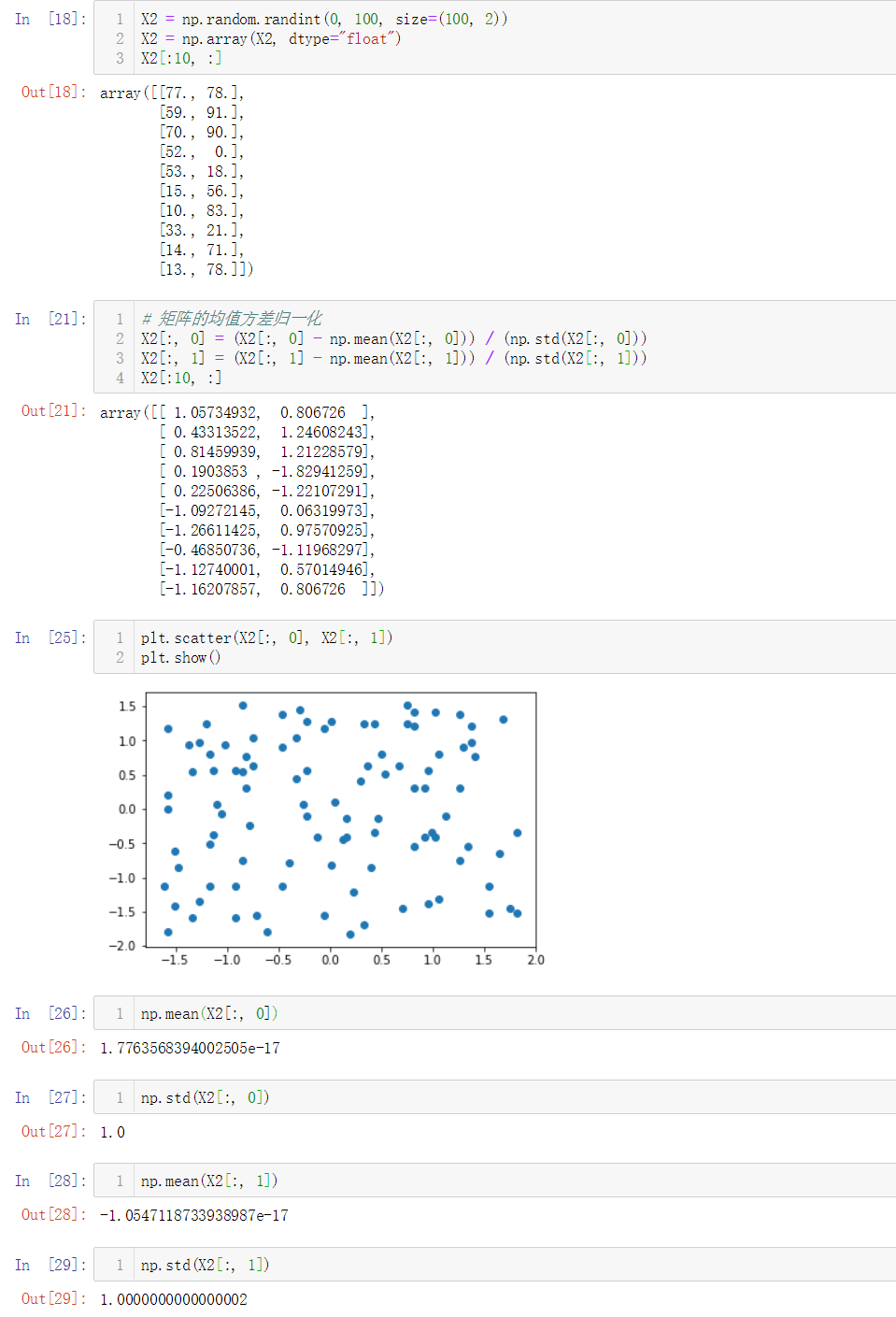
No.5. sklearn中对数据集归一化的流程
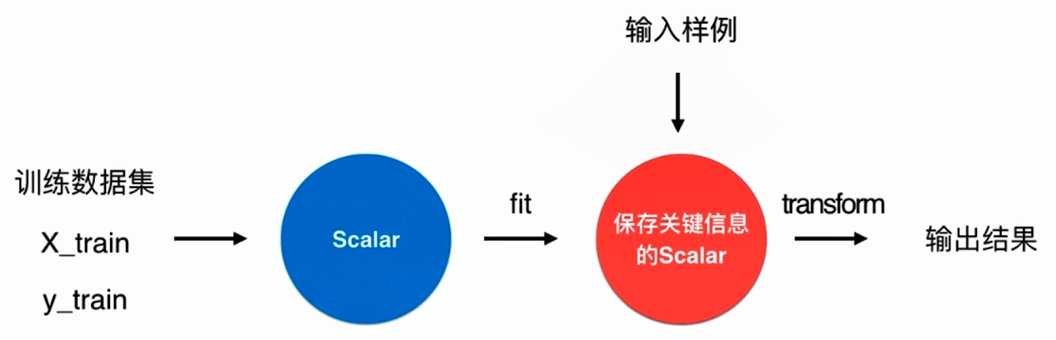
No.6. 使用鸢尾花数据集进行数据归一化
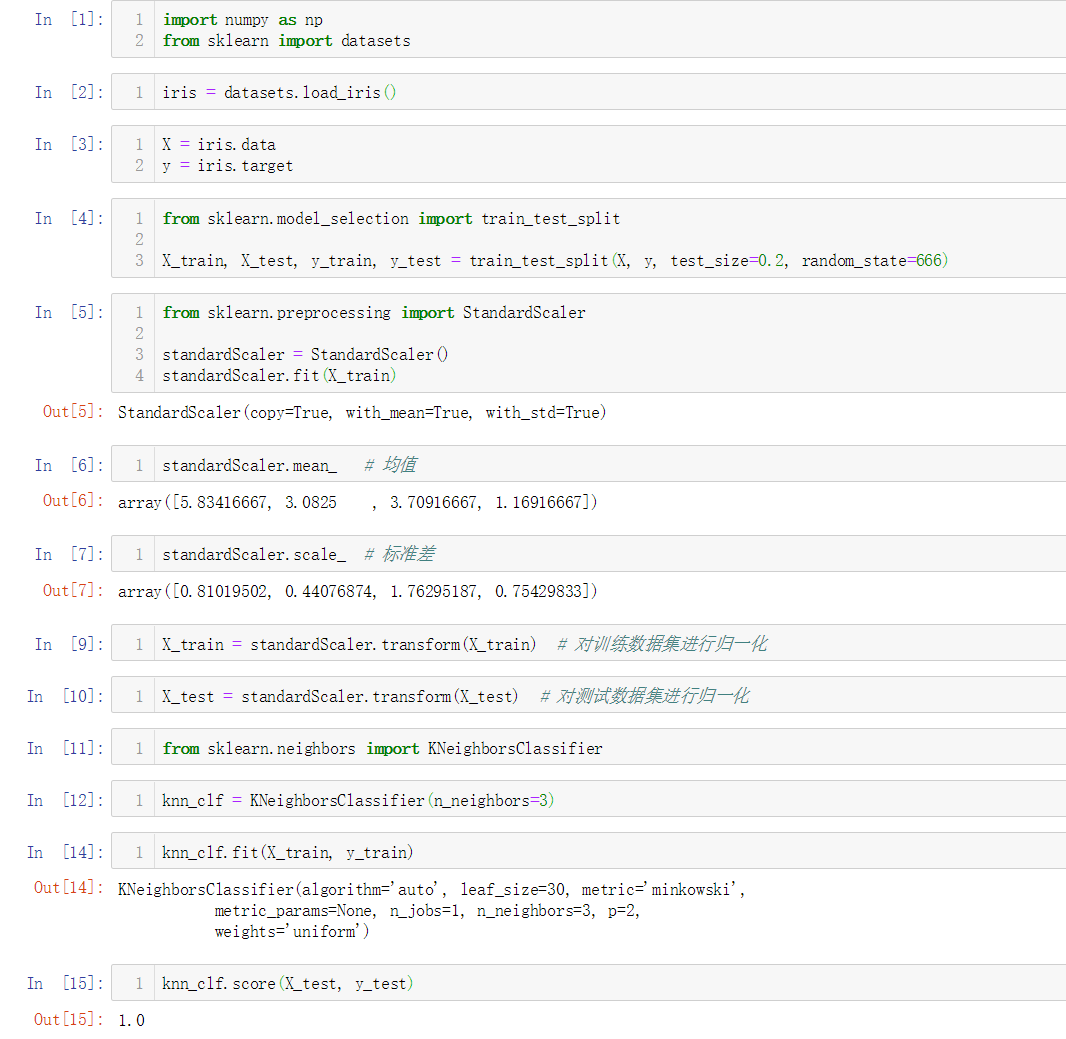
No.7. 简单实现一个自己的StandardScaler类

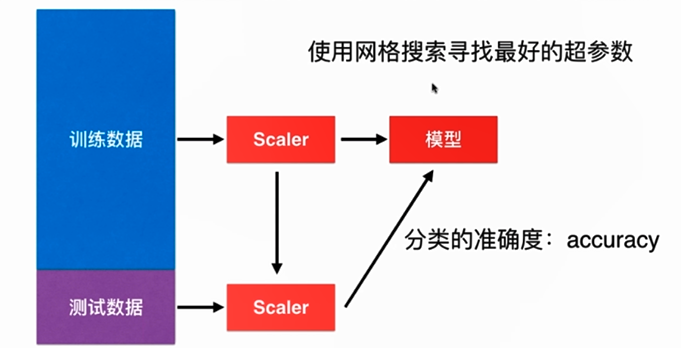
No.8. 机器学习流程回顾:
首先我们需要将数据集分成训练数据集和测试数据集两部分;对于kNN这种算法,我们需要保证数据在同一尺度下,因此要进行数据的归一化,训练数据集通过一个Scaler进行数据的归一化;将归一化后的数据进行训练,训练过程中要使用网格搜索来寻找最好的超参数,训练后得到最终的模型;之后,对于测试数据集,需要使用相同的Scaler进行归一化,然后送进用训练数据集得到的模型,得到模型分类的准确度,这样就可以确定训练数据集得到的模型的优劣。